







回顾上一篇 神经网络的数学基础:张量运算
引言
学习神经网络的时候我们总是听到激活函数这个词,而且很多资料都会提到常用的激活函数,比如Sigmoid函数、Tanh函数、ReLU函数。我们就来详细了解下激活函数方方面面的知识。本文的内容包括几个部分:
- 什么是激活函数?
- 为什么需要激活函数?激活函数的作用是什么?
- 常用激活函数有哪些,都有什么优特点?
- 如何选择适合项目的激活函数?
- 激活函数的Python实现
- 简单三层神经网络- 前馈输出
如果你对以上几个问题不是很清楚,下面的内容对你是有价值的。
什么是激活函数?
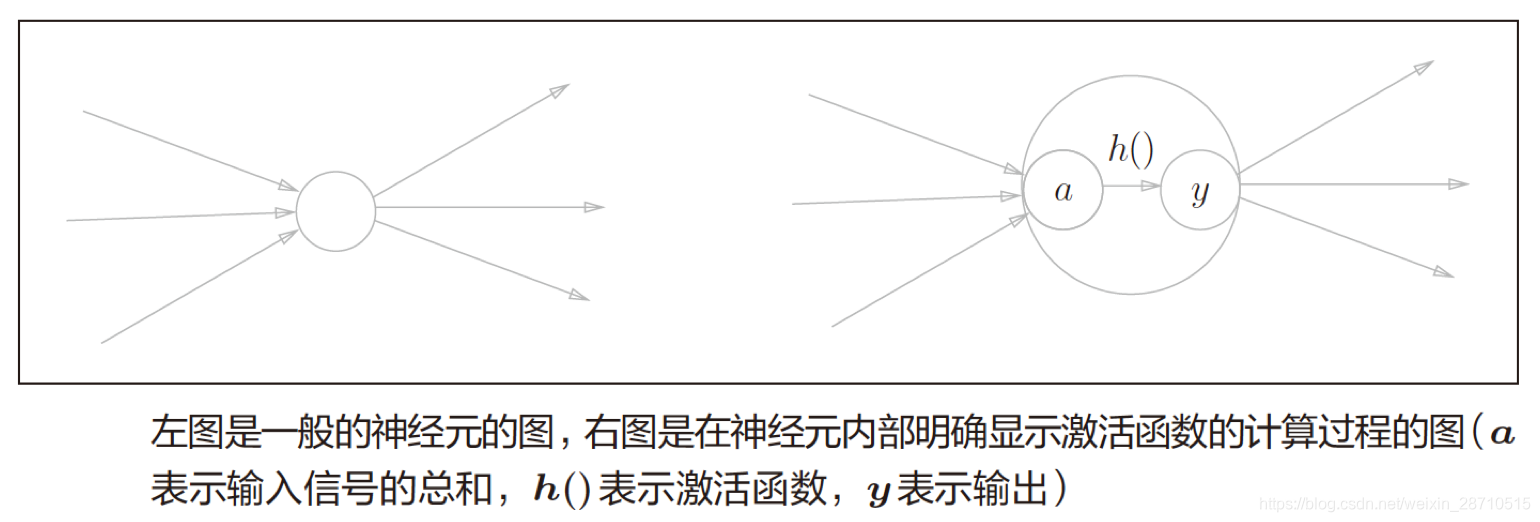
在上一篇末尾我们讲到了神经网络的内积,但那还不是那一层的最终输出,最终输出什么?输出多少? 需要有一个函数来确定,这个函数将输入信号的总和(内积)转换为输出信号,这种函数一般称为激活函数(activation function)。如“激活”一词所示,激活函数的作用在于决定如何来激活输入信号的总和。下图中h()函数作用到a上,从而得到神经元到输出y,h()就是激活函数或者叫做激励函数。
为什么需要激活函数?激活函数的作用是什么?
在谈到激活函数时,也经常会看到“非线性函数”和“线性函数”等术语。函数本来是输入某个值后会返回一个值的转换器。向这个转换器输入某个值后,输出值是输入值的常数倍的函数称为线性函数(用数学式表示为h(x) = cx。c 为常数)。因此,线性函数是一条笔直的直线。而非线性函数,顾名思义,指的是不像线性函数那样呈现出一条直线的函数。
神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
如果不考虑激活函数,考虑一个三层神经网络的输出公式:
a 1 = x w 1 + b 1 a 1 传递到第二层 a 2 = a 1 w 2 + b 2 a 2 传递到第三层 a 3 = a 2 w 3 + b 3 a^{1} = xw^{1} + b^{1} ~~~~a^{1}传递到第二层 ~~\\ a^{2} = a^{1}w^{2} + b^{2} ~~~~a^{2}传递到第三层 ~~\\ a^{3} = a^{2}w^{3} + b^{3} a1=xw1+b1 a1传递到第二层 a2=a1w2+b2 a2传递到第三层 a3=a2w3+b3
注意,1,2,3代表层数
可以看到这种神经网络层之间信号传递全是我们中学学过的平面解析几何里线性(y = kx + b)形式的传递方式,是没有意义的,无论叠加多少层。
正因为上面的原因,神经网络引入非线性函数的激活函数,才可以充分发挥层叠加所带来的优势,这样几乎可以逼近任意函数。
常用激活函数有哪些,都有什么优特点?
sigmoid函数是神经网络中最常使用的激活函数,在深度学习领域,自从提出ReLU函数后,陆续提出了一些新的激活函数或ReLU的衍生函数。主要激活函数如下所示:
- sigmoid & tanh
- ReLU以及其衍生函数
- MaxOut
Sigmoid & tanh
Sigmoid 是常用的非线性激活函数,它的数学形式如下:
f ( x ) = 1 1 + e x p ( − x ) ~~~~~~~~~f(x)=\frac {1}{1+exp^{(-x)}} f(x)=1+exp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











