



 这篇博客详细介绍了PyTorch中的数据加载机制DataLoader,以及如何使用图像预处理模块transforms。博主构建了一个简单的多层神经网络,并用MNIST数据集进行训练,讨论了模型搭建、损失函数、优化器选择,特别是动量优化器的作用。此外,还展示了训练和测试函数的实现,包括准确率的计算方法。
这篇博客详细介绍了PyTorch中的数据加载机制DataLoader,以及如何使用图像预处理模块transforms。博主构建了一个简单的多层神经网络,并用MNIST数据集进行训练,讨论了模型搭建、损失函数、优化器选择,特别是动量优化器的作用。此外,还展示了训练和测试函数的实现,包括准确率的计算方法。
(5条消息) 系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)_翻滚的小@强的博客-优快云博客_dataloader读取顺序
三:模型搭建
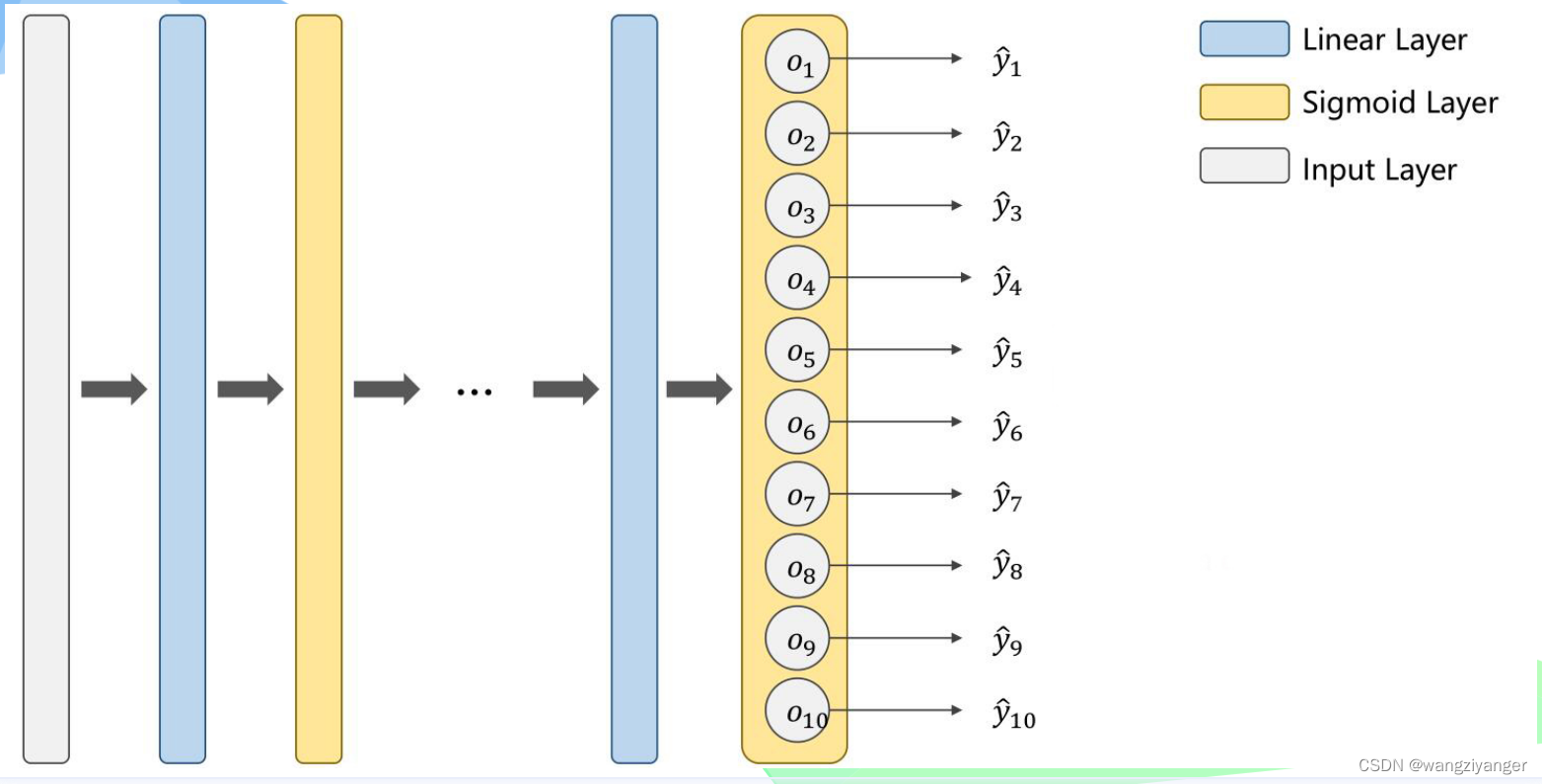
测试集中有10个数据与之一一对应(0~~9),所以我们应当将784降维到10,中间的层数和各层的维度具体应该设置多少才能提高精准度我也不知道,还希望有同学能给予我指导。
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self,x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = (self.l5(x))
return x注:如果按照这个代码跑出来的结果会显示RuntimeError: mat1 and mat2 shapes cannot be multiplied。原因是进行loss(model(train_loader),result)的时候,trainloader这个对象中封装着标签,c*w*H的张量,而第一层的输入要是1*784的维度,所以要在forward函数中加入x.view(-1,784)
作用是将x按照sum/784 *784自动填充成这个维度的矩阵。其中-1表示按照784自动填充分配行数。
四:损失函数和优化器的选择
model = Model()
loss = torch.nn.CrossEntropyLoss()
opt = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
这里我要说一下momentum,是动量优化算法,当我们在训练的过程中,由于训练集有限,学习率不能设置太高,否则会跳过最小点。而当小学习率的时候,逼近过程会发生抖动现象。如图

这种纵向抖动严重影响了计算效率,所以我们引入了动量优化算法,把一段时间内的结果做加权平均,这样可以在不影响横向移动的前提下减小抖动,优化过程。以下是我认为解释的比较通俗易懂的博客
(4条消息) SGD优化器Momentum的理解_什么都是已存在的博客-优快云博客_momentum优化器
五:循环的搭建
1:训练函数定义
if __name__ == '__main__':
for epoch in range(1000):
loss2 = 0.
for i, data in enumerate(train_loader, 0):
input, result = data
y_pred = model(input)
loss1 = loss(y_pred, result)
# print("epoch:",epoch)
# print("i",i)
# print("loss1:",loss1)
opt.zero_grad()
loss1.backward()
opt.step()
loss2 += loss1.item()
if i % 300 == 299:
loss3 = loss2 / 300
print("epoch=%d,i = %d" % (epoch,i))
print("loss_mean=",loss3)
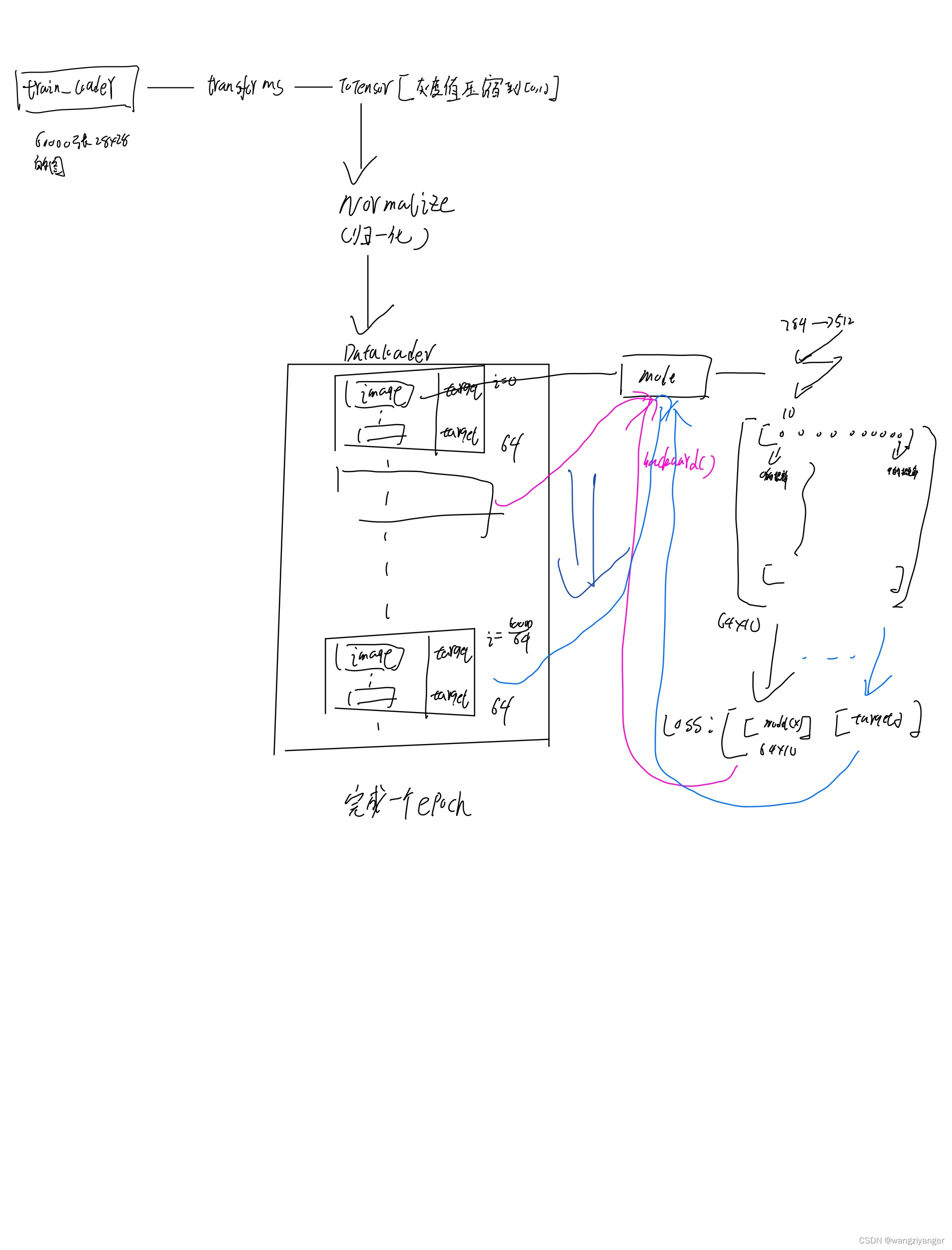
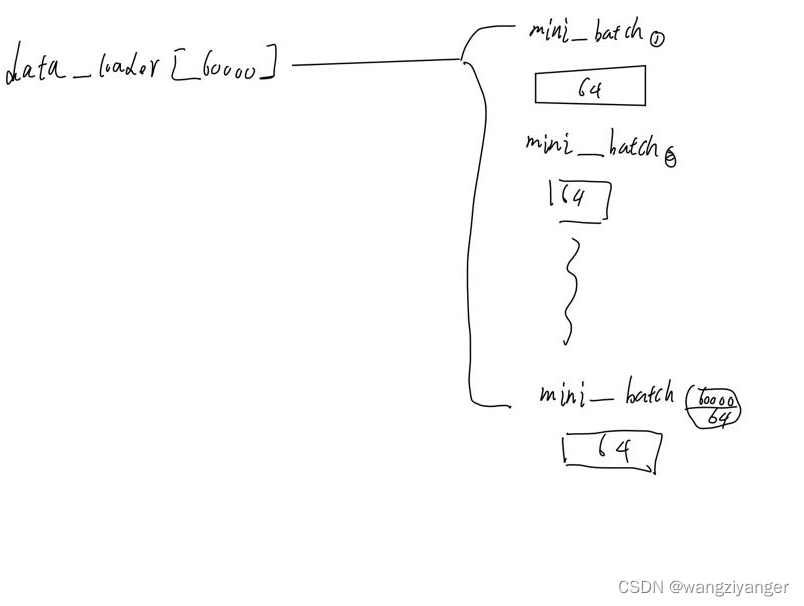
loss2 = 0.一开始我分不清楚,epoch,i(index),data之间的关系。我用图片表达。训练集一共包含了 60,000 张图像和标签,而测试集一共包含了 10,000 张图像和标签。epoch记录的是所有数据遍历一遍的次数;那么index记录的就是现在训练的是第几个minibatch。每个minibatch中有64条数据,每条数据是一个28*28的矩阵,所以前面说的如果直接用model(data)的话每层输入只能是一维的,但是data是高维的,要用view()降成一维的。Loss输出的是这64张照片在当前权重下的交叉熵值。
在minist的训练集里面,已经分装好数据和标签,所以直接用i,data来记录enumerate()出来的序号和打包好的tensor即可。这里加入的 if i % 300的判断语句的作用是按照300个minibatch一组来看,因为如果64个64个看没有必要。一共937个index,看的数据太多了。
2:测试函数定义
import torch
a = torch.randn(3,3)
x,y = torch.max(a,0)
print(a)
print(x,y)
在max(a,0)中,0表示每一列中最大的,1代表每一行中最大的,返回两个值,第一个是最大值的数,第二个是最大数的索引。
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,_,是占位符表示有值但是用不到
print(outputs.data)
print(predicted) 

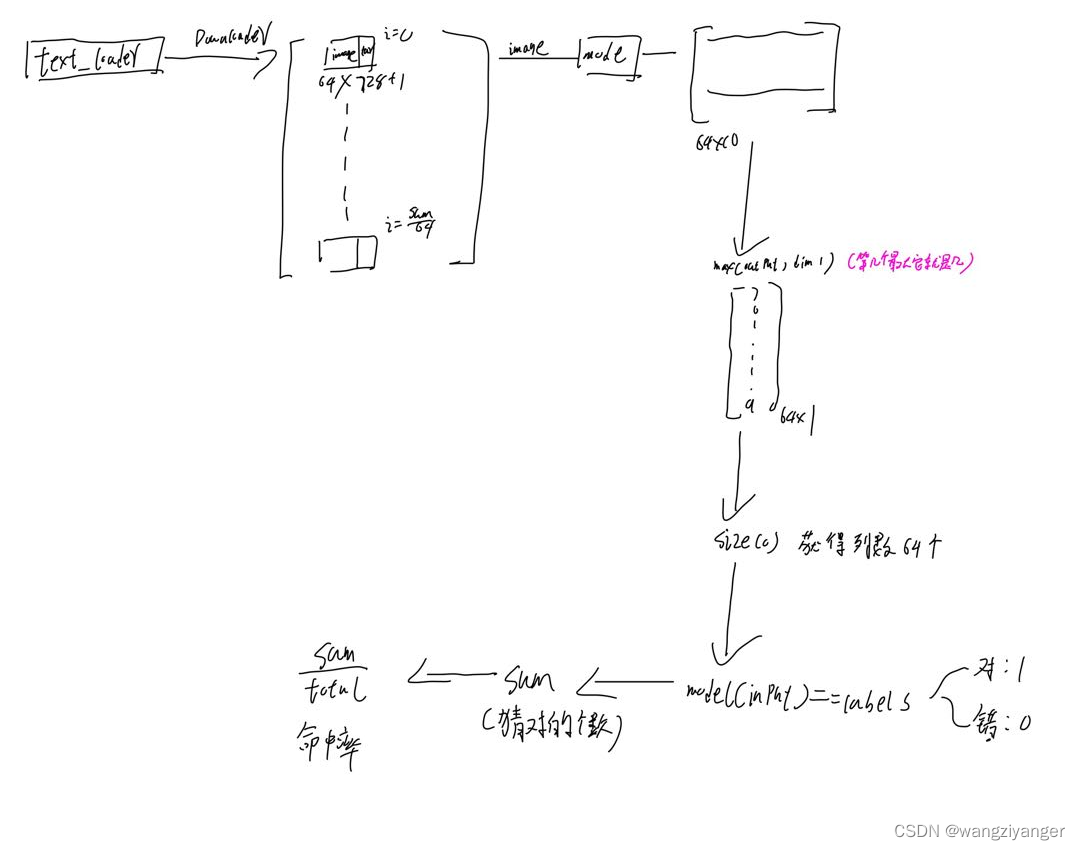
可以看出model(images)输出的是64*10的矩阵,64代表64张图片,单行中的每一列元素从左到右意味着这张图片是0—9的概率分别是多少。然后利用与label做==判断,是返回1值,不是返回0,加在一起表示的是一共猜对了几个,再利用label.size(0),其中0表示列数,1表示行数。做除法表示命中率是多少。
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images,index = data
output = model(images)
_, x = torch.max(output.data,dim=1)#列是第0个维度,行是第1个维度
y = index.size(0)
total += y
correct += (x == index).sum().item()
print("正确率= %d%%" % (correct / total * 100))with 的作用就是在进入with后面的一系列操作之后,无论是否报错都会关闭这个程序释放内存。with torch.no_grade是大多是进行测试集的时候都需要加上的,因为这样可以强制要求model()的时候不生成计算图,加快算速,释放内存。(注:如果去除了也能得到正确率97%,但是时间会长一些)_, x这是因为torch.max(a,dim=b)会返回两个值,一是最大值的索引,即哪一个数最大,二是返回数值,即这个最大的数等于几。_,是占位符,表示我们知道这里有一个数,但是用不到它。
还要注意
print('accuracy on test set: %d %% ' % (100 * correct / total))
这一条要写在for循环之外,否则每一张图像的正确率都会被输出。
六:整体代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1,784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
# with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度,_,是占位符表示有值但是用不到
# print(outputs.data)
# print(predicted)
# print(labels.size(0))
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()


















 5093
5093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









