






 本文提出一种新的面向物体的3DSLAM范式,利用深度相机进行3D物体识别和跟踪,提供6DoF相机物体约束。通过高效的姿态图优化方法进行调整,实现实时的SLAM增长式系统,包括在复杂场景中的回环、重定位和移除物体等功能。
本文提出一种新的面向物体的3DSLAM范式,利用深度相机进行3D物体识别和跟踪,提供6DoF相机物体约束。通过高效的姿态图优化方法进行调整,实现实时的SLAM增长式系统,包括在复杂场景中的回环、重定位和移除物体等功能。
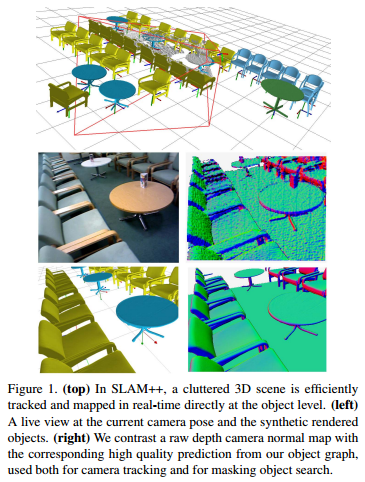
摘要:
我们提出一种新的面向物体的3D SLAM 范式,它的好处在于,许多场景中有重复的、领域特定的物体和结构,我们充分在闭环中充分利用这些先验知识。
手持深度相机扫过杂乱的场景,湿湿的3D物体识别和跟踪提供了6DoF的相机物体约束,作为物体的显式图,通过高效的姿态图优化方法进行调整。
这对于SLAM系统提供了一个描述和预测的力量,但是表示起来极为将来能。
物体图能够在每个实时帧中,用精确的基于ICP的相机的方法进行跟踪。
高效的主动的在当前没有描述的图片区域中倒找新的的物体。
我们证明了这个实时的增长式的SLAM。包括在大且杂乱的场景中,包括回环,重定位和移开物体,当然物体层面场景的描述的得到是有潜力去支持交互的。
简介:
目前很多实时的SLAM系统在低层元素(例如点、线、补丁、非参数的曲面表示例如深度图),必须鲁棒地匹配,几何上转换,优化,目的是地图表示纷杂的现实世界。
现代硬件处理器,提供前所未有的水平的细节和规模,大家的兴趣转向语义标签的几何学,尤其是对象和区域在场景中已知。
然而一些想法暴露了大量浪费计算的问题,找到一种更好的方法来在SLAM循环的操作本身利用domain知识。
我们提供了一种范式,

















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









