 线段树区间查询优化
线段树区间查询优化




Description
小Y 最近学习了线段树,但是由于她的智商比较低,运用的还不是很熟练。于是小R 给了她一点练习题训练,其中有一道是这样的。
这是小R 写的线段树的一段建树代码:

只要调用buildtree(1,0,n) 就可以得到一颗线段树了。显然,一颗线段树一共有O(n) 个节点,因为每一个节点都代表了一个不同的区间,所以线段树上一共出现了O(n) 个不同的区间。
现在小R 给了你一个区间[l; r],他想要你告诉他一个最小的n 使得区间[l; r] 出现在了用buildtree(1,0,n) 建出来的线段树中。
这是小R 写的线段树的一段建树代码:
只要调用buildtree(1,0,n) 就可以得到一颗线段树了。显然,一颗线段树一共有O(n) 个节点,因为每一个节点都代表了一个不同的区间,所以线段树上一共出现了O(n) 个不同的区间。
现在小R 给了你一个区间[l; r],他想要你告诉他一个最小的n 使得区间[l; r] 出现在了用buildtree(1,0,n) 建出来的线段树中。
Input
第一行输入一个正整数T 表示数据组数。
接下来T 行每行三个整数L;R; lim 表示一组询问,如果对于所有的0 <= n <= lim 都不存在满足条件的解,输出-1 即可。
接下来T 行每行三个整数L;R; lim 表示一组询问,如果对于所有的0 <= n <= lim 都不存在满足条件的解,输出-1 即可。
Output
对于每组询问输出一个答案。
Sample Input
2
0 5 10
6 7 10
Sample Output
5
7
Data Constraint
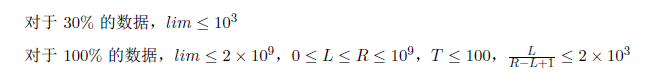
分析
水题
通过小区间往上扩展即可,四种扩展方法
然后有很多奇奇怪怪的特判,lim要取lim和l+r的最小值


#include <iostream> #include <cstdio> #include <memory.h> using namespace std; typedef long long ll; int T; ll l,r,limit,ans; void DFS(ll l,ll r) { if (l<0||r>limit||r>ans&&ans!=-1) return; if (l==0) { if (ans==-1) ans=r; else ans=min(ans,r); return; } DFS(l,r*2-l);DFS(l,r*2+1-l); DFS(2*(l-1)-r,r);DFS(2*(l-1)-r+1,r); } int main() { for (scanf("%d",&T);T;T--) { scanf("%d%d%d",&l,&r,&limit); if (l==0&&r<=limit||l==r) printf("%lld\n",r); else { if (r>limit) { printf("-1\n"); continue; } limit=min(limit,l+r); ans=-1; DFS(l,r); printf("%d\n",ans); } } }

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









