



Concerto
Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations
https://pointcept.github.io/Concerto/
Abstract
人类可以从多模态的数据中学习到内在逻辑,从而可以通过单一模态进行认知还原,受到这一启发,Concerto将3D模态内蒸馏与2D-3D跨模态相结合,简单且有效。Concerto可以学习到更丰富且更连贯的空间特征,经过全量微调之后,可以在多个场景理解的benchmark实现SOTA。我们进一步提出了一种为时序点云为输入的空间理解任务的Concerto变体,以及将Concerto表示线性投影至CLIP语言空间的翻译器,从而实现了开放世界的感知。
Introduction
以自监督的方式学习强的空间表征是空间理解任务的基础,自监督学习的最新进展显着提高了两种主要空间模态的基本表示模型:2D 图像 和 3D 点云,不需要人工注释,这些模型通过能够大规模学习几何和语义,在各种下游任务中表现出强大的性能。但本文发现单独的图像或点云的自监督学习并不重叠,即将来自自监督图像模型的特征与点云自监督模型的特征相结合,可以提高空间表征能力,这说明两种模态捕获的信息是互补的,而非重复冗余的空间信息,因此本文的目标之一:使用多模态自监督学习获取更优的空间表征。
以人类比:人类对于抽象概念的学习是通过多感官协同完成的,通过反复的看到、接触和品尝,使大脑可以将苹果的几何形状、纹理、语义统一起来,而在认知形成后,可以通过任一模态被唤起,看到苹果的图像就可以想起其纹理和味道。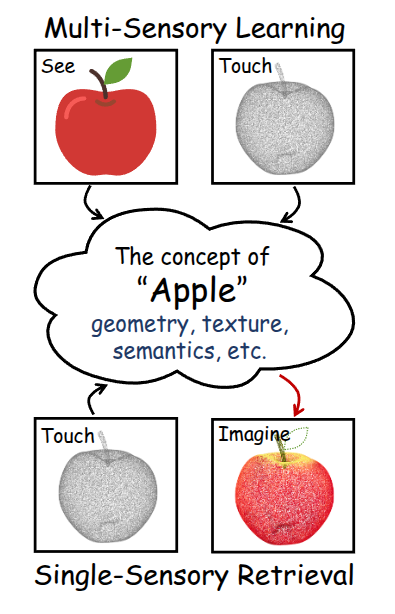
以此类比,我们将 2D-3D 联合自监督学习的 Concerto 组成,将点云-模态内自蒸馏 与从图像-点云的跨模态联合嵌入预测相结合。最终,共同完成自监督的PTv3模型,该模型在40k原始点云和300k图像上进行了预训练。此外,我们提出了 Concerto 的变体,通过前馈重建增加了一组额外的 50k 点云,其中 200k 对应图像从场景视频提取,专为基于视频的空间理解而量身定制。我们进一步提出了一种为时序点云为输入的空间理解任务的Concerto变体,以及将Concerto表示线性投影至CLIP语言空间的翻译器,从而实现了开放世界的感知。
Beyond Single Modality: Toward a New World of Representations
本节主要讨论两个问题:
- 是否存在比单模态学习更好的表征空间?
- 多模态自监督是否可以表达出概念的抽象语言?
为了验证是否可以有一个多模态融合学习下的更优表征空间,本文分别使用2D和3D的自监督模型在各自数据上进行训练,并通过深度信息和相机参数将2D特征变换到3D空间,与对应的3D特征进行特征级别的融合。实验证明,即便是最简单的线性组合的方式都优于单模态模型的性能: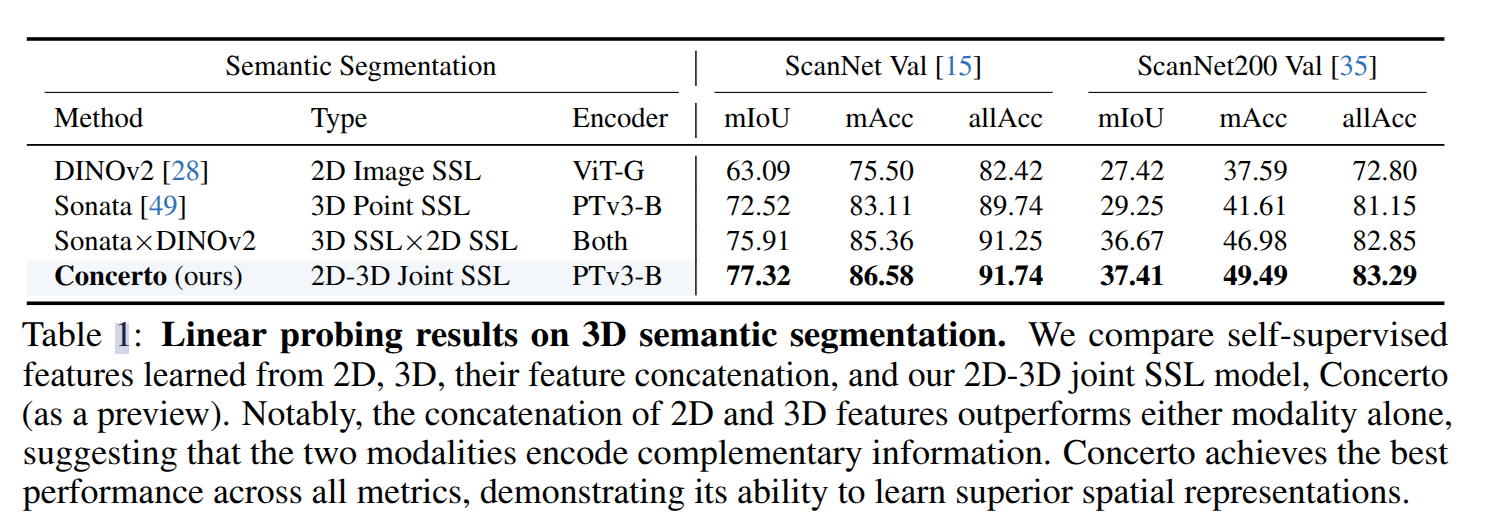
这说明不同模态数据间存在互补信息。
但是简单的将两种模态的数据进行拼接,从而产出一个更强的表征空间还远远不够。这并没有在训练过程中实现整合和多模态数据的协同,并没有发挥出多模态数据的全部潜力:不仅仅在维度上对数据进行对齐,而是要形成连贯的,有预测性的嵌入,可以从训练数据进行外推,学到真正的抽象概念。
尽管空间信息已经足够丰富,但想要学习到真正抽象的语言概念,还是建议将自监督表征的线性语义特征与语言空间特征将结合,如CLIP,从而扩展自监督模型的开放词集检测的能力。
Concerto: Joint 2D-3D Self-Supervised Learning
本节主要介绍Concerto的主要结构,大道至简,模型结构特意以最简单的方式设计,以突出多模态协同的潜力。
Intra-Modal Self-Distillation
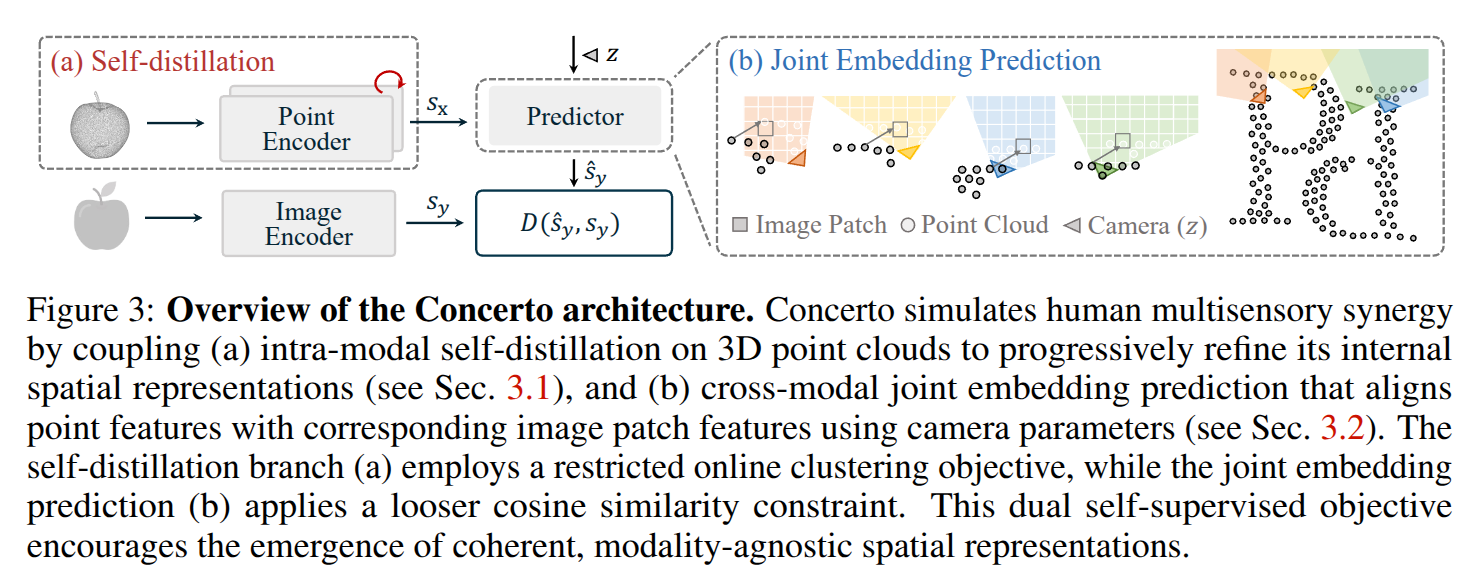
Concerto的主要目的是验证多模态训练的潜力,而非单一模态自监督模型的架构创新。因此点云部分的模型架构主要沿用了Sonata,实现点云表征的自蒸馏框架。主要聚焦在3D域,通过以师生范式训练PTv3来产生稳定且有预测性的特征。使用基于聚类的方法来提升不同视图下相同点云的一致性,从而优化学生编码器来匹配栋梁更新后的教师的输出。稀疏点云感知中的一个独特的挑战是几何连线,模型学到过多的低级别的几何曲线特征,但这些特征并不是学习得到的,而是通过点云算子的局部核的定义隐式引入的。Sonata 通过几个小的设计来缓解这个问题,这些设计掩盖了明确的空间信号并鼓励从输入特征中学习。这种自我驱动的细化过程允许模型从 3D 数据中内化几何和结构先验,形成 Concerto 中多模态学习的基础。
Cross-Modal Joint Embedding Prediction
本文引入了一个额外的跨模态自监督目标,持续促进图像自监督表示在点云领域的协同作用。设计理念与LeCun的联合嵌入预测架构(JEPA)的核心愿景一致,该架构倡导通过条件预测器预测跨模态的潜在表示来进行学习。其目标是预测与从自监督图像编码器(例如DINOv2)提取的相关像素嵌入相匹配的点云嵌入。经验上,我们发现余弦相似度为训练该预测分支提供了最有效的准则,通过应用强大的点云数据增强,并与DINOv2相比探索较不激进的图像增强,Concerto学习到了更具可推广性的表示。
在本文的实现中,将包含大量图像的场景数据切分为若干数据块,每个数据块由一帧点云和四张图像组成,对于图像数据较少的场景(比如5张),我们保留原始数据集的划分,如图所示,分别从点云编码器和图像编码器得到对应的特征,结合相机参数输入δz\delta zδz得到特征级融合,将点云特征进行投影,通过的得到的深度与图像的深度真值误差比较,计算对应点云的可见度,对满足条件的点云特征进行融合计算,对于每个图像patch, 计算落入其中的点云特征的均值,最后计算融合特征与点云特征的余弦相似度。
Synergy Emerged from Joint Self-Supervised Learning
上面提到的融合方式的性能要优于简单的特征拼接,并且还支持没有成对的图像和点云的的训练,在不影响大规模 3D 数据集上可扩展性的情况下实现混合自监督学习。
Experiments
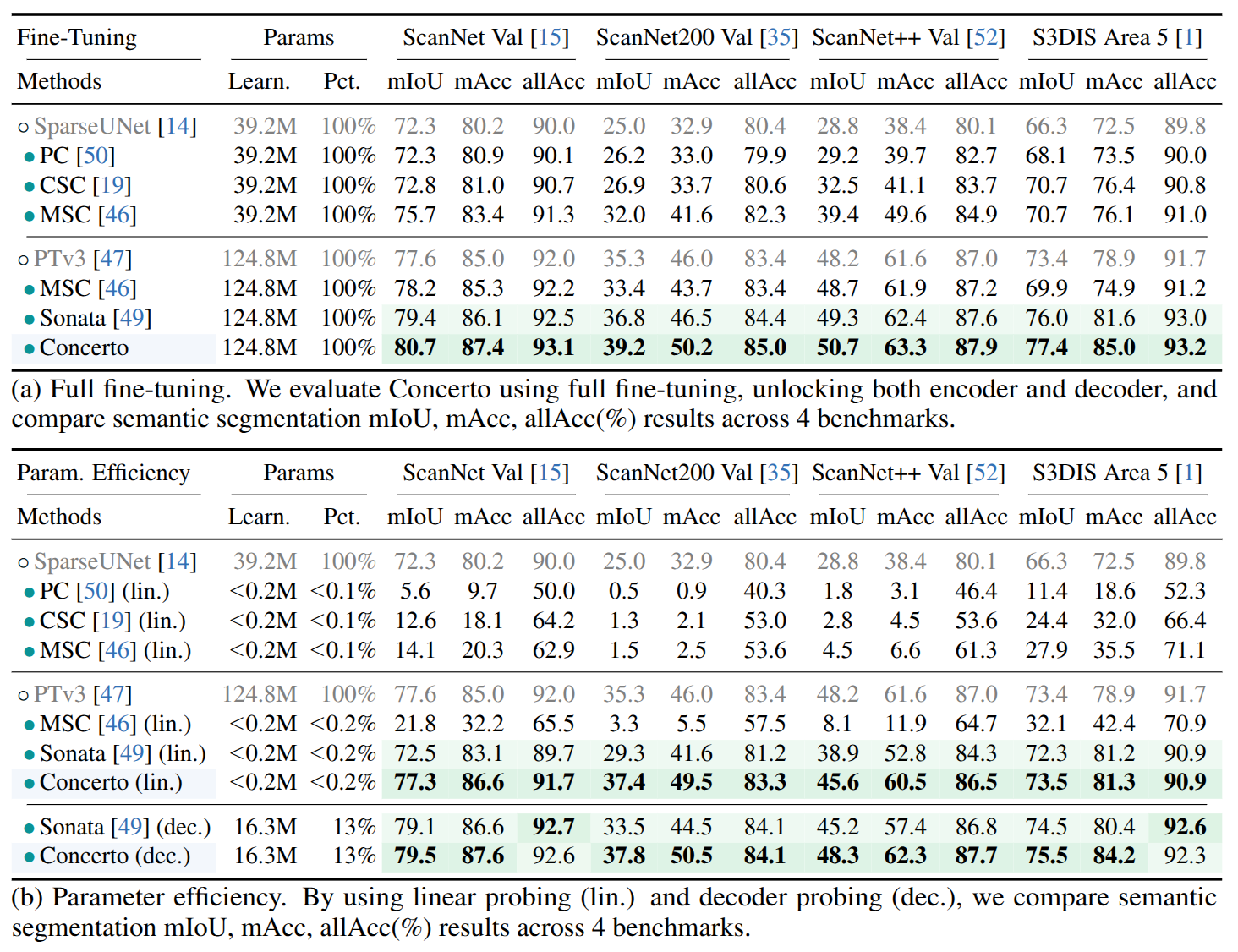
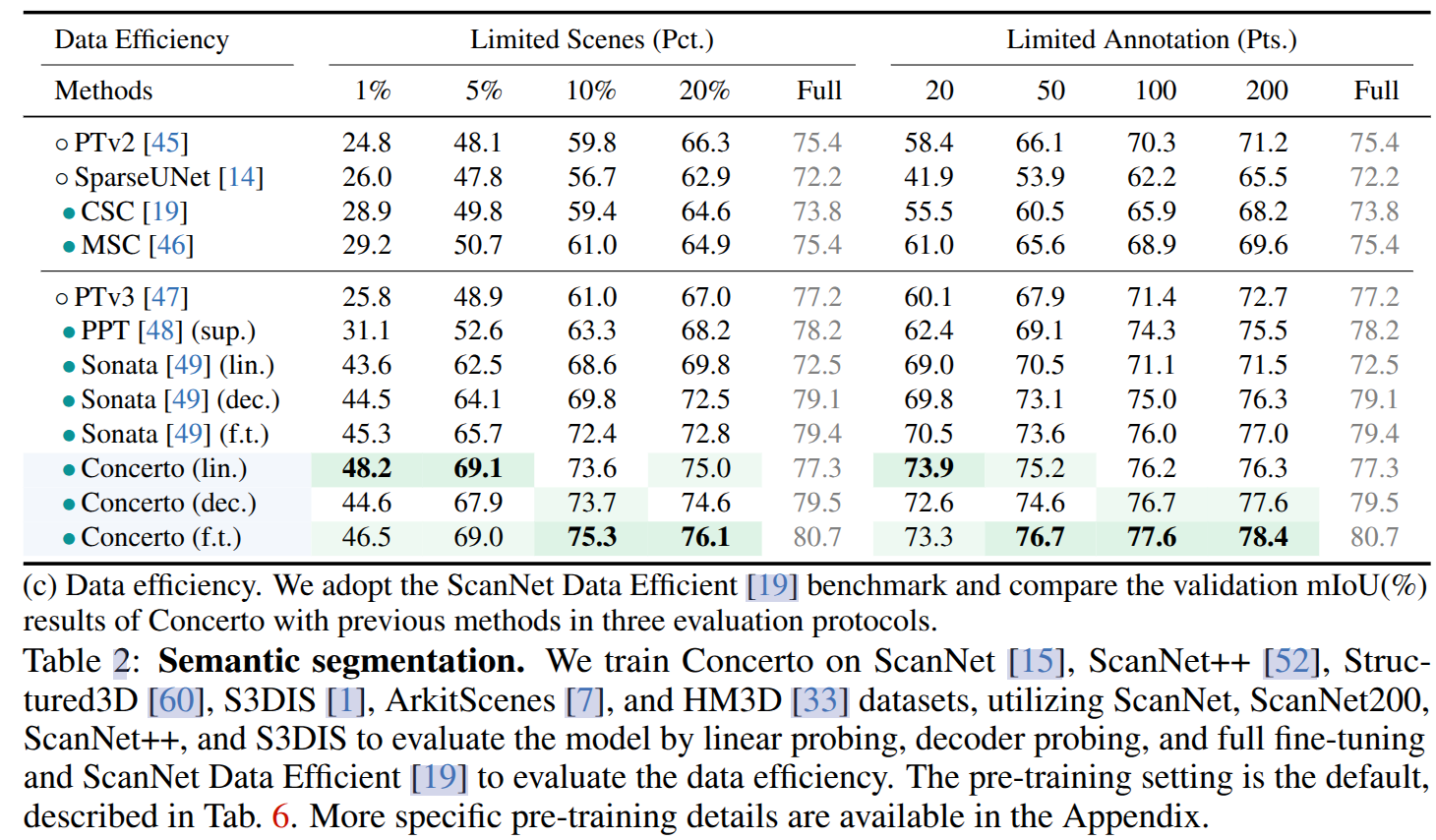

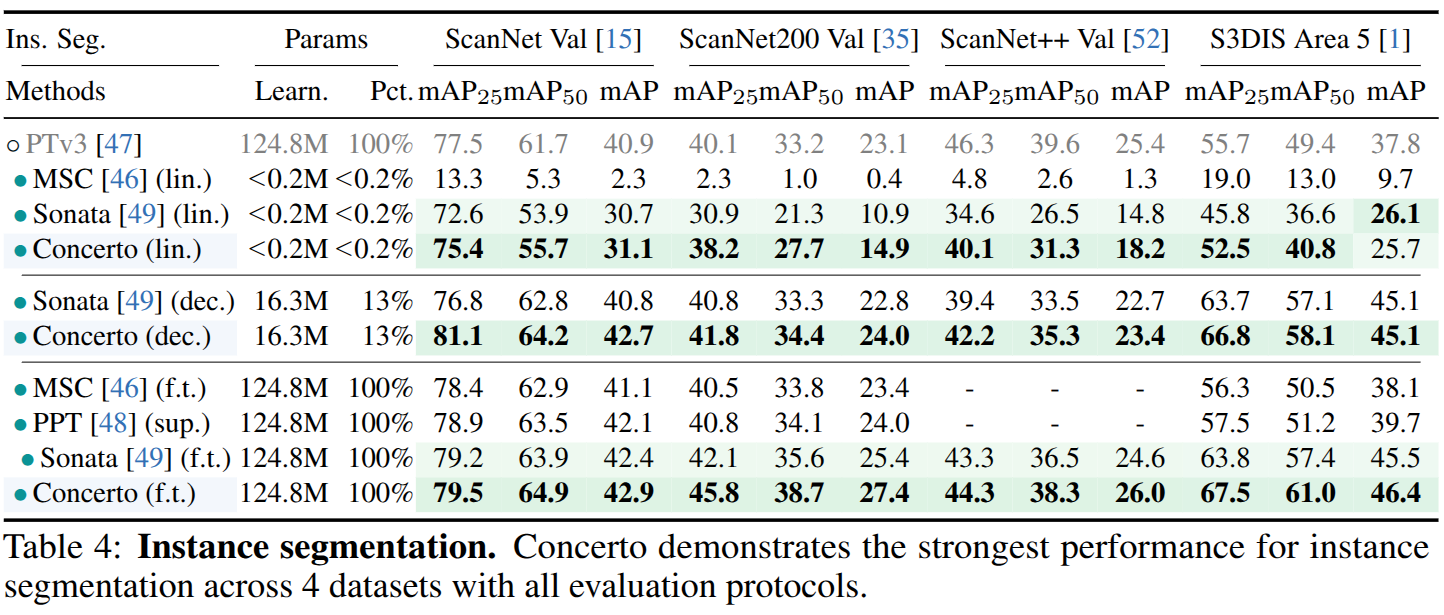
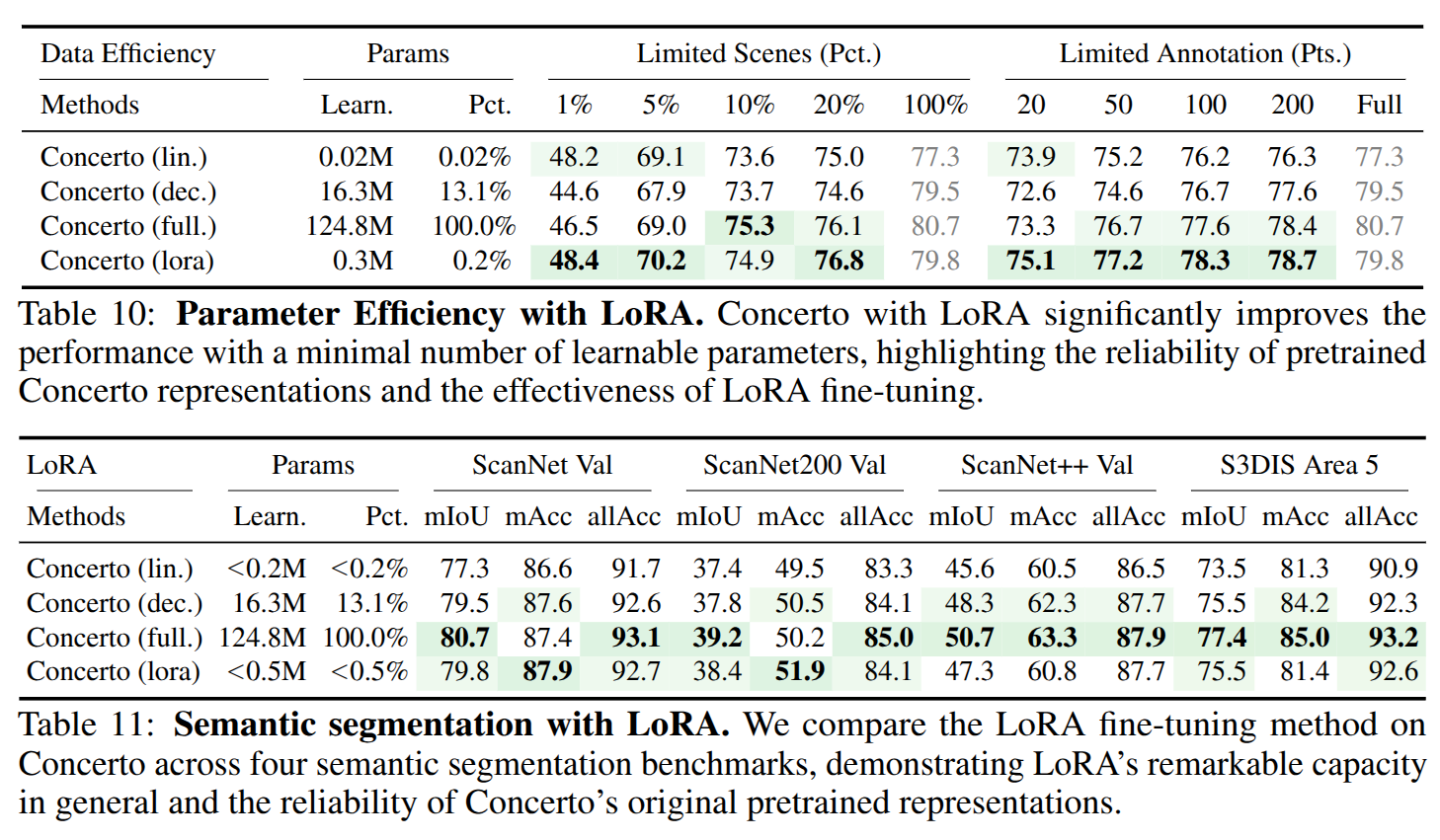
砖
感觉延续了这个团队一直的思路,点云感知模型的上限的瓶颈在数据和效率,一路从提升训练效率,跨数据集联合训练,自监督训练到这篇的跨模态自监督训练,跳出传统CV逻辑,充分借鉴图像基础大模型的思路,感觉是一种很值得点赞的实用主义。
作者也提到了本文在架构上并没有大的创新,更多的是跨模态自监督训练的思路验证,其实跨模态训练或者引入VFM已经不新鲜了,大体上的思路都是类似的, 都是将图像特征引入进来提升特征表征的能力,将稀疏的点云特征稠密化,同时也相当变相利用了大规模的图像数据集的凝练成果,而且确实是有效的。

















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









