




 本文深入探讨了神经网络的训练细节,包括集成模型的训练与测试策略,以及Dropout技术的原理与应用。解释了Dropout如何通过随机失活神经元减少过拟合,提升模型泛化能力。
本文深入探讨了神经网络的训练细节,包括集成模型的训练与测试策略,以及Dropout技术的原理与应用。解释了Dropout如何通过随机失活神经元减少过拟合,提升模型泛化能力。
神经网络训练细节part2下
- 集成模型
- dropout
集成模型
训练:单独训练多个模型
测试:采用多个模型的测试结果均值做为结果
可以提升2%。
单模型:在训练过程中设置检查点,然后验证验证集中的数据。
集成模型:在不同的模型中分贝设置检查点,然后用每个模型对验证集中的数据结果得到的均值作为验证结果。
dropout
随机失活:在前向传播和反向传播过程中,随机地使网络中的神经元输出为0。
p = 0.5 #随机失活概率
def train_step(X):
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p
H1 *= U1
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p
H2 *= U2
out = np.dot(W3, H2) + b3
随机失活为什么会取得较好的结果?(1)第一种解释:随机地让网络中的一部分神经元失活,降低了网络的表达能力,减少了网络过拟合的概率。强制地认为网络的表达能力是冗余的,被失活的神经元是冗余的。(2)第二种解释:每一次失活都相当于是得到了一个新的网络,相当于每一次在网络中采样一部分作为当前网络,这些网络的训练数据不同,但却共享着一部分权值(共享权值可以这样理解,比如第一层有4个神经元,第一个batch失活第一个神经元,得到网络1,然后训练网络,第二个batch失活第二个神经元,得到网络2,然后训练网络2,网络1训练后第二、三、四个神经元的参数更新,然后网络2训练的时候是在网络1的基础上训练的,即网络2训练时第三、四个神经元的参数与网络1训练后的参数相同。)所以相当于训练一个由很多小网络融合而成的集成网络。
测试时:全部的神经元都是存活的状态,相当于是没使用dropout。而训练时是以概率p失活神经元的。
如下图两个神经元:
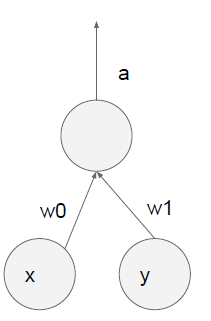
假设以p=0.5的概率随机失活神经元,测试时:a=w0*x+w1*y
而训练时,神经元失活的情况有四种,a的期望E(a)=0.5*0.5(w1*0+w2*y)+0.5*0.5(w1*0+w2*0)+0.5*0.5(w1*0+w2*0)+0.5*0.5(w1*x+w2*0)+0.5*0.5(w1*x+w2*y)=0.5(w1*x+w2*y)所以训练时a的期望值是测试时a的值得p=0.5倍。
所以为了弥补这种差异,要在测试时让输出值乘以p。
def predict(X):
H1 = np.maximum(0, np.dot(W1, X) + b1 ) * p
H2 = np.maximum(0, np.dot(W2, H1) + b2 ) * p
out = np.dot(W3, H2) + b3
反向失活:在失活中,训练过程和测试过程都要处理,且训练的输出期望值是测试输出的p倍,所以让测试的输出乘以p。还有一种方法就是反向失活,即在训练时让结果除以p,而不需要测试时做任何操作。同样弥补了差异。
p = 0.5 #随机失活概率
def train_step(X):
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = ( np.random.rand(*H1.shape) < p ) / p
H1 *= U1
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = ( np.random.rand(*H2.shape) < p ) / p
H2 *= U2
out = np.dot(W3, H2) + b3


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









