







 本文介绍了一种名为RFN的新型Encoder-Decoder架构,旨在解决多位置目标检测问题。通过提出RI和RS两个模块,分别处理特征映射的分类和回归问题,RFN在不同网络结构如VGG和ResNet101上展现出优越的检测性能,特别是在移动目标检测方面。
本文介绍了一种名为RFN的新型Encoder-Decoder架构,旨在解决多位置目标检测问题。通过提出RI和RS两个模块,分别处理特征映射的分类和回归问题,RFN在不同网络结构如VGG和ResNet101上展现出优越的检测性能,特别是在移动目标检测方面。
**论文地址:**http://arxiv.org/abs/1903.09839
Introduction
1 本文提出Encoder-Decoder architecture即RFN,解决多位置的目标检测;
2 提出了两个模块,第一:RI解决特征映射的分类问题;RS解决特征映射的回归问题;
3 分为两个单元;编码单元:为旋转的特征映射指定权重;解码单元:提取RI和RS的特征
背景介绍
结构
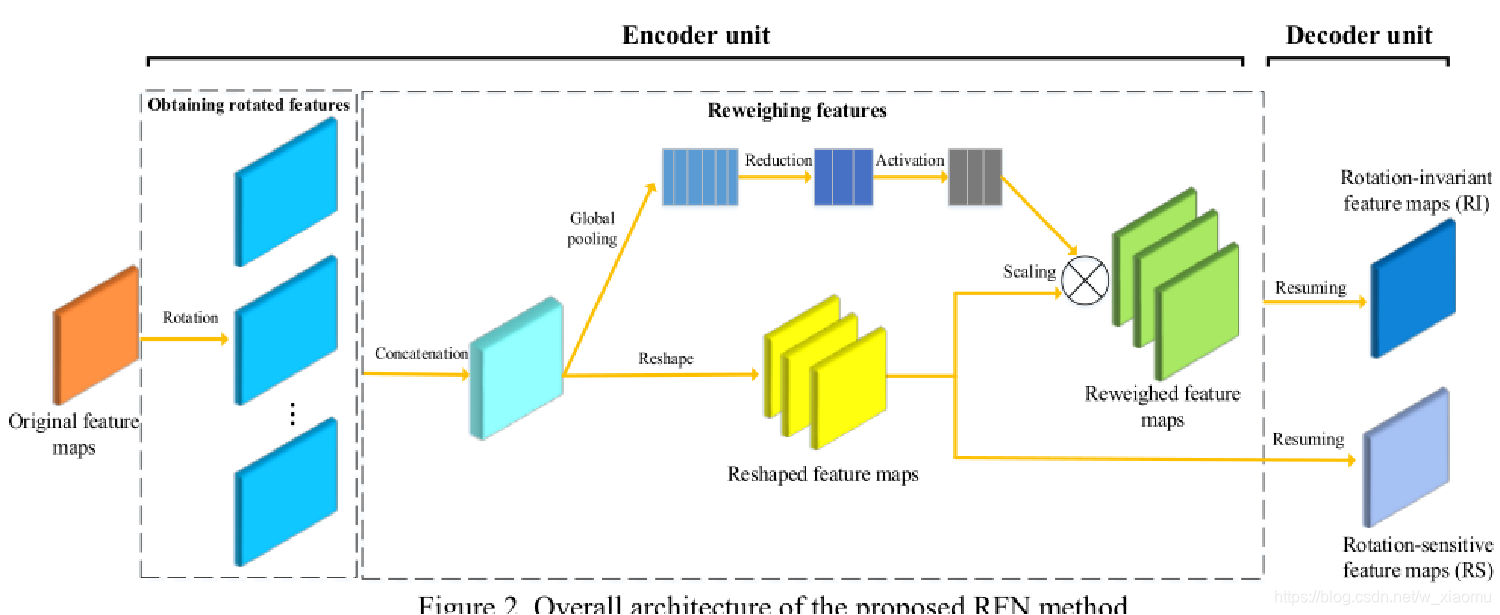
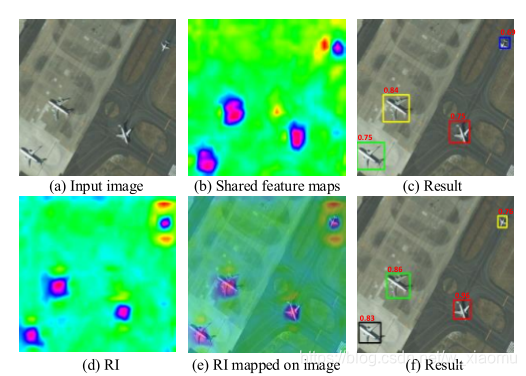
原始特征:从从RoI池化产生的特征作为输入的RFN;
Global pooling:目的是产生权重;
Reshape:为每个角度指定特征映射;
具体部分看论文,论文中有公式,该部分只是简单介绍。
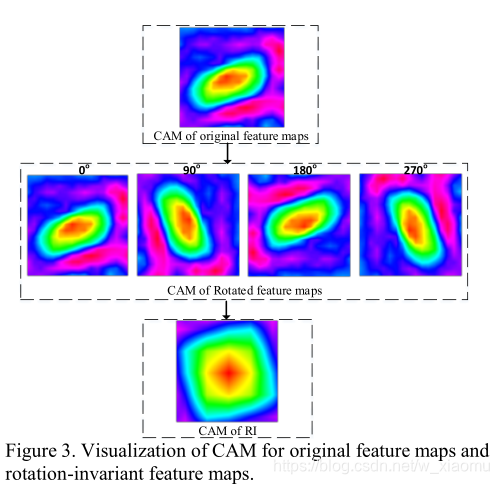
该图描述的是,原始的特征映射和旋转不敏感的特征映射;也就是从原始特征到Rotated 特征映射得到单个特征映射。
实验
1 参数 设定

该图表明的是,在实验过程需要设定的参数,然后执行实验、。
2 全局平均池化和Resuming操作的类型的实验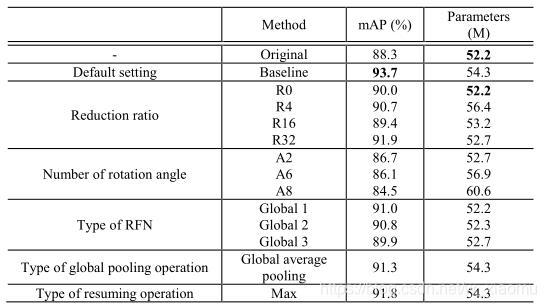
实验中,得到默认的设置 ,参数量增加不明显,显准确性要比之前的都好。
3 不同网络结构对比
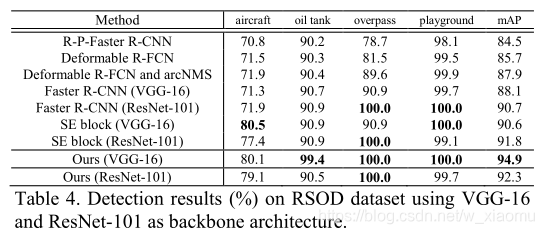
从图中可以得出,在不同backbone中,实验的结果也是不同,可以得出,本文提出的结构放入到vgg和resnet101中,大部分结构都要比之前的结构好。
总结:
本文主要提出了RI和RS;RS的作用是使边界框更为准确。使得目标检测更加准确。使用RFN网络 使得对移动的目标检测准确性更高。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









