




 本文详细探讨了各种激活函数在深度学习中的作用,包括Sigmoid、Tanh、ReLU、LeakyReLU、ELU、PReLU、SELU、Softmax等。这些函数各有特点,如Sigmoid用于二分类输出,ReLU解决梯度消失问题,Tanh以0为中心,而ELU和PReLU避免了Dead ReLU问题。Softmax用于多类分类,而GLU和Swish等新型函数进一步优化了梯度流动和网络训练效率。选择合适的激活函数取决于特定任务的需求和网络结构。
本文详细探讨了各种激活函数在深度学习中的作用,包括Sigmoid、Tanh、ReLU、LeakyReLU、ELU、PReLU、SELU、Softmax等。这些函数各有特点,如Sigmoid用于二分类输出,ReLU解决梯度消失问题,Tanh以0为中心,而ELU和PReLU避免了Dead ReLU问题。Softmax用于多类分类,而GLU和Swish等新型函数进一步优化了梯度流动和网络训练效率。选择合适的激活函数取决于特定任务的需求和网络结构。

为什么要引入激活函数?
1.模拟人类神经元的传递规则
2.限制每层之间的输出值范围
3.为神经网络引入非线性的能力
1 sigmoid激活函数
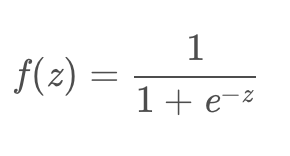
1.1 在什么情况下适合使用 Sigmoid 激活函数呢?
Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到1,因此它对每个神经元的输出进行了归一化;
用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid函数非常合适;
梯度平滑,避免「跳跃」的输出值;
函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
明确的预测,即非常接近 1 或 0。
1.2 Sigmoid 激活函数有哪些缺点?
倾向于梯度消失;
函数输出不是以 0 为中心的,这会降低权重更新的效率;
Sigmoid函数执行指数运算,计算机运行得较慢。
1.3 其他
1.3.1 Hard Sigmoid
是Logistic Sigmoid 激活函数的分段线性近似。
它更易计算,这使得学习计算的速度更快,尽管首次派生值为零可能导致静默神经元/过慢的学习速率。

1.3.2 Complementary Log Log函数
描述: 是Sigmoid的一种替代,相较于Sigmoid更饱和。
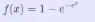
2 Tanh / 双曲正切激活函数
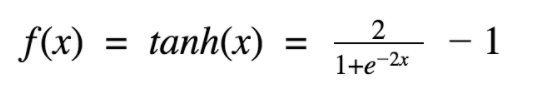
2.1 在什么情况下适合使用 Sigmoid 激活函数呢?
首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。
二者的区别在于输出间隔,tanh 的输出间隔为 1,并且整个函数以0 为中心,比 sigmoid 函数更好;
在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
2.2 tanh激活函数输出关于“零点”对称的好处是什么?
对于sigmoid函数而言,其输出始终为正,这会导致在深度网络训练中模型的收敛速度变慢,因为在反向传播链式求导过程中,权重更新的效率会降低(具体推导可以参考这篇文https://www.zhihu.com/question/50396271?from=profile_question_card)。
假如权重为二维,那么全为负的和全为正的权重相加分布在一三象限,因此会出现zigzag现象,导致收敛速度缓慢。
此外,sigmoid函数的输出均大于0,作为下层神经元的输入会导致下层输入不是0均值的,随着网络的加深可能会使得原始数据的分布发生改变。而在深度学习的网络训练中,经常需要将数据处理成零均值分布的情况,以提高收敛效率,因此tanh函数更加符合这个要求。
sigmoid函数的输出在[0,1]之间,比较适合用于二分类问题。
2.3 为什么RNN中常用tanh函数作为激活函数而不是ReLU
详细分析可以参考这篇文章。
为什么RNN中常用tanh函数作为激活函数而不是ReLU:
RNN中将tanh函数作为激活函数本身就存在梯度消失的问题,而ReLU本就是为了克服梯度消失问题而生的,那为什么不能直接(注意:这里说的是直接替代,事实上通过截断优化ReLU仍可以在RNN中取得很好的表现)用ReLU来代替RNN中的tanh来作为激活函数呢?这是因为ReLU的导数只能为0或1,而导数为1的时候在RNN中很容易造成梯度爆炸问题。因为在RNN中,每个神经元在不同的时刻都共享一个参数W,因此在前向和反向传播中,每个神经元的输出都会作为下一个时刻本神经元的输入,从某种意义上来讲相当于对其参数矩阵W作了连乘,如果W中有其中一个特征值大于1,则多次累乘之后的结果将非常大,自然就产生了梯度爆炸的问题。
那为什么ReLU在CNN中不存在连乘的梯度爆炸问题呢?,因为在CNN中,每一层都有不同的参数w,有的特征值大于1,有的小于1,在某种意义上可以理解为抵消了梯度爆炸的可能。
2.4 其他
2.4.1 Hard Tanh(分段近似Tanh函数)
描述: Tanh激活函数的分段线性近似。
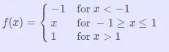
2.4.2 LeCun Tanh(也称Scaled Tanh,按比例缩放的Tanh函数)
描述: Tanh的缩放版本
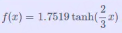
2.4.3 Symmetrical Sigmoid(对称Sigmoid函数)
描述: 是Tanh的一种替代方法,比Tanh形状更扁平,导数更小,下降更缓慢。
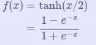
2.4.2 ArcTan(反正切函数)
描述: ArcTen从图形上看类似TanH函数,只是比TanH平缓,值域更大。从一阶导看出导数趋于零的速度比较慢,因此训练比较快。
2.4.3 softsign
描述: Softsign从图形上看也类似TanH函数,以0为中心反对称,训练比较快
Softsign 激活函数是一种Tanh 、Sigmoid 激活函数的替代,它通过应用阈值来重新缩放 -1 和 1 之间的值。其数学表达式和数学图像分别如下所示:
Softsign(x) = x / (1 + |x|)
3 ReLU 系列激活函数
ReLU 系列激活函数:Leaky ReLU、PReLU、RReLU 、CRelu、ReLU6、swish(SiLU)、SReLU
Leaky ReLU
PReLU (Parametric ReLU)
RReLU (随机ReLU)
CRelu
ReLU6
swish(SiLU)
SReLU
4 ELU系列激活函数:
ELU系列激活函数:ELU, SELU, GELU
ELU
SELU
GELU
5 补充激活函数
激活函数补充:Maxout、Softplus、Softmax、Bent identity、Sinusoid、Sinc函数、Gaussian、Absolute
Maxout
Softplus
Softmax
Bent identity(弯曲恒等函数)
Sinusoid(正弦函数)
Sinc函数
Gaussian
Absolute绝对值函数)
6 门控激活函数:
门控激活函数:GLU/GTU/Swish/HSwish/Mish/SwiGLU
GLU
GTU
Swish
HSwish
Mish
SwiGLU
7 如何选择激活函数
用于分类器时,二分类为Sigmoid,多分类为Softmax,这两类一般用于输出层;
对于长序列的问题,隐藏层中尽量避免使用Sigmoid和Tanh,会造成梯度消失的问题;
Relu在Gelu出现之前在大多数情况下比较通用,但也只能在隐层中使用;
现在2022年了,隐藏层中主要的选择肯定优先是Gelu、Swish了。

















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









