







20230915周五更新
多分类:一个图片只能分为1种东西
多标签:一个图片可以有很多的标签,图片上的内容都可以算。
但多标签和多任务的区别是?在GPT上查了一下,有点差强人意吧
- 任务之间有依赖关系则是多任务?感觉多标签里标签与标签并没有太多的联系。
- 在数据标注形式上,多标签与多任务感觉没区别。
- 假设要预测3个东西。或许多标签是1个emb输入1个head,1个head输出3个概率值对应3个东西是or否;然后多标签是3个emb输入3个head,每个head对应输出各自任务的概率值?应该是这样的。因为第4点说了,多标签每个标签都有一个相应的预测损失。
但多任务可能只有1个损失函数,然后这个损失函数是多个任务误差的加权和或联合损失函数。
深度学习中,多任务与多标签的区别
在深度学习中,多任务学习(Multi-Task Learning, MTL)和多标签学习(Multi-Label Learning, MLL)是两种不同的学习方式。
它们的区别主要体现在以下几个方面:
1. 学习目标:
- 多任务学习旨在同时学习和优化多个相关的任务,这些任务可能在一定程度上相互依赖或共享底层特征。
- 多标签学习是一种解决单个任务中存在多个标签的问题,每个样本可以被分配一个或多个标签。
2. 数据标注:
- 多任务学习,每个任务都有其独立的标注数据。每个样本通常对应多个任务的标签。
- 多标签学习,每个样本也可以有多个标签,但是它们属于同一个任务。
3. 模型设计:
- 多任务学习中,模型通常会包含共享层和专用层。共享层用于提取共享的特征,专用层用于实现特定任务的预测。共享层的参数用于多个任务的学习和优化。
- 多标签学习中,只有一个任务,模型的设计更加简洁,通常包含输入层、隐藏层和输出层。
4. 损失函数:
- 多任务学习,常见的损失函数可以是多个任务误差的加权和或联合损失函数。不同任务的重要性可以通过调整权重来实现。
- 多标签学习,通常采用二分类、多分类或序列标注的损失函数,每个标签都有一个相应的预测损失。
总结来说,
- 多任务学习着重于同时学习和优化多个相关任务,模型通过共享特征来提高整体性能;
- 多标签学习则是在一个任务中处理多个标签,每个样本可以具有多个标签,但是它们同属于同一个任务。
1、Multi-Class:多分类/多元分类(二分类、三分类、多分类等)
- 二分类:判断邮件属于哪个类别,垃圾或者非垃圾
- 二分类:判断新闻属于哪个类别,机器写的或者人写的
- 三分类:判断文本情感属于{正面,中立,负面}中的哪一类
- 多分类:判断新闻属于哪个类别,如财经、体育、娱乐等
2、Multi-Label:多标签分类
- 文本可能同时涉及任何宗教,政治,金融或教育,也可能不属于任何一种。
- 电影可以根据其摘要内容分为动作,喜剧和浪漫类型。有可能电影属于romcoms [浪漫与喜剧]等多种类型。
例子:
假设个人爱好的集合一共有6个元素:运动、旅游、读书、工作、睡觉、美食。左边是one-hot,右边是multi-hot。
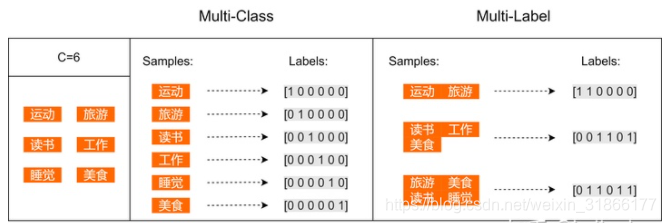
以实际任务举例,
多标签文本分类
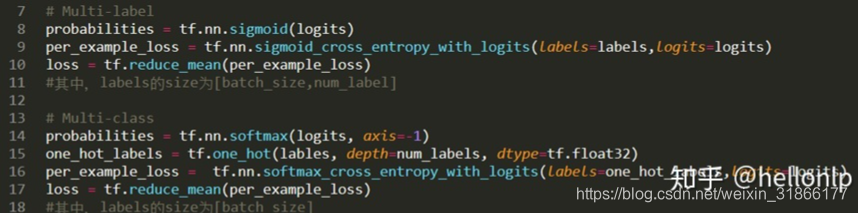
1、改变输出概率(probabilities)的计算方式和交叉熵的计算方式
- tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。
- tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。
- 在简单的二进制分类中,sigmoid和softmax没有太大的区别,但是在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。
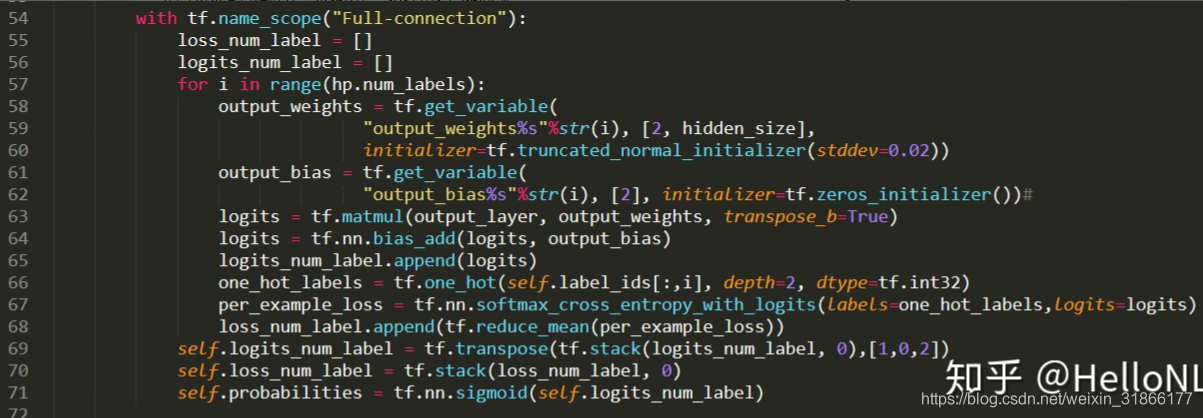
2、改变输出的全连接层。
- 在输出层设置多个全连接层,每一个全连接层对应一个标签。
- 损失函数为所有标签损失函数的平均值。
3、使用框架:Attention + seq2seq(Beam Search)
因为本文目的也不是讲nlp,此部分可以看原文

















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









