




有监督
一、线性回归(Linear Regression)
1. 算法原理
线性回归(Linear Regression)是一种基本的回归算法,它通过拟合一个线性模型来预测连续型目标变量。线性回归模型的基本形式是:y = w1 * x1 + w2 * x2 + … + wn * xn + b,其中y是目标变量,x1到xn是特征,w1到wn是模型参数(权重),b是截距项。线性回归的目标是找到一组权重和截距,使得预测值与实际值之间的误差最小。为了实现这一目标,线性回归使用了最小二乘法(Least Squares Method)来最小化预测值与实际值之间的平方误差。
2.优缺点
优点:
a) 算法简单,容易理解和实现。
b) 计算复杂度低,训练速度快。
c) 可解释性强,模型参数有直观的物理意义。
d) 可以通过正则化方法(如Lasso和Ridge)来避免过拟合。
3.缺点:
a) 线性回归假设特征与目标之间存在线性关系,对于非线性关系的数据拟合效果较差。
b) 对异常值(outliers)敏感,异常值可能导致模型拟合效果较差。
c) 对多重共线性问题(特征间高度相关)敏感,可能导致模型不稳定。
3.适用场景
4.适用场景:
a) 预测连续型目标变量,如房价、销售额等。
b) 数据特征与目标变量之间存在线性关系或近似线性关系。
c) 数据量较大,需要快速训练模型时。
d) 需要对模型进行解释时,例如分析各个特征对目标变量的贡献程度。
总之,线性回归是一种简单有效的回归算法,在实际应用中具有较广泛的适用性。然而,当数据之间存在非线性关系或者特征之间存在多重共线性时,线性回归的表现可能会受到影响。在这种情况下,可以考虑使用其他更复杂的回归方法。
二、逻辑回归(Logistic Regression)
1. 算法原理
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的线性模型。虽然它的名字中包含“回归”,但实际上它是一种分类算法。逻辑回归通过sigmoid函数(S型函数)将线性模型的输出转换为概率值,用于表示数据属于某一类的概率。sigmoid函数的公式为:f(z) = 1 / (1 + exp(-z))。逻辑回归模型的目标是找到一组权重和截距,使得预测的概率与实际标签之间的误差最小。为了实现这一目标,逻辑回归使用了极大似然估计(Maximum Likelihood Estimation,MLE)来最大化观测数据的对数似然。
2.优缺点
2.优缺点
优点:
a) 算法简单,容易理解和实现。
b) 输出结果具有概率意义,方便进行概率估计和置信度分析。
c) 可以通过正则化方法(如L1和L2正则化)来避免过拟合。
d) 可解释性强,模型参数有直观的物理意义。
缺点:
a) 逻辑回归假设特征与目标之间存在线性关系,对于非线性关系的数据分类效果较差。
b) 对异常值敏感,异常值可能导致模型拟合效果较差。
c) 只能处理二分类问题,对于多分类问题需要进行扩展(如one-vs-rest或one-vs-one方法)。
3.适用场景
逻辑回归适用于以下场景:
a) 二分类问题,如垃圾邮件分类、客户流失预测等。
b) 数据特征与目标变量之间存在线性关系或近似线性关系。
c) 需要对模型进行解释时,例如分析各个特征对目标变量的贡献程度。
逻辑回归虽然简单,但在许多实际问题中表现出良好的分类性能。然而,当数据之间存在非线性关系时,可以考虑使用其他更复杂的分类方法。
三、支持向量机(svn)
1. 算法原理
支持向量机(Support Vector Machine,SVM)是一种广泛应用于分类和回归问题的机器学习算法。在分类问题中,SVM的目标是找到一个超平面,使得两个类别之间的间隔最大化。这个间隔被称为“最大间隔”,而支持向量机的名称来源于构成这个最大间隔边界的数据点,被称为“支持向量”。
为了解决非线性问题,支持向量机引入了核函数(Kernel Function)。核函数可以将原始特征空间映射到一个更高维度的特征空间,使得原本线性不可分的数据在新的特征空间中变得线性可分。常用的核函数包括:线性核、多项式核、高斯径向基核(Radial Basis Function,RBF)等。
2.优缺点
优点:
a) 在高维数据和小样本数据上表现良好。
b) 可以处理非线性问题,通过选择合适的核函数可以提高分类性能。
c) 具有稀疏性,只有支持向量对模型产生影响,降低了计算复杂度。
缺点:
a) 对于大规模数据集和高维数据,训练速度较慢。
b) 需要选择合适的核函数和调整核函数参数,对参数敏感。
c) 对于多分类问题需要进行扩展,如one-vs-rest或one-vs-one方法。
3.适用场景
支持向量机适用于以下场景:
a) 二分类问题,如手写数字识别、人脸识别等。
b) 数据量较小或中等规模的数据集。
c) 数据具有非线性关系或需要在高维空间进行分类。
支持向量机在许多实际问题中表现出良好的分类性能,尤其是在高维数据和小样本数据上。然而,在大规模数据集和高维数据上,训练速度较慢,可能需要考虑使用其他更高效的分类方法。
四、决策树(Decision Tree)
1. 算法原理
决策树(Decision Tree)是一种常见的机器学习算法,用于解决分类和回归问题。决策树以树状结构表示决策过程,通过递归地将数据集划分为不同的子集,每个子集对应于一个树节点。在每个节点上,根据特征值选择一个最佳的划分方式。常用的划分方式包括信息增益、信息增益比、基尼指数等。划分过程一直进行到达到预先设定的停止条件,如节点内的数据数量小于某个阈值或树的深度达到限制等。
2.优缺点
优点:
a) 模型具有良好的可解释性,容易理解和实现。 b) 可以处理缺失值和异常值,对数据的预处理要求较低。 c) 适用于多种数据类型,包括离散型和连续型特征。
缺点:
a) 容易产生过拟合现象,需要采用剪枝策略来防止过拟合。 b) 对于非线性关系的数据建模能力有限。 c) 决策树的构建过程可能受到局部最优解的影响,导致全局最优解无法达到。
3.适用场景
决策树适用于以下场景:
a) 数据具有混合类型的特征,如离散型和连续型。
b) 需要解释模型的决策过程,如信贷审批、医疗诊断等。
c) 数据集中存在缺失值或异常值。
决策树在很多实际应用中表现出较好的性能,尤其是在具有混合数据类型特征的问题中。然而,决策树容易过拟合,需要采用剪枝策略来防止过拟合,同时对非线性关系建模能力有限。在这种情况下,可以考虑使用随机森林等基于决策树的集成方法。
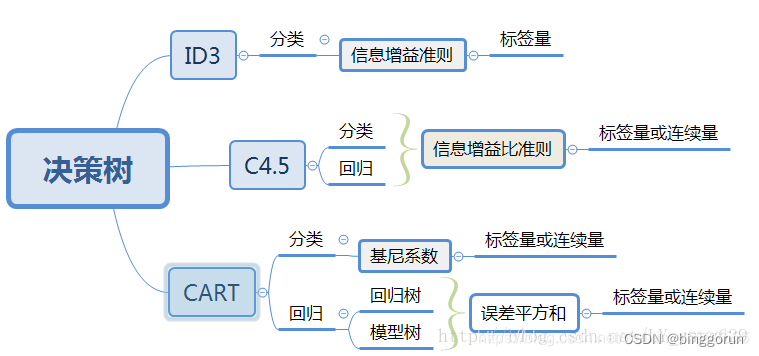
三大经典决策树算法最主要的区别是其特征选择的准则不同。ID3算法选择特征的依据是信息增益、C4.5是信息增益比,而CART则是基尼指数。作为一种基础的分类和回归方法,决策树可以有以下两种理解方法:可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6480
6480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









