




 本文介绍了Eformer在医学图像去噪领域的创新,使用Transformerblock和Sobel-Feldman算子增强边缘,配合残差学习策略,实现在AAPM数据集上的高PSNR、RMSE和SSIM。模型灵感源自ViT的patchembedding,借鉴了Uformer的局部注意力结构。
本文介绍了Eformer在医学图像去噪领域的创新,使用Transformerblock和Sobel-Feldman算子增强边缘,配合残差学习策略,实现在AAPM数据集上的高PSNR、RMSE和SSIM。模型灵感源自ViT的patchembedding,借鉴了Uformer的局部注意力结构。
作者在摘要中提到,Eformer使用了用于医学图像去噪的 Transformer block构建Encoder-Decoder Net。
Transformer block中使用了基于非重叠窗口的自注意力,这可以降低计算要求;
结合了可学习的 Sobel-Feldman 算子用以增强图像边缘,并配套了有效的方法将它们连接到架构的中间层。
在AAPM数据集上实现了43.487 PSNR、0.0067 RMSE 和 0.9861 SSIM的成绩。
介绍
作者提到他们的想法受益于ViT的 patch embedding(块编码)操作,随即提到本论文和核心点:
1. 将可学习的 Sobel 滤波器用于边缘增强,从而提高了整体架构的性能。
2. 按照残差学习范式对网络进行了广泛的训练。为了证明残差学习在图像去噪任务中的有效性,作者还使用定性方法展示了结果,其中我们的模型直接预测去噪图像。在医学图像去噪中,残差学习明显优于传统学习方法,在传统学习方法中,直接预测去噪图像变得类似于制定恒等映射。
相关工作
作者在此列举前人贡献,为老生常谈,但有一点值得注意:作者的idea受到了一种去噪Transformer -- Uformer的启发,它在前馈网络中采用了基于非重叠窗口的自注意力和深度卷积来有效的捕获局部的上下文信息。
而作者自述的贡献是:他们用了一种新颖的方式集成了边缘增强模块和类似于Uformer的架构。
方法
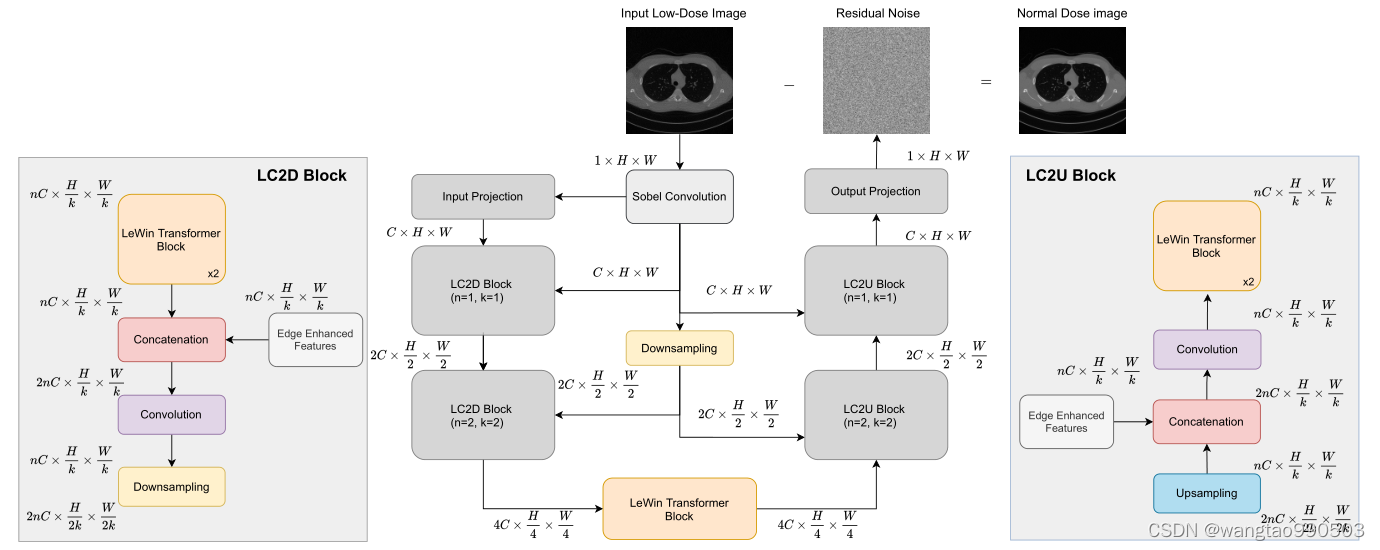
3.1. Sobel-Feldman Operator:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 612
612




 到【灌水乐园】发言
到【灌水乐园】发言







