



 本文介绍了多分类问题中信息熵、交叉熵的概念及其在模型训练中的作用,如softmax归一化和one-hot编码的应用。详细讲解了如何准备MINIST数据集并使用torchvision进行数据预处理,包括ToTensor和Normalize步骤。
本文介绍了多分类问题中信息熵、交叉熵的概念及其在模型训练中的作用,如softmax归一化和one-hot编码的应用。详细讲解了如何准备MINIST数据集并使用torchvision进行数据预处理,包括ToTensor和Normalize步骤。
目录
一:背景与多分类问题的知识点背景介绍
信息量(I(x)):当一个事件发生的概率越大,它所包含的信息量也就越少。I(x) = -ln(p(x))
熵(H(x)):表示系统的混乱程度,代表一个系统内信息量的总和,熵越大表示系统越混乱
交叉熵(H(a,b)):表示a,b之间的相似程度,越小表示越接近。
对于多分类问题,不能像二分类那样一种情况发生的概率是1,另外几种的都是零。比如掷色子,每个点位出现的概率都是1/6,而不是1或0.所以,在多分类的任务里,我们要保证两点,1:每个情况出现的概率大于等于0;2:所有情况出现的概率之和为1.那么就需要在最后线形层的输出值后引入softmax层。softmax层的作用就是先将输出值做e^处理来实现1,再进行如下处理来进行2(归一化)
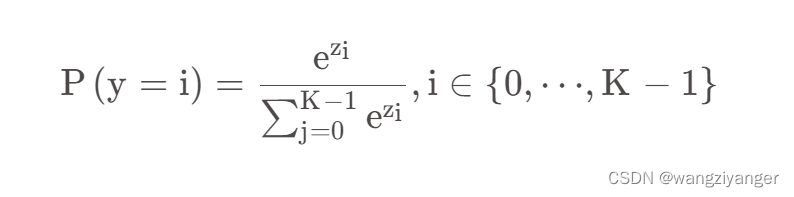
之后做交叉熵来计算损失值

这里引入one-hot编码方式。这种编码方式是将离散的状态信息,连续化用一个Tensor来表达。比如在学校中的个人信息是
| 小明 | 男 | 2班 | 班长 |
| 小红 | 女 | 1班 | 副班长 |
| 小张 | 男 | 3班 | 学生 |
现在要对离散的个人信息用向量的形式来表达,就要保证一维信息中,只有一个1其余都是0
| 小明 | 01 | 010 | 100 |
| 小红 | 10 | 001 | 010 |
| 小张 | 01 | 100 | 001 |
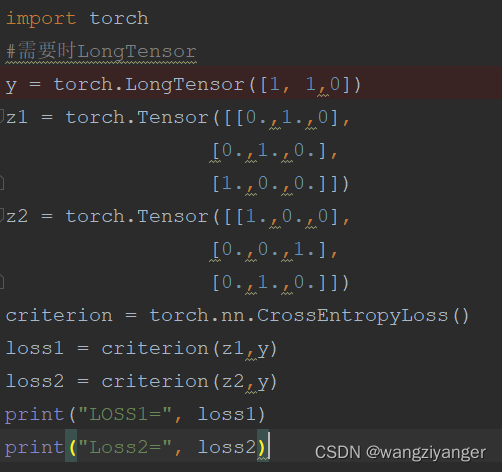
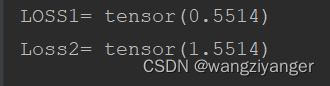
我们用小明的信息用来和小明和小红的做参考,看看两者的损失值谁大谁小。可以看出明显小红的信息和小明不是很匹配。
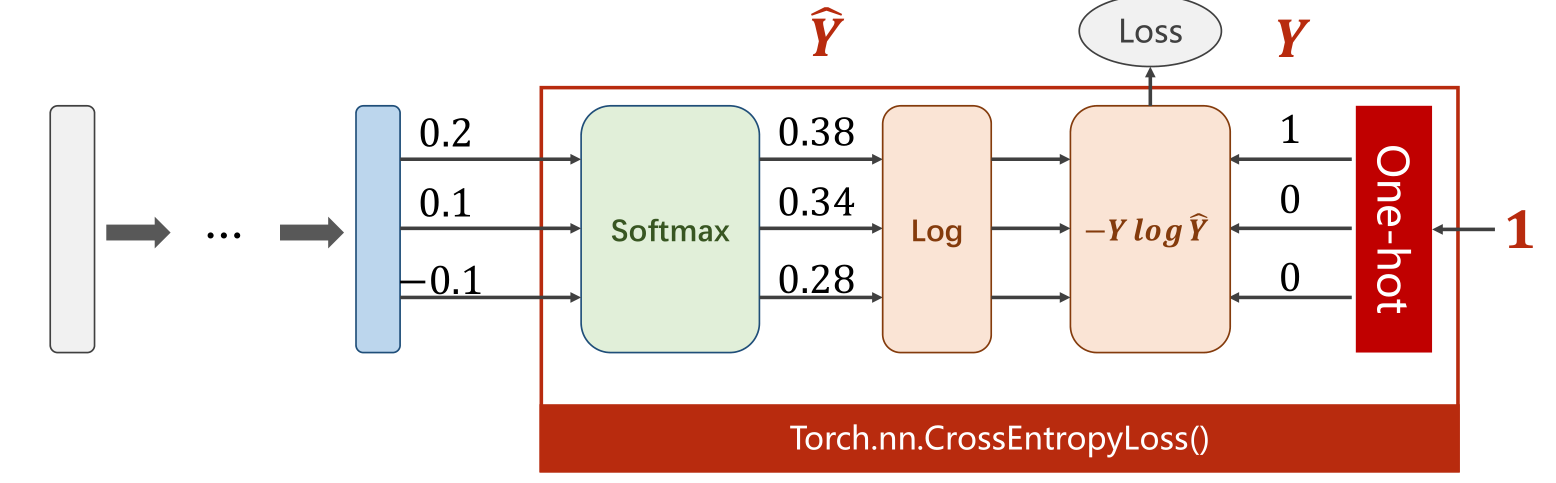
在torch中自带的CrossEntropyloss()函数中封装了one-hot功能,softmax和其他交叉熵计算功能。但是要注意参考的y值的输入方式要和z的输入方式区分开来。
import torch
#需要时LongTensor
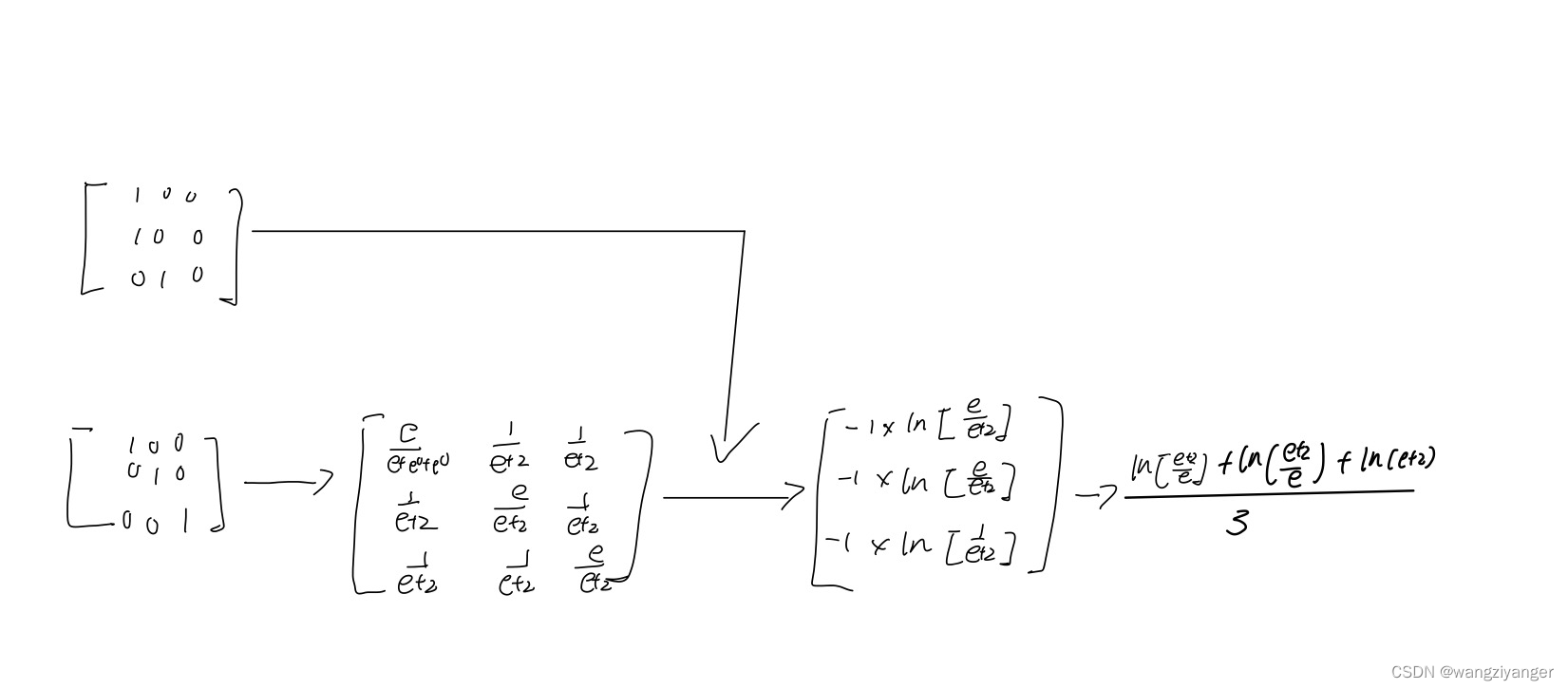
y = torch.LongTensor([0, 0, 1])
z = torch.Tensor([[1.0, 0., 0.],
[0., 1.0, 0.],
[0., 0., 1.0]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z,y)
print(loss)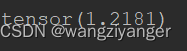
对于LongTensor([0, 0 ,1]),指的是矩阵[[1,0,0],[1,0,0],[0,1,0]],这里的数字代表的是位置;CrossEntropyLoss()运算过程是。
二:数据集的准备
1:转换数据格式
这里要说一下,我们通常python读取图片的时候用的pillow,这里MINIST数据集中一张图片是H×W×C(长×宽×通道)=28*28*1=758的像素图片,其中每个像素点中的信息用[0,255]来表示,但是对于神经网络的训练来说太大了,占用太多算力,所以我们通常将像素点中的信息量压缩成[-1,1],且满足一定均值和方差的正态分布,并且是C×H×W。所以在torchvision中的transforms.Compose()函数的作用就是将pillow中的信息转成满足需求的张量。
transform = transforms.Compose(transforms.ToTensor()
,transforms.Normalize(0.1307,),(0.3081))
transforms.ToTensor()的作用是变成C×H×W,且将信息量变成【0,1】
transforms.Normalize(0.1307,),(0.3081)的作用是按照一定均值与方差将信息量变为满足一定均值和方差的正态分布。大部分的常用数据集都是有公认的均值与方差的。
2:加载MINIST的训练集与测试集
计算机视觉是深度学习中最重要的一类应用,为了方便研究者使用,PyTorch 团队专门开发了 一个视觉工具包torchvision,这个包独立于 PyTorch,需通过 pip instal torchvision 安装。
torchvision 主要包含三部分:
models:提供深度学习中各种经典网络的网络结构以及预训练好的模型,包括 AlexNet 、VGG 系列、ResNet 系列、Inception 系列等;
datasets: 提供常用的数据集加载,设计上都是继承 torch.utils.data.Dataset,主要包括 MNIST、CIFAR10/100、ImageNet、COCO等;
transforms:提供常用的数据预处理操作,主要包括对 Tensor 以及 PIL Image 对象的操作;
train_datasets = datasets.MNIST(root="../dataset/minist/",train=True,transform=transform,download=True)
train_loader = DataLoader(dataset=train_datasets,batch_size=batchsize,shuffle=True,num_workers=0)
test_datasets = datasets.MNIST(root='../dataset/minist/',train=False,transform=transform,download=True)
test_datasets = DataLoader(dataset=test_datasets,batch_size=batchsize,shuffle=True,num_workers=0)下载训练集,train是否要进行训练,transform=是要进行哪种转换形式,download如果在本地没有找到数据集,是否要网上下载。dataloader的作用就是就是按照batchsize来划分输入值,做好分组。并且打乱。(或者说数据下载好后,一定要载入数据到该项目当中)(注意:测试集不用训练)


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









