




摘要:
翻译
在这项工作中,我们提出了一种高效、准确的单目3D单次检测框架。大多数成功的 3D 检测器将 3D 边界框到 2D 框的投影约束作为重要组件。2D 盒的四个边仅提供四个约束,并且 2D 检测器的误差很小,性能会急剧下降。与这些方法不同的是,我们的方法预测了图像空间中三维边界框的九个透视关键点,然后利用三维和二维透视的几何关系来恢复三维空间中的维度、位置和方向。在这种方法中,即使对关键点的估计非常嘈杂,也可以稳定地预测物体的属性,这使我们能够以较小的架构获得快速的检测速度。训练我们的方法仅使用对象的 3D 属性,不需要外部网络或监督数据。我们的方法是第一个用于单目图像3D检测的实时系统,同时在KITTI基准测试中实现了最先进的性能。
代码将于 https://github.com/Banconxuan/RTM3 发布
摘要总结:
- 与传统方法不同,该方法不是直接利用 2D 边界框到 3D 边界框的投影关系,而是预测 3D 边界框在图像空间中的 9 个透视关键点。这种方法更加稳定,即使关键点预测存在噪声,也能准确恢复 3D 属性。
- 该方法只需要利用 3D 物体属性进行训练,不需要外部网络或额外的监督数据,训练更加简单高效。
- 该方法实现了真正的实时性能,在 KITTI 基准测试中达到了最先进水平,在速度和准确度方面都有突出表现。
- 该方法只使用了常规的卷积和上采样操作,以及简单的几何模块(SVD),易于部署和加速,具有较小的模型体积。
介绍:
翻译
3D目标检测是自动驾驶中场景感知和运动预测的重要组成部分[2,10]。目前,大多数强大的3D探测器都严重依赖3D激光雷达激光扫描仪,因为它可以提供场景位置[9,48,43,31]。然而,基于激光雷达的系统价格昂贵,不利于嵌入到当前的车辆形状中。相比之下,单目相机设备更便宜、更方便,这使得它在许多应用场景中越来越受到关注[7,28,42]。在本文中,范围我们的研究在于仅从单目RGB图像进行3D物体检测。
单目三维目标检测方法根据训练数据类型大致可分为两类:一类利用复杂特征,如实例分割、车辆形状先验甚至深度图,在多级融合模块中选择最佳方案[7,8,42]。这些特性需要额外的注释工作来训练一些独立网络,这将在训练和推理阶段消耗大量的计算资源。另一个仅使用2D边界框和3D对象的属性作为监督数据[35,4,22,44]。在这种情况下,一个直觉的想法是建立一个深度回归网络来直接预测对象的 3D 信息。由于搜索空间很大,这可能会导致性能瓶颈。出于这个原因,最近的工作已经明确指出,从3D盒子中应用几何约束顶点到2D盒边,以优化或直接预测对象参数[30,25,4,22,28]。然而,2D 边界框的 4 条边仅提供 4 个恢复 3D 边界框的约束,而 3D 边界框的每个顶点可能对应于 2D 框中的任何边,这将需要 4,096 次相同的计算才能得到一个结果 [28]。同时,对2D盒的强烈依赖会导致3D检测性能急剧下降,而对2D探测器的预测甚至有轻微的误差。因此,这些方法大多利用两级检测器[12,11,34]来保证二维盒预测的准确性,这限制了检测速度的上限。
当前缺陷
- 复杂特征和多级融合:一些方法利用复杂特征,如实例分割、车辆形状先验和深度图等,在多级融合模块中选择最佳方案。然而,这些特征需要额外的注释工作来训练独立网络,并在训练和推理阶段消耗大量的计算资源。
- 深度回归网络:另一些方法仅使用2D边界框和3D对象的属性作为监督数据,建立深度回归网络来直接预测对象的3D信息。然而,由于搜索空间很大,这可能导致性能瓶颈。
- 几何约束和顶点匹配:最近的工作提出从3D边界框中应用几何约束将顶点匹配到2D边界框边,以优化或直接预测对象参数。然而,2D边界框的四条边仅提供有限的约束条件,而每个3D边界框顶点可能对应于2D框中的任何边,这需要大量的计算来得到结果。
- 二维框的依赖和性能下降:对2D边界框的强烈依赖会导致3D检测性能急剧下降,即使对于2D探测器的轻微误差也会造成影响。为了保证二维框预测的准确性,很多方法采用两级检测器,但这限制了检测速度的上限。
在本文中,我们提出了一种高效、准确的单目3D检测框架,该框架适用于不依赖2D探测器的3D检测。该框架可分为两个主要部分,如图1所示。首先,我们执行一个阶段全卷积架构来预测 9 个 2D 关键点,这些关键点是 8 个顶点和 3D 边界框中心点的投影点。这 9 个关键点在 3D 边界框上提供了 18 个几何约束。受CenterNet[47]的启发,我们对8个顶点和中心点之间的关系进行建模,以解决关键点分组和顶点顺序问题。采用SIFT、SUFT等传统关键点检测方法[26,1]计算图像金字塔求解尺度不变问题。CenterNet 使用类似的策略作为后处理步骤,以进一步提高检测准确性,从而减慢推理速度。需要注意的是,二维目标检测中的特征金字塔网络(FPN)[23]不适用于关键点检测网络,因为在小尺度预测的情况下,相邻的关键点可能会重叠。我们提出了一种新颖的多尺度金字塔关键点检测来生成尺度空间响应。关键点的最终激活图可以通过软权金字塔获得。给定 9 个投影点,下一步是最小化由对象的位置、尺寸和方向参数化的 3D 点透视的重新投影误差。将重投影误差表述为se3空间中多元方程的形式,可以准确高效地生成检测结果。我们还讨论了不同的先验信息对基于关键点的方法的影响,例如维度、方向和距离。获取此信息的前提条件是不要增加过多的计算量,以免影响最终的检测速度。我们将这些先验和重投影误差项建模为整体能量函数,以进一步改进 3D 估计。
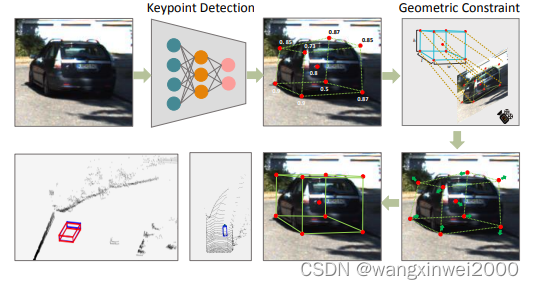
根据文中的描述,基于透视投影几何约束优化 3D 边界框参数的具体原理如下:
透视投影模型:
3D 物体的 8 个顶点和中心点在 2D 图像上有对应的投影点这些投影点与 3D 坐标之间存在透视投影关系,可以通过相机参数表示
重投影误差优化:
给定 9 个 2D 投影关键点(8 个顶点 + 1 中心点)目标是找到 3D 物体的位置、尺寸和朝向参数,使得 3D 点投影到 2D 平面的误差最小可以将这个过程建模为一个优化问题,最小化 3D 点在 2D 平面的重投影误差
几何约束建模:
由于 9 个关键点提供了 18 个几何约束,可以帮助更好地约束 3D 属性的估计这些几何约束包括物体尺寸、方向和中心点位置等先验信息将这些先验约束和重投影误差项整合到一个整体的能量函数中优化
高效优化求解:
将重投影误差表述为 SE(3) 空间中的多元方程形式利用高效的数值优化算法,可以快速准确地求解 3D 边界框参数
kitti相机参数补充
calib文件中P0, P1, P2, P3 是相机矩阵,描述了从3D世界坐标系到2D图像坐标系的投影变换关系。它们的差异主要体现在:
- &nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5033
5033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









