



 探讨单目标回归在计算机视觉中的应用,特别是区域提议网络如何通过回归调整边界框以更精确地定位目标。分析L2Loss和SmoothL1Loss两种损失函数在回归任务中的优缺点,包括它们对预测值与真实值差距的处理方式。
探讨单目标回归在计算机视觉中的应用,特别是区域提议网络如何通过回归调整边界框以更精确地定位目标。分析L2Loss和SmoothL1Loss两种损失函数在回归任务中的优缺点,包括它们对预测值与真实值差距的处理方式。
输入输出
Bounding Box Regressor 训练过程的输入由两部分组成:
- data:原图或其feature
- label: ground truth bounding box.
regression输出为一组可以确定nn个bounding box的数值. 数值涵义由label决定.
本文讨论n=1n=1的情况, 即Single box regression: 一张图片回归一个bounding box.
典型的应用出现在RCNN: Proposal太大时, 需要缩小范围以更精确的框出目标物体. 它的regressor的输入为一个proposal region, 输出为一个bounding box.
一个region由一个四维向量表示: P=(Px,Py,W,H)P=(Px,Py,W,H), 其中, (Px,Py)(Px,Py)为中心点的位置(RCNN)或左上角的位置(Fast RCNN), (W,H)(W,H)为它的宽和高. 它对应的bbox ground truth由G=(Gx,Gy,Gw,Gh)G=(Gx,Gy,Gw,Gh)表示, 各参数的涵义与PP类似.
L2 Loss
用f(P)f(P)表示regressor的输出, 最简单粗暴的loss可以表示为:
L∗=(f∗(P)−G∗)2L∗=(f∗(P)−G∗)2
其中, ∗∗代表 x,y,w,hx,y,w,h, 整个loss : L=Lx+Ly+Lw+LhL=Lx+Ly+Lw+Lh .
也就是说直接预测bbox的绝对坐标与绝对长度. 但是这样会出现一个问题: loss的大小会受到图片大小的影响, 不大合理. 例如, 当ground truth 分别为 (100,100,200,200)(100,100,200,200), (10,10,20,20)(10,10,20,20)时, 假如分别得到 (90,90,200,200)(90,90,200,200), (8,8,20,20)(8,8,20,20)的bbox预测值. 那么前者对应的loss会远大于后者, 但是从实际情况上来看, 100−90100=0.1,10−810=0.2100−90100=0.1,10−810=0.2, 前者的相对误差要小于后者. 所以需要一个规范化(normalization)处理. 若在loss上规范化:
Lx=(fx(P)−Gx)W)2Lx=(fx(P)−Gx)W)2
Ly=(fy(P)−Gy)H)2Ly=(fy(P)−Gy)H)2
Lw=(fw(P)−Gw)W)2Lw=(fw(P)−Gw)W)2
Lh=(fh(P)−Gh)H)2Lh=(fh(P)−Gh)H)2
其中, W,HW,H分别为输入图片的宽与高.
这样loss是不受绝对大小的影响了, 但是还有一个问题: f(P)f(P)直接输出了绝对距离, 这种输出值是没有上下限的. 目测会让训练过程的收敛变得困难甚至不可能.(个人推测, 未验证/考证.). 另外, 学习速率的选择也会变得困难. 所以, 规范化操作要在label上进行. 即, 将回归目标规范化, 例如RCNN中使用的target为:
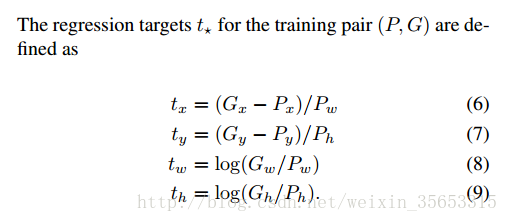
这样回归出来的就是bbox在图片上的相对位置, 各个位置参数的值都是在0到1之间. 比较特殊的是 w,hw,h的regression targets使用了log space. 师兄指点说这是为了降低 w,hw,h产生的loss的数量级, 让它在loss里占的比重小些, 不至于因为 w,hw,h的loss太大而让 x,yx,y产生的loss无用. 因为若是 x,yx,y没预测准确, w,hw,h再准确也没有用.
若使用MLP进行回归, 那输出层的激活函数是identity, 即 f(P)=WTΦ(P)f(P)=WTΦ(P), 其中, WW为权重矩阵, Φ(P)Φ(P)为proposal P的特征向量.
Smooth L1 Loss
当预测值与目标值相差很大时, 梯度容易爆炸, 因为梯度里包含了x−tx−t. 所以rgb在Fast RCNN里提出了SmoothL1Loss. 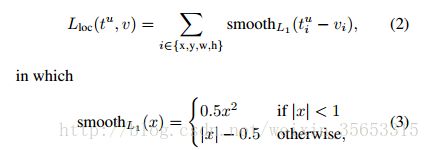
当差值太大时, 原先L2梯度里的x−tx−t被替换成了±1±1, 这样就避免了梯度爆炸, 也就是它更加健壮.
Fast-RCNN为了使用SmoothL1Loss定义了一个新的layer, 它的实现更general:
xi=win(ti−vi),i∈{x,y,w,h}xi=win(ti−vi),i∈{x,y,w,h}
smoothL1={0.5x2σ2,|x|−0.5σ2,|xσ|<1otherwisesmoothL1={0.5x2σ2,|xσ|<1|x|−0.5σ2,otherwise
SmoothL1Loss=wout∑i∈{x,y,w,h}smoothL1(xi)SmoothL1Loss=wout∑i∈{x,y,w,h}smoothL1(xi)
- winwin可用于指定哪些regression结果参与loss的计算(Fast RCNN里的λ[u ≥ 1], Faster RCNN里的P∗P∗).
- woutwout可用于normalization.

















 4626
4626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









