




【机器学习24】-模型选择、误差评估
根据三张图片的核心内容,以下是关于模型选择、误差评估及神经网络架构选择的系统性总结与解题思路:
1. 误差评估(图1)
核心公式:
• 训练误差 ( J_{\text{train}} ):评估模型在训练集上的拟合程度。
J
train
(
w
,
b
)
=
1
2
m
train
∑
i
=
1
m
train
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
J_{\text{train}}(\mathbf{w}, b) = \frac{1}{2m_{\text{train}}} \sum_{i=1}^{m_{\text{train}}} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})^2
Jtrain(w,b)=2mtrain1i=1∑mtrain(fw,b(x(i))−y(i))2
• 交叉验证误差 ( J_{\text{cv}} ):用于调参和模型选择(防止过拟合)。
J
cv
(
w
,
b
)
=
1
2
m
cv
∑
i
=
1
m
cv
(
f
w
,
b
(
x
cv
(
i
)
)
−
y
cv
(
i
)
)
2
J_{\text{cv}}(\mathbf{w}, b) = \frac{1}{2m_{\text{cv}}} \sum_{i=1}^{m_{\text{cv}}} (f_{\mathbf{w},b}(\mathbf{x}_{\text{cv}}^{(i)}) - y_{\text{cv}}^{(i)})^2
Jcv(w,b)=2mcv1i=1∑mcv(fw,b(xcv(i))−ycv(i))2
• 测试误差 ( J_{\text{test}} ):最终评估模型泛化能力。
J
test
(
w
,
b
)
=
1
2
m
test
∑
i
=
1
m
test
(
f
w
,
b
(
x
test
(
i
)
)
−
y
test
(
i
)
)
2
J_{\text{test}}(\mathbf{w}, b) = \frac{1}{2m_{\text{test}}} \sum_{i=1}^{m_{\text{test}}} (f_{\mathbf{w},b}(\mathbf{x}_{\text{test}}^{(i)}) - y_{\text{test}}^{(i)})^2
Jtest(w,b)=2mtest1i=1∑mtest(fw,b(xtest(i))−ytest(i))2
关键点:
• 所有误差均基于平方损失(适用于回归问题)。
• 训练集用于拟合参数,交叉验证集用于选择模型复杂度,测试集仅用于最终评估。
2. 模型选择:多项式回归(图2)
问题描述:
选择多项式回归的最佳次数 ( d )(从 ( d=1 ) 到 ( d=10 )),模型形式为:
f
w
,
b
(
x
)
=
w
1
x
+
w
2
x
2
+
⋯
+
w
d
x
d
+
b
f_{\mathbf{w},b}(x) = w_1x + w_2x^2 + \cdots + w_dx^d + b
fw,b(x)=w1x+w2x2+⋯+wdxd+b
步骤:
- 训练不同复杂度的模型:
• 对每个 ( d ),用训练集拟合参数 w ( d ) , b ( d ) \mathbf{w}^{(d)}, b^{(d)} w(d),b(d)。 - 计算交叉验证误差 J cv ( w ( d ) , b ( d ) ) J_{\text{cv}}(\mathbf{w}^{(d)}, b^{(d)}) Jcv(w(d),b(d))。
- 选择最优
d
d
d):
• 图中选择 ( d=4 )(即 w 1 x + ⋯ + w 4 x 4 + b w_1x + \cdots + w_4x^4 + b w1x+⋯+w4x4+b),因其交叉验证误差 J cv ( w ( 4 ) , b ( 4 ) ) J_{\text{cv}}(\mathbf{w}^{(4)}, b^{(4)}) Jcv(w(4),b(4)) 最小(黄色高亮)。 - 最终评估:
• 使用测试集计算泛化误差 J test ( w ( 4 ) , b ( 4 ) ) J_{\text{test}}(\mathbf{w}^{(4)}, b^{(4)}) Jtest(w(4),b(4))(蓝色圈出)。
注意事项:
• 避免选择 ( d ) 过大(如 ( d=10 )),否则会过拟合(高方差)。
• 交叉验证误差是模型选择的核心依据。
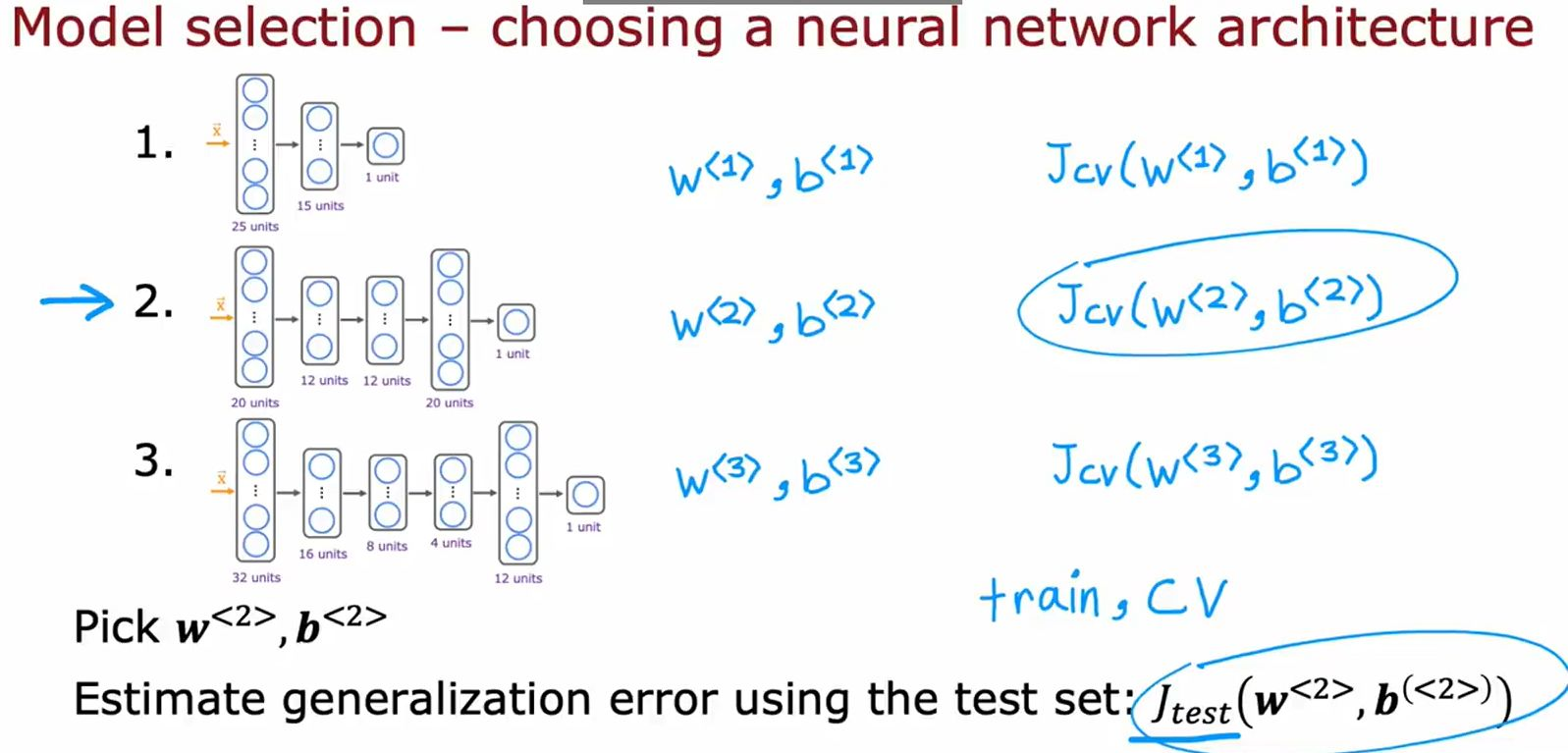
3. 模型选择:神经网络架构(图3)
问题描述:
从3种神经网络架构中选择最佳结构,依据交叉验证误差 ( J_{\text{cv}} )。
候选架构:
- 架构1:单隐藏层(25 units)→ J cv ( w ( 1 ) , b ( 1 ) ) J_{\text{cv}}(\mathbf{w}^{(1)}, b^{(1)}) Jcv(w(1),b(1))。
- 架构2:双隐藏层(12 units + 20 units)→ J cv ( w ( 2 ) , b ( 2 ) ) J_{\text{cv}}(\mathbf{w}^{(2)}, b^{(2)}) Jcv(w(2),b(2))。
- 架构3:三隐藏层(16 + 8 + 32 units)→ J cv ( w ( 3 ) , b ( 3 ) ) J_{\text{cv}}(\mathbf{w}^{(3)}, b^{(3)}) Jcv(w(3),b(3))。
选择步骤:
- 训练所有架构,记录交叉验证误差。
- 选择 J cv J_{\text{cv}} Jcv 最小的架构(图中选择架构2)。
- 用测试集评估泛化误差 J test ( w ( 2 ) , b ( 2 ) ) J_{\text{test}}(\mathbf{w}^{(2)}, b^{(2)}) Jtest(w(2),b(2))。
关键点:
• 更深的网络不一定更好,需平衡复杂度和数据量。
• 交叉验证误差是判断过拟合/欠拟合的核心指标。
4. 解题思路总结
- 划分数据集:训练集(拟合参数)、交叉验证集(选择模型)、测试集(最终评估)。
- 评估误差:
• 训练误差低但验证误差高 → 过拟合(需简化模型或增加正则化)。
• 两者均高 → 欠拟合(需增加复杂度或特征)。 - 模型选择:
• 多项式回归:通过交叉验证选择最佳次数 ( d )。
• 神经网络:通过交叉验证选择层数和单元数。 - 最终验证:测试集仅用于最终报告,不参与任何调参或选择。
5. 常见问题与解决
• 过拟合:减少多项式次数 ( d )、使用正则化(L2)、减少神经网络单元数。
• 欠拟合:增加 ( d )、添加更多特征、增大神经网络规模。
示例决策流程:
训练模型 → 计算 J_train 和 J_cv → 选择 J_cv 最小的模型 → 用 J_test 验证泛化性
通过系统性地应用上述方法,可高效选择模型并评估其性能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









