







 本文详细介绍了机器学习中常用的几种算法,包括KNN、逻辑回归、朴素贝叶斯、决策树、集成思想(如随机森林和AdaBoost)。KNN算法简单但计算复杂度高,逻辑回归适用于二分类问题,朴素贝叶斯基于贝叶斯定理,决策树易于理解和实现,而集成思想通过组合多个模型提高预测性能。每种算法都有其独特优缺点,适用于不同的问题场景。
本文详细介绍了机器学习中常用的几种算法,包括KNN、逻辑回归、朴素贝叶斯、决策树、集成思想(如随机森林和AdaBoost)。KNN算法简单但计算复杂度高,逻辑回归适用于二分类问题,朴素贝叶斯基于贝叶斯定理,决策树易于理解和实现,而集成思想通过组合多个模型提高预测性能。每种算法都有其独特优缺点,适用于不同的问题场景。
KNN
核心思想是:
物以类聚,人以群分
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
假设一个未知样本数据x需要归类,总共有ABC三个类别,那么离x距离最近的有k个邻居,这k个邻居里有k1个邻居属于A类,k2个邻居属于B类,k3个邻居属于C类,如果k1>k2>k3,那么x就属于A类,也就是说x的类别完全由邻居来推断出来
算法步骤为:
1、计算测试对象到训练集中每个对象的距离
2、按照距离的远近排序
3、选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
4、统计这k个邻居的类别频率
5、k个邻居里频率最高的类别,即为测试对象的类别
KNN算法的优缺点
1、优点
非常简单的分类算法没有之一,人性化,易于理解,易于实现
适合处理多分类问题,比如推荐用户
2、缺点
属于懒惰算法,时间复杂度较高,因为需要计算未知样本到所有已知样本的距离
样本平衡度依赖高,当出现极端情况样本不平衡时,分类绝对会出现偏差
可解释性差,无法给出类似决策树那样的规则
向量的维度越高,欧式距离的区分能力就越弱
逻辑回归
1.1 什么是逻辑回归
逻辑回归(LR)名义上带有“回归”字样,第一眼看去有可能会被以为是预测方法,其实质却是一种常用的分类模型,主要被用于二分类问题,它将特征空间映射成一种可能性,在LR中,y是一个定性变量{0,1},LR方法主要用于研究某些事发生的概率。
假定有一个二分类问题,输出y∈{0,1}y∈{0,1},线性回归模型(公式1.1.1)
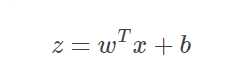
SigmoidFunctionS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









