







 本文深入探讨了深度学习中的关键概念,包括模型流程、网络结构、过拟合与欠拟合的解决方案,以及卷积操作、BN层的作用。激活函数如ReLU与tanh的比较,以及它们在解决梯度消失问题中的角色。同时,介绍了LSTM和GRU在循环神经网络中的应用,以及深度学习模型调参经验,包括初始化方法和预处理策略。此外,讨论了深度学习适用的数据集条件和常用方法,如CNN在CV、NLP和AlphaGo中的应用。
本文深入探讨了深度学习中的关键概念,包括模型流程、网络结构、过拟合与欠拟合的解决方案,以及卷积操作、BN层的作用。激活函数如ReLU与tanh的比较,以及它们在解决梯度消失问题中的角色。同时,介绍了LSTM和GRU在循环神经网络中的应用,以及深度学习模型调参经验,包括初始化方法和预处理策略。此外,讨论了深度学习适用的数据集条件和常用方法,如CNN在CV、NLP和AlphaGo中的应用。
1.自己项目有关模型的相关问题如:项目整体流程、网络结构、 论文的实验是怎么做的、你的贡献是什么、创新点在哪里、遇到哪些问题是怎么解决的
2.过拟合和欠拟合的表现及解决方法
怎样判断过拟合欠拟合过拟合【泛化能力差】欠拟合:【训练和预测时表现都不好】
方差和偏差的解释欠拟合会导致高 Bias ,过拟合会导致高 Variance
产生原因:【训练数据一般都是现实练数据的子集。并且样本中存在噪声数据,由于采样错误,导致样本的数据不能正确的反应现实场景和业务】
【模型太复杂,过度的学习到了样本里的噪声数据,并不能很好表达真实输入输出之间的关系】
怎样减少过拟合欠拟合
欠拟合【增加新特征;复杂模型;较小正则项参数 ;Boosting集成】
过拟合【交叉检验;特征选择;增大正则项参数 lambda;增加训练数据;Bagging;增加噪声;早停;贝叶斯方法;降低模型复杂度(神经网络减少网络层数,神经元个数,dropout;BN层;决策树可以控制树的深度,剪枝等)。
DNN常见策略【早停策略;集成学习策略;DropOut】
3.卷积操作实现
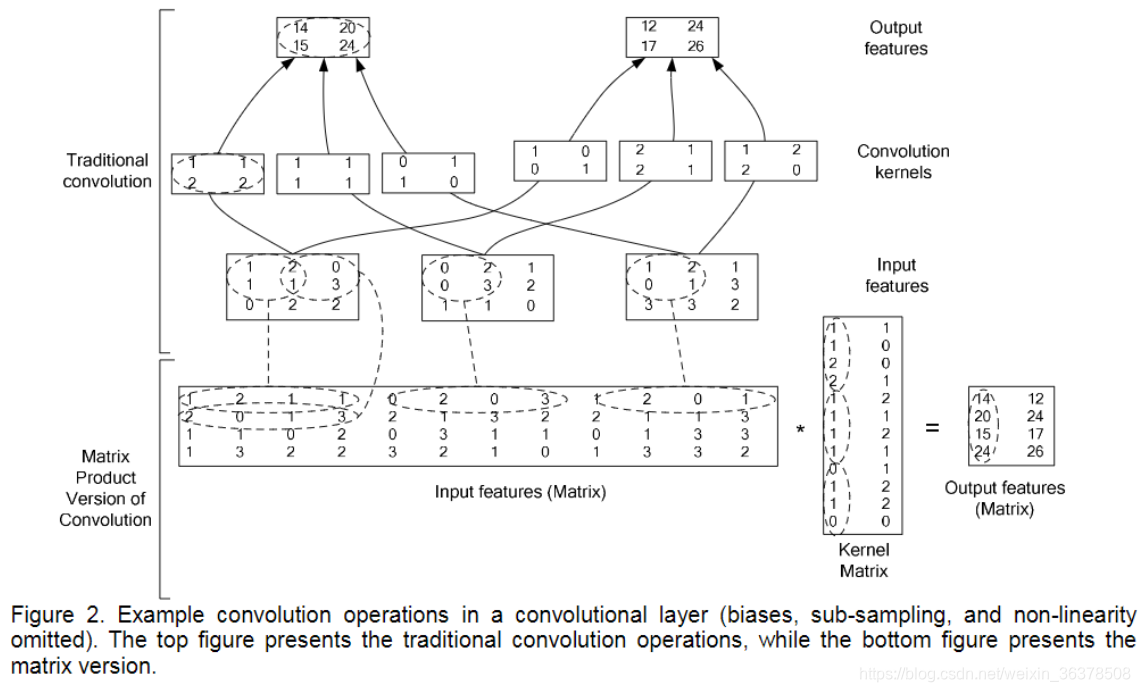
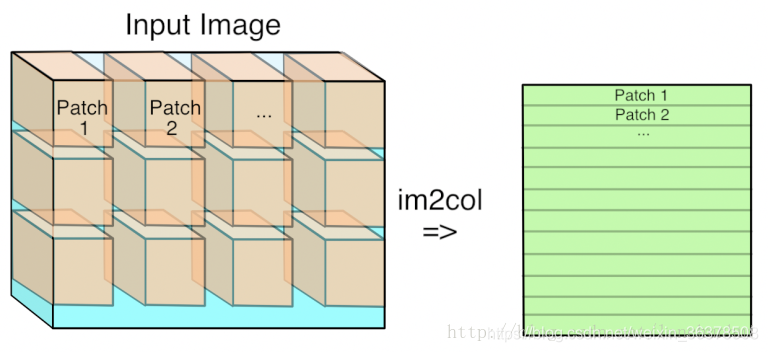
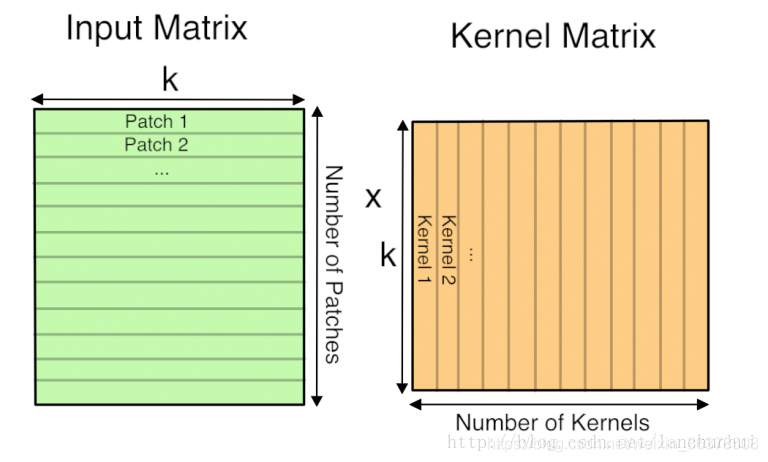
4:BN的理解
BN就是为了解决偏移的,解决的方式也很简单,就是让每一层的分布都normalize到标准高斯分布。(BN是根据划分数据的集合去做Normalization,不同的划分方式也就出现了不同的Normalization,如GN,LN,IN)
[N, H, W, C],其中N是batch_size,H、W是行、列,C是通道数,BN是对NHW进行归一化;对batch中对应的channel归一化
LN避开了batch维度,归一化的维度为[C,H,W]。
IN 归一化的维度为[H,W];
GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N*G,C//G , H, W],归一化的维度为[C//G , H, W]
训练和推理式君之和方差分别是多少
训练时:均值、方差分别是该批次内数据相应维度的均值与方差。
推理时:均值来说直接计算所有训练时batch的的平均值,而方差采用训练时每个batch的的无偏估计;但在实际实现中,如果训练几百万个Batch,那么是不是要将其均值方差全部储存,最后推理时再计算他们的均值作为推理时的均值和方差?这样显然太过笨拙,占用内存随着训练次数不断上升。为了避免该问题,后面代码实现部分使用了滑动平均,储存固定个数Batch的均值和方差,不断迭代更新推理时需要的均值和方差
BN好处
防止网络梯度消失:这个要结合sigmoid函数进行理解
加速训练,也允许更大的学习率:数据在一个合适的分布空间,经过激活函数,仍然得到不错的梯度。梯度好了自然加速训练。
降低参数初始化敏感
提高网络泛化能力防止过拟合:
可以把训练数据彻底打乱
5激活函数 激活函数的主要作用是在神经网络中引入非线性因素。
非线性,处处可微,计算简单,非饱和性,单调性,输出范围有限,接近恒等变换,参数少,归一化
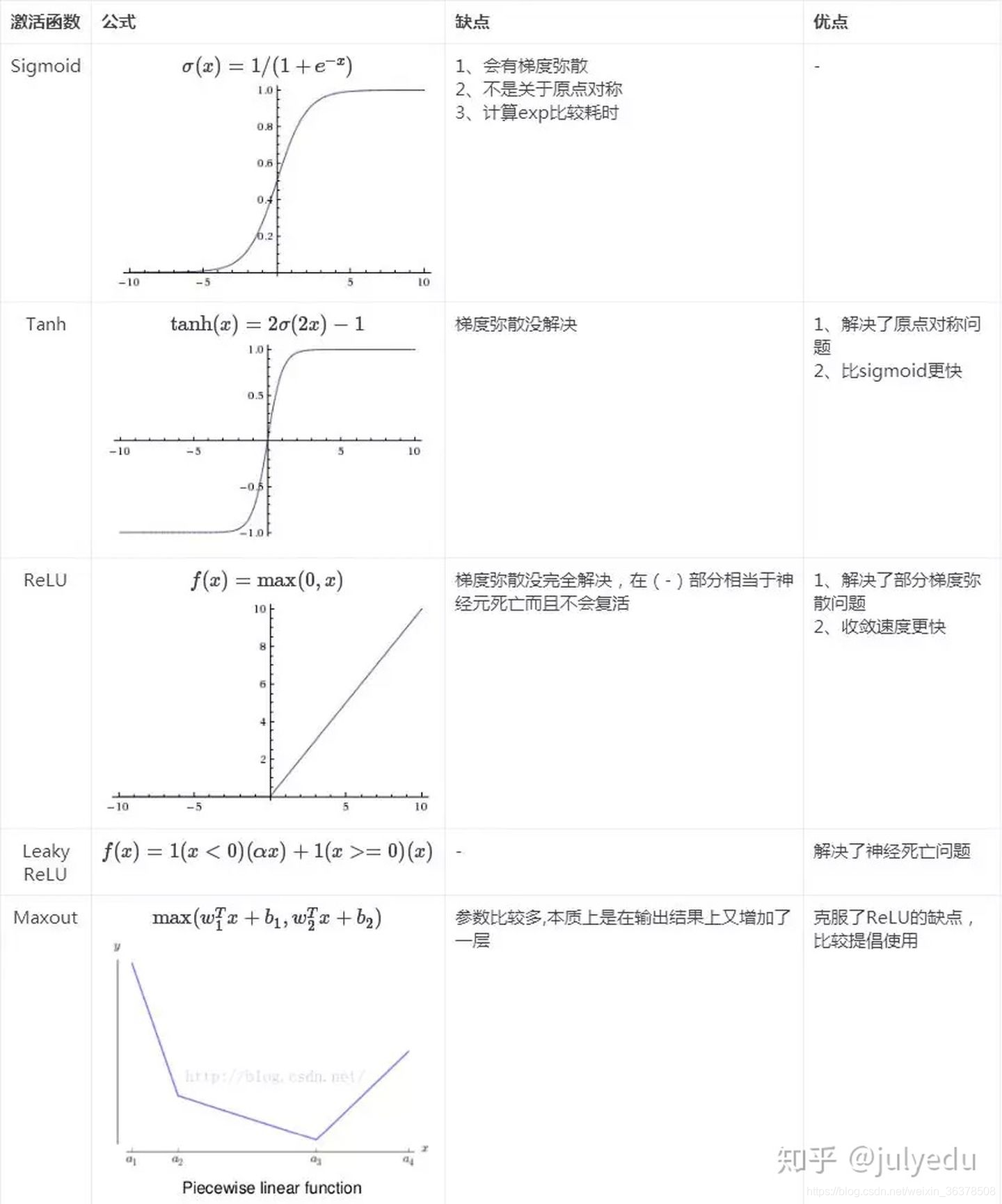
tanh激活函数输出关于“零点”对称的好处是什么?
对于sigmoid函数而言,其输出始终为正,这会导致在深度网络训练中模型的收敛速度变慢,因为在反向传播链式求导过程中,权重更新的效率会降低(具体推导可以参考这篇文https://www.zhihu.com/question/50396271?from=profile_question_card)。
假如权重为二维,那么全为负的和全为正的权重相加分布在一三象限,因此会出现zigzag现象,导致收敛速度缓慢。
此外,sigmoid函数的输出均大于0,作为下层神经元的输入会导致下层输入不是0均值的,随着网络的加深可能会使得原始数据的分布发生改变。而在深度学习的网络训练中,经常需要将数据处理成零均值分布的情况,以提高收敛效率,因此tanh函数更加符合这个要求。
sigmoid函数的输出在[0,1]之间,比较适合用于二分类问题。
为什么RNN中常用tanh函数作为激活函数而不是ReLU
详细分析可以参考这篇文章。https://www.zhihu.com/question/61265076/answer/186347780:
RNN中将tanh函数作为激活函数本身就存在梯度消失的问题,而ReLU本就是为了克服梯度消失问题而生的,那为什么不能直接(注意:这里说的是直接替代,事实上通过截断优化ReLU仍可以在RNN中取得很好的表现)用ReLU来代替RNN中的tanh来作为激活函数呢?这是因为ReLU的导数只能为0或1,而导数为1的时候在RNN中很容易造成梯度爆炸问题。因为在RNN中,每个神经元在不同的时刻都共享一个参数W,因此在前向和反向传播中,每个神经元的输出都会作为下一个时刻本神经元的输入,从某种意义上来讲相当于对其参数矩阵W作了连乘,如果W中有其中一个特征值大于1,则多次累乘之后的结果将非常大,自然就产生了梯度爆炸的问题。
那为什么ReLU在CNN中不存在连乘的梯度爆炸问题呢?,因为在CNN中,每一层都有不同的参数w,有的特征值大于1,有的小于1,在某种意义上可以理解为抵消了梯度爆炸的可能。
如何解决ReLU神经元“死亡”的问题?
①采用Leaky ReLU等激活函数 ②设置较小的学习率进行训练 ③使用momentum优化算法动态调整学习率
6.激活函数不可导怎么办
relu,在x=0时,强制使导数为1,使得函数强行处处可微
池化层:将一个导数传递给多个
7.为什么机器学习中解决回归问题的时候一般使用平方损失(即均方误差)
最小二乘法的推导结果就是平方损失 https://www.pianshen.com/article/3151913553/
8.ReLU函数在0处不可导,为什么在深度学习网络中还这么常用 因为真的好用,10亿AI调参侠都在用,用了都说好。但它在0处不可导,怎么办?其实我们可以人为提供一个伪梯度,例如给它定义在0处的导数为0,其实tensorflow在实现ReLU的时候也是定义ReLU在0处的导数为0的。
另外还有一个方法是使用 l n ( 1 + e x ) ln(1+e^x) ln(1+ex) 来近似,这个函数是连续的,它在0点的导数是0.5。也就是相当于relu在0点的导数取为0.5,也正好是0和1的均值。
ReLU函数的形式非常简洁,是由两段线性函数组成的非线性函数,函数形式看似简单,但ReLU的组合却可以逼近任何函数。
其实ReLU提出的最大作用是解决sigmoid函数导致的梯度消失问题的,所以ReLU的优势大部分是与它的死对头sigmoid函数对比体现出来的,对比这两个函数的图形可以看出:ReLU有单侧抑制,即Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。另外这也更符合生物神经元的特征。
ReLU的运算速度快,这个很明显了,max肯定比幂指数快的多。
9.梯度消失和梯度爆炸 当系数比较小时,前面的网络层比后面的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。 当系数比较大时,则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。
当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生?
结论:梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。 用Batch
Normalization。 LSTM的结构设计也可以改善RNN中的梯度消失问题。
10.deep learning(rnn、cnn)调参的经验? 参数初始化【Xavier初始法;He初始化;uniform均匀分布初始化】
Xavier初始法,适用于普通激活函数(tanh,sigmoid):scale = np.sqrt(3/n) He初始化,适用于ReLU:scale = np.sqrt(6/n) normal高斯分布初始化:w =
np.random.randn(n_in,n_out) * stdev # stdev为高斯分布的标准差,均值设为0
svd初始化:对RNN有比较好的效果。
数据预处理方式【zero-center,normalize】【PCA whitening】
训练技巧 梯度归一化;clip c(梯度裁剪);dropout(对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd)。
dropout的位置比较有讲究,
对于RNN,建议放到输入->RNN与RNN->输出的位置.关于RNN如何用dropout,可以参考这篇论文:http://arxiv.org/abs/1409.2329
adam,adadelta等,在小数据上,我这里实验的效果不如sgd,
sgd收敛速度会慢一些,但是最终收敛后的结果,一般都比较好。如果使用sgd的话,可以选择从1.0或者0.1的学习率开始,隔一段时间,在验证集上检查一下,如果cost没有下降,就对学习率减半.
我看过很多论文都这么搞,我自己实验的结果也很好.
当然,也可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好。
除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,可以用tanh或者relu之类的激活函数.1.
sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。2.
输入0均值,sigmoid函数的输出不是0均值的。 rnn的dim和embdding size,一般从128上下开始调整. batch
size,一般从128左右开始调整.batch size合适最重要,并不是越大越好。
word2vec初始化,在小数据上,不仅可以有效提高收敛速度,也可以可以提高结果。
尽量对数据做shuffle LSTM 的forget gate的bias,用1.0或者更大的值做初始化,可以取得更好的结果,来自这篇论文:http://jmlr.org/proceedings/papers/v37/jozefowicz15.pdf,
我这里实验设成1.0,可以提高收敛速度.实际使用中,不同的任务,可能需要尝试不同的值. Batch
Normalization据说可以提升效果,不过我没有尝试过,建议作为最后提升模型的手段,参考论文:Accelerating Deep
Network Training by Reducing Internal Covariate Shift
如果你的模型包含全连接层(MLP),并且输入和输出大小一样,可以考虑将MLP替换成Highway
Network,我尝试对结果有一点提升,建议作为最后提升模型的手段,原理很简单,就是给输出加了一个gate来控制信息的流动,详细介绍请参考论文:
http://arxiv.org/abs/1505.00387 来自@张馨宇的技巧:一轮加正则,一轮不加正则,反复进行。
Ensemble 同样的参数,不同的初始化方式 不同的参数,通过cross-validation,选取最好的几组 同样的参数,模型训练的不同阶段,即不同迭代次数的模型。 不同的模型,进行线性融合. 例如RNN和传统模型。
11.CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
解析:
以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。
CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本)
中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。
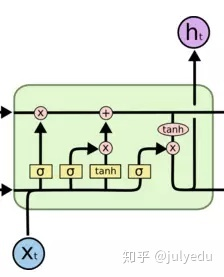
12.LSTM结构推导,为什么比RNN好? 解析: 推导forget gate,input gate,cell state, hidden information等的变化;因为LSTM有进有出且当前的cell informaton是通过input
gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸。
13.为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?这样做的目的是什么? sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。 tanh
用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。 二者目的不一样 另可参见A Critical Review of
Recurrent Neural Networks for Sequence
Learning的section4.1,说了那两个tanh都可以替换成别的。
14、什麽样的资料集不适合用深度学习? (1)数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
(2)数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
15.深度学习常用方法。
解析:
全连接DNN(相邻层相互连接、层内无连接):
AutoEncoder(尽可能还原输入)
Sparse Coding(在AE上加入L1规范)
RBM(解决概率问题)—–>特征探测器——>栈式叠加 贪心训练
RBM—->DBN
解决全连接DNN的全连接问题—–>CNN
解决全连接DNN的无法对时间序列上变化进行建模的问题—–>RNN—解决时间轴上的梯度消失问题——->LSTM
16.梯度下降法的神经网络容易收敛到局部最优,为什么应用广泛?
深度神经网络“容易收敛到局部最优”,很可能是一种想象,实际情况是,我们可能从来没有找到过“局部最优”,更别说全局最优了。
17.CNN常用的模型

18.GRU是什么?GRU对LSTM做了哪些改动?
解析:
GRU是Gated Recurrent Units,是循环神经网络的一种。
GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将hidden state 传给下一个单元,而LSTM用memory cell 把hidden state 包装起来。
19.神经网络中,是否隐藏层如果具有足够数量的单位,它就可以近似任何连续函数。
UAT指出,只要所使用的激活函数是有界的,连续的且单调增加的,则紧凑域上的任何连续函数都可以通过仅具有一个隐藏层的神经网络来近似。 现在,有限函数的有界函数由定义来界。
万能近似定理(universal approximation theorem)(Hornik et al., 1989;Cybenko, 1989) 表明,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel 可测函数。
万能近似定理意味着无论我们试图学习什么函数,我们知道一个大的MLP 一定能够表示这个函数。然而,我们不能保证训练算法能够学得这个函数。即使MLP能够表示该函数,学习也可能因两个不同的原因而失败。
用于训练的优化算法可能找不到用于期望函数的参数值。
训练算法可能由于过拟合而选择了错误的函数。
Gradient clipping

















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









