



sam opt by torch
非常非常非常强烈建议大家去读原文
https://pytorch.org/blog/accelerating-generative-ai/
https://github.com/pytorch-labs/segment-anything-fast
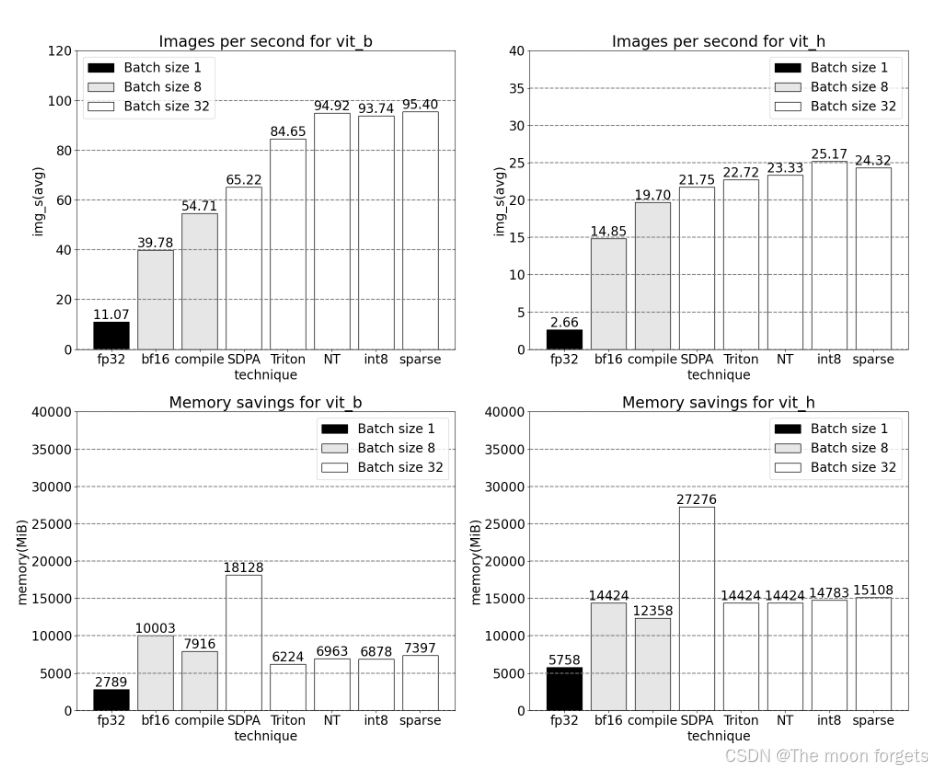
Optimizations
Baseline
原生SAM使用 float32 以及 batch size = 1。使用 PyTorch Profiler对内核进行跟踪,发现了两个可以进一步优化的地方:
- long calls to aten::index
由于tensor的index索引而产生的底层调用(例如[ ]),虽然aten::index本身的耗时很短,但是它会同时启动两个内核,从而导致 CUDA流同步(cudaStreamSynchronize)阻塞,CPU会等待GPU完成计算和流同步,导致空闲时间增加。 - matrix multiplication on GPU
在transformer-based 模型中常见的大矩阵相乘的时间损耗
Bfloat16 Half precision (+GPU syncs and batching)
- 为了减少大矩阵相乘的耗时,一个常见的做法就是使用半精度类型,使用 bfloat16
- 查找源码中存在GPU同步的地方,并试图将其移除
- q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
- k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
********************************************************************************
+ q_coords = torch.arange(q_size, device=rel_pos.device)[:, None] * max(k_size / q_size, 1.0)
+ k_coords = torch.arange(k_size, device=rel_pos.device)[None, :] * max(q_size / k_size, 1.0)
- point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
- point_embedding[labels == -1] = 0.0
- point_embedding[labels == -1] += self.not_a_point_embed.weight
- point_embedding[labels == 0] += self.point_embeddings[0].weight
- point_embedding[labels == 1] += self.point_embeddings[1].weight
********************************************************************************
+ point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
+ point_embedding = torch.where((labels == -1).unsqueeze(-1).expand_as(point_embedding),
torch.zeros_like(point_embedding) + self.not_a_point_embed.weight,
point_embedding)
+ point_embedding = torch.where((labels == 0).unsqueeze(-1).expand_as(point_embedding),
point_embedding + self.point_embeddings[0].weight,
point_embedding)
+ point_embedding = torch.where((labels == 1).unsqueeze(-1).expand_as(point_embedding),
point_embedding + self.point_embeddings[1].weight,
point_embedding)
进一步对耗时和资源进行跟踪,同时更改batch_size为8来更直观的进行对比
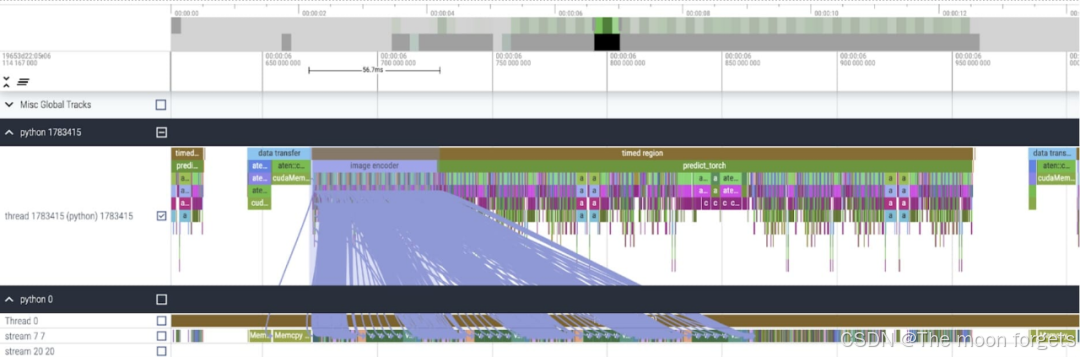
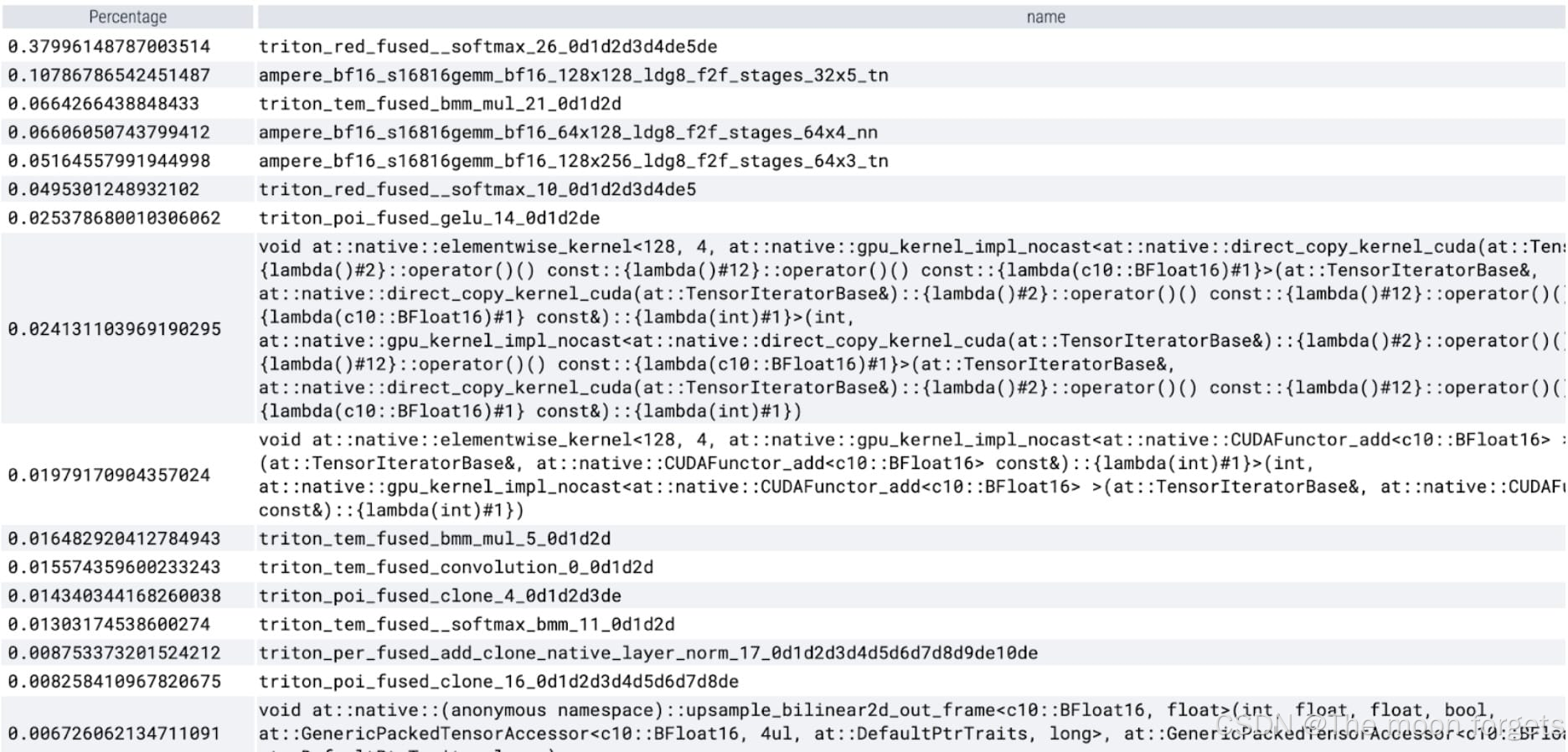
在查看每个内核所花费的时间时,现在 SAM 的大部分 GPU 时间都花费在逐元素内核(elementwise kernels)和 softmax 操作上。矩阵乘法的相对开销小了很多。
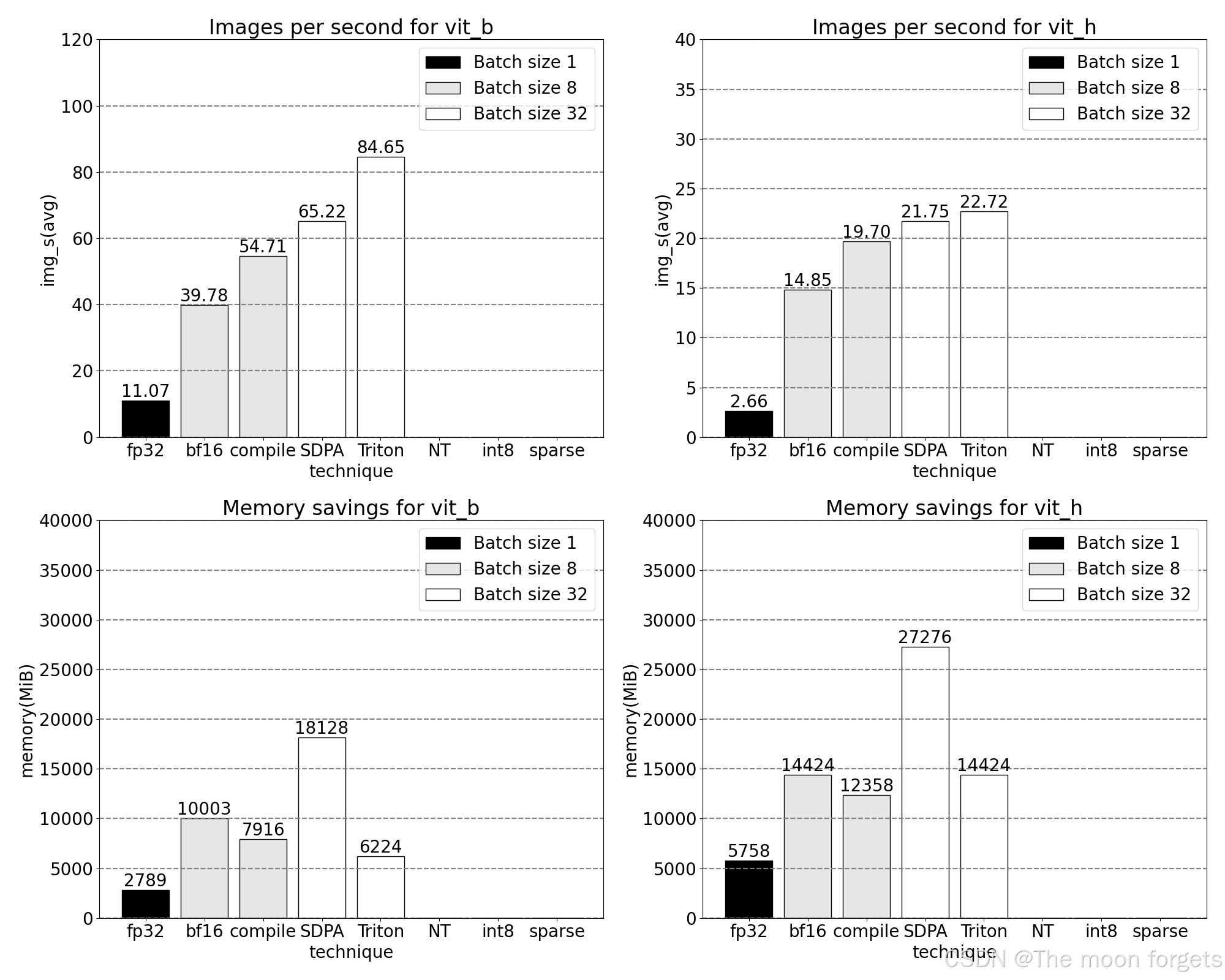
当前的优化速度已经3x了
Torch.compile (+graph breaks and CUDA graphs)
PyTorch 对 torch.compile 做了以下优化:
- Fusing together sequences of operations such as nn.LayerNorm or nn.GELU into a single GPU kernel that is called and
- Epilogues: fusing operations that immediately follow matrix multiplication kernels to reduce the number of GPU kernel calls.
通过这些优化可以减少GPU 全局内存往返次数(roundtrips),从而加快推理速度。
advance:
- 采用max-autotune模式,以获取最快的优化速度(编译时间最长,试图提供最快代码)
- 通过设置 TORCH_LOGS=‘graph_breaks,recompiles’ 来手动验证是否出现图中断或重新编译
- 通过zeros-padding来确保静态输入尺寸,从而避免重编译
predictor.model.image_encoder = torch.compile(
predictor.model.image_encoder,
mode=use_compile)
观测到softmax和GMM(General Matrix Multiply)占据了大量的计算时间以及现有的速度提升:
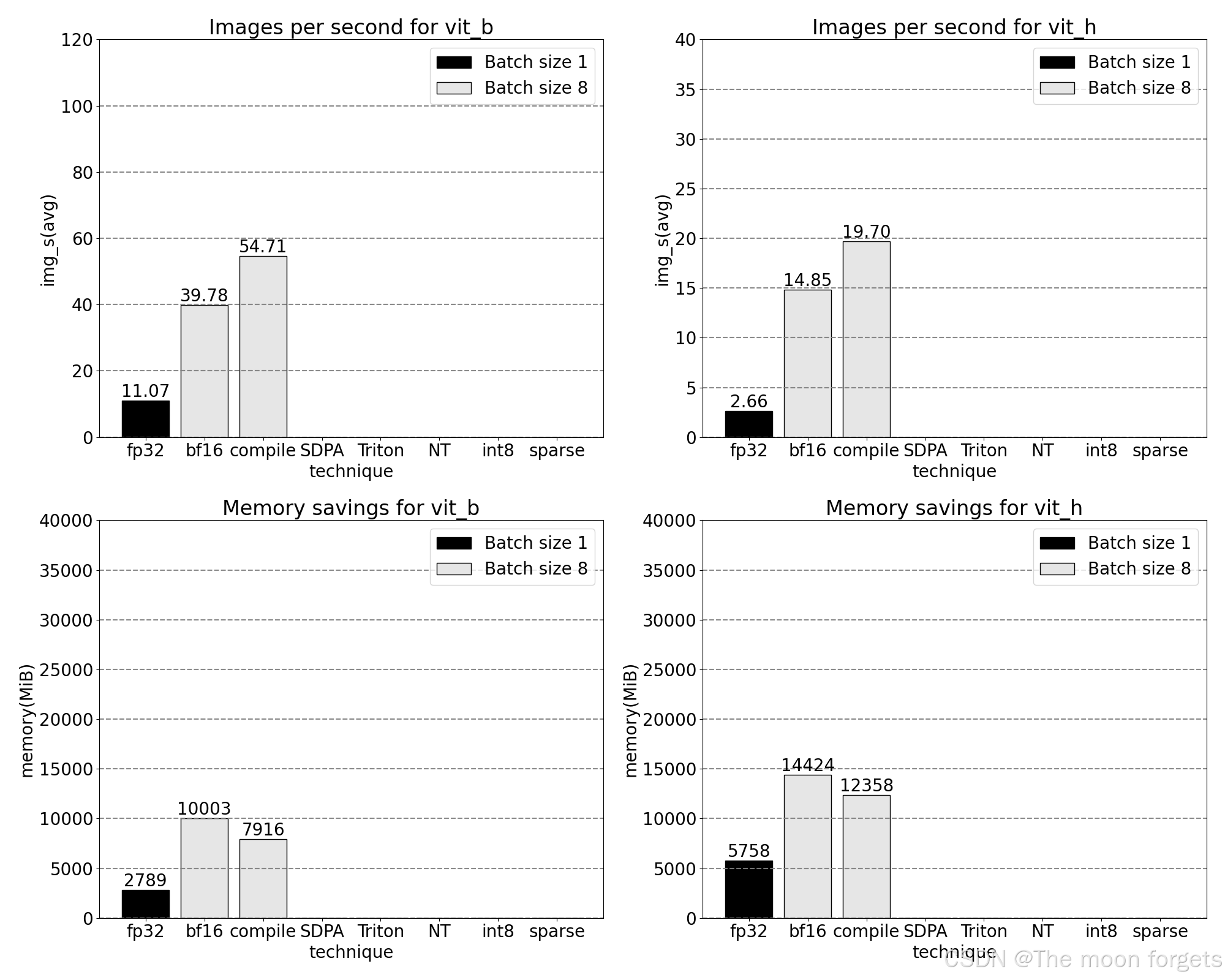
SDPA: scaled_dot_product_attention
接下来将解决注意力机制在transformer中的常见问题:计算损耗随序列长度呈二次方增长。
PyTorch 的 scaled_dot_product_attention 操作建立在 Flash Attention、FlashAttentionV2 和 xFormer 的内存高效注意力原理之上,从而可以显著加快 GPU 注意力的速度。
- attn = (q * self.scale) @ k.transpose(-2, -1)
- if self.use_rel_pos:
- attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
- attn = attn.softmax(dim=-1)
- x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
********************************************************************************
+ attn_bias = None
+ if self.use_rel_pos:
+ attn_bias = add_decomposed_rel_pos(q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
+ q = q.view(B, self.num_heads, H * W, -1)
+ k = k.view(B, self.num_heads, H * W, -1)
+ v = v.view(B, self.num_heads, H * W, -1)
+ attn_bias = attn_bias.view(B, self.num_heads, attn_bias.size(-1), attn_bias.size(-1))
+ x = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=attn_bias)
+ x = x.view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
- _, _, _, c_per_head = q.shape
- attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens
- attn = attn / math.sqrt(c_per_head)
- attn = torch.softmax(attn, dim=-1)
- # Get output
- out = attn @ v
********************************************************************************
+ out = torch.nn.functional.scaled_dot_product_attention(q, k, v)
现在可以看到内存高效的注意力内核占用了 GPU 上大量的计算时间:
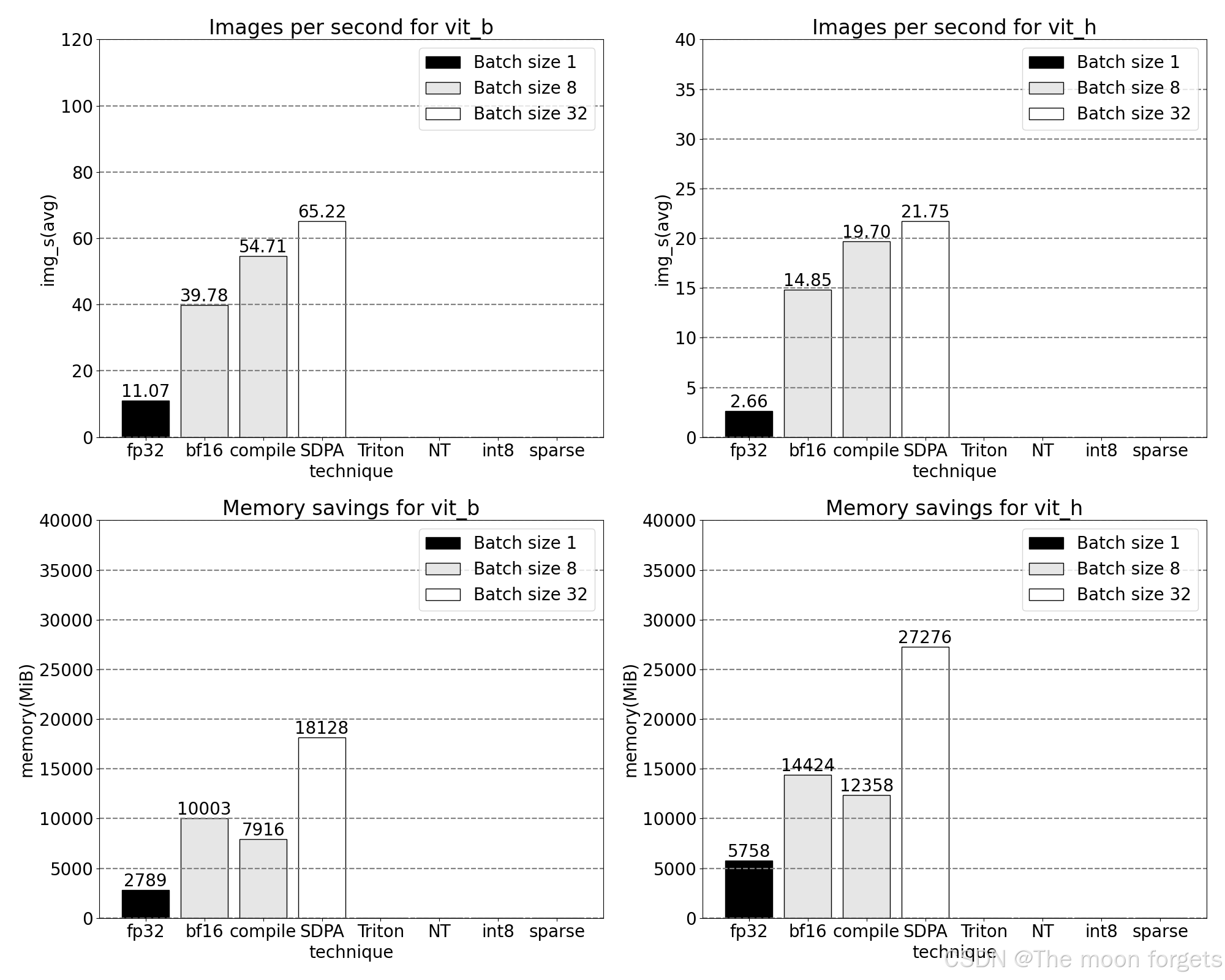
使用 PyTorch 的原生 scaled_dot_product_attention,可以显著增加批处理大小。下图为批大小为 32 及以上的变化。
Triton: Custom SDPA for fused relative positional encoding
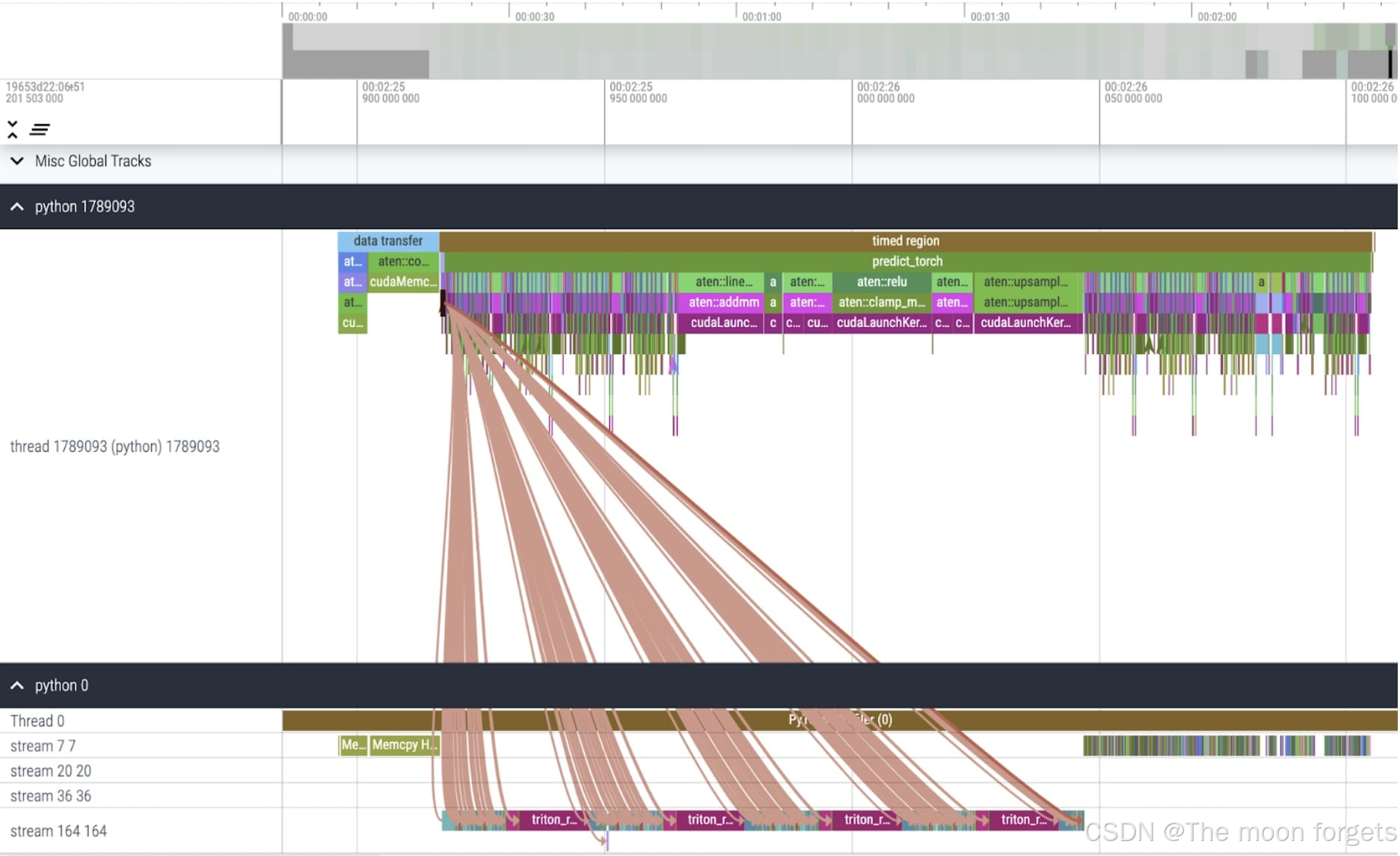
在 image encoderk中可以明显看到明显的内存峰值:
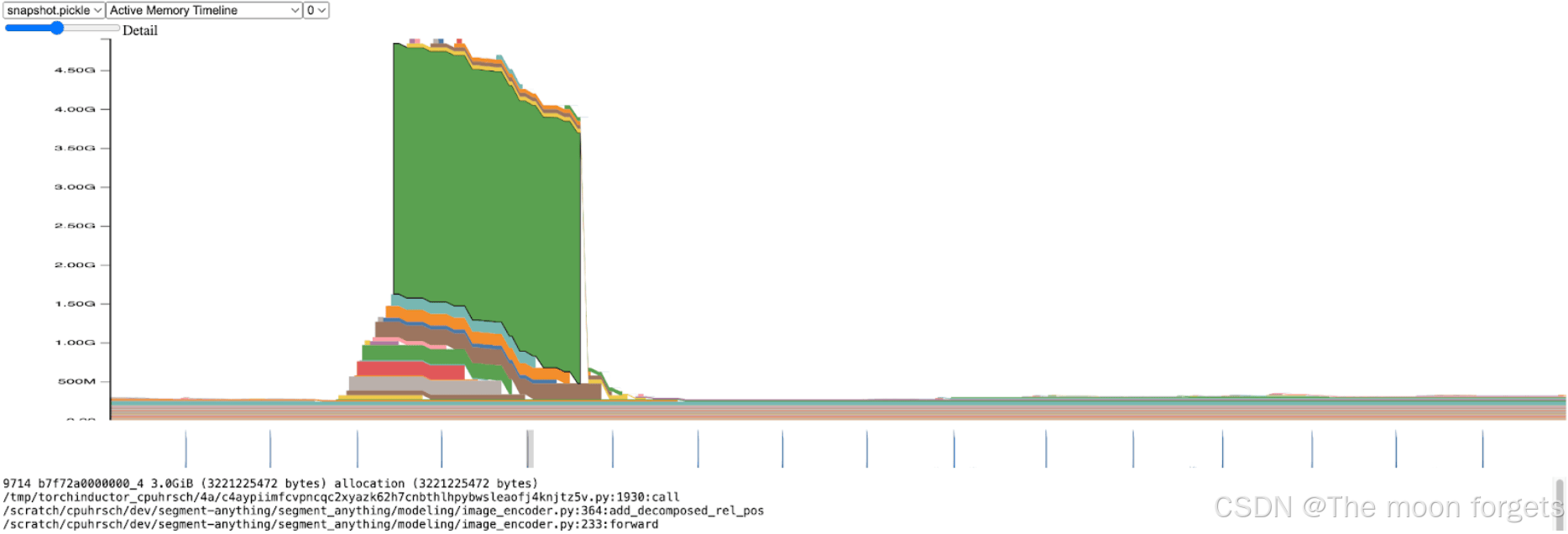
进一步,峰值的出现具体发生在add_decomposed_rel_pos中:
attn = (
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
***----> ).view(B, q_h * q_w, k_h * k_w)<------***
这里的attn变量是2个小尺寸的tensor加法:
r
e
l
h
∈
(
B
,
q
h
,
q
w
,
k
h
,
1
)
,
r
e
l
w
∈
(
B
,
q
h
,
q
w
,
1
,
k
w
)
rel_h \in (B, q_h, q_w, k_h, 1), rel_w \in (B, q_h, q_w, 1, k_w)
relh∈(B,qh,qw,kh,1),relw∈(B,qh,qw,1,kw)
如果我们不分配这么大的attn张量,而是将两个较小的
r
e
l
h
rel_h
relh和
r
e
l
w
rel_w
relw张量传入SDPA,并根据需要构建attn,预计会获得显著的性能提升。
但这并不是一个简单的修改;SDPA核心经过高度优化,是用CUDA编写的。但可以求助于Triton,他们有一个易于理解和使用的教程,介绍了FlashAttention实现。经过一番深入研究并与xFormer的Daniel Haziza密切合作,我们找到了一个输入形状的案例,相对来说比较容易实现核心的融合版本。
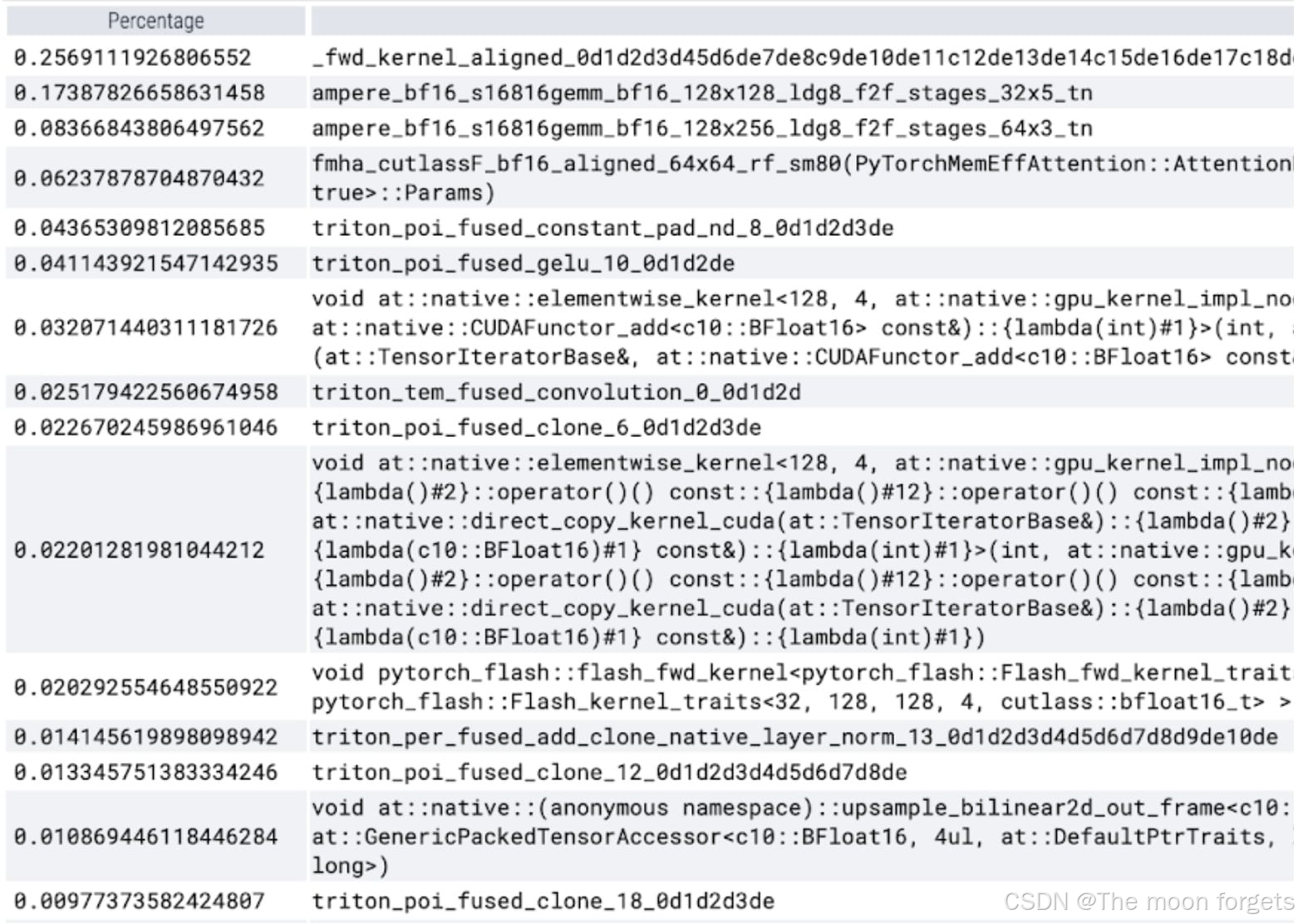
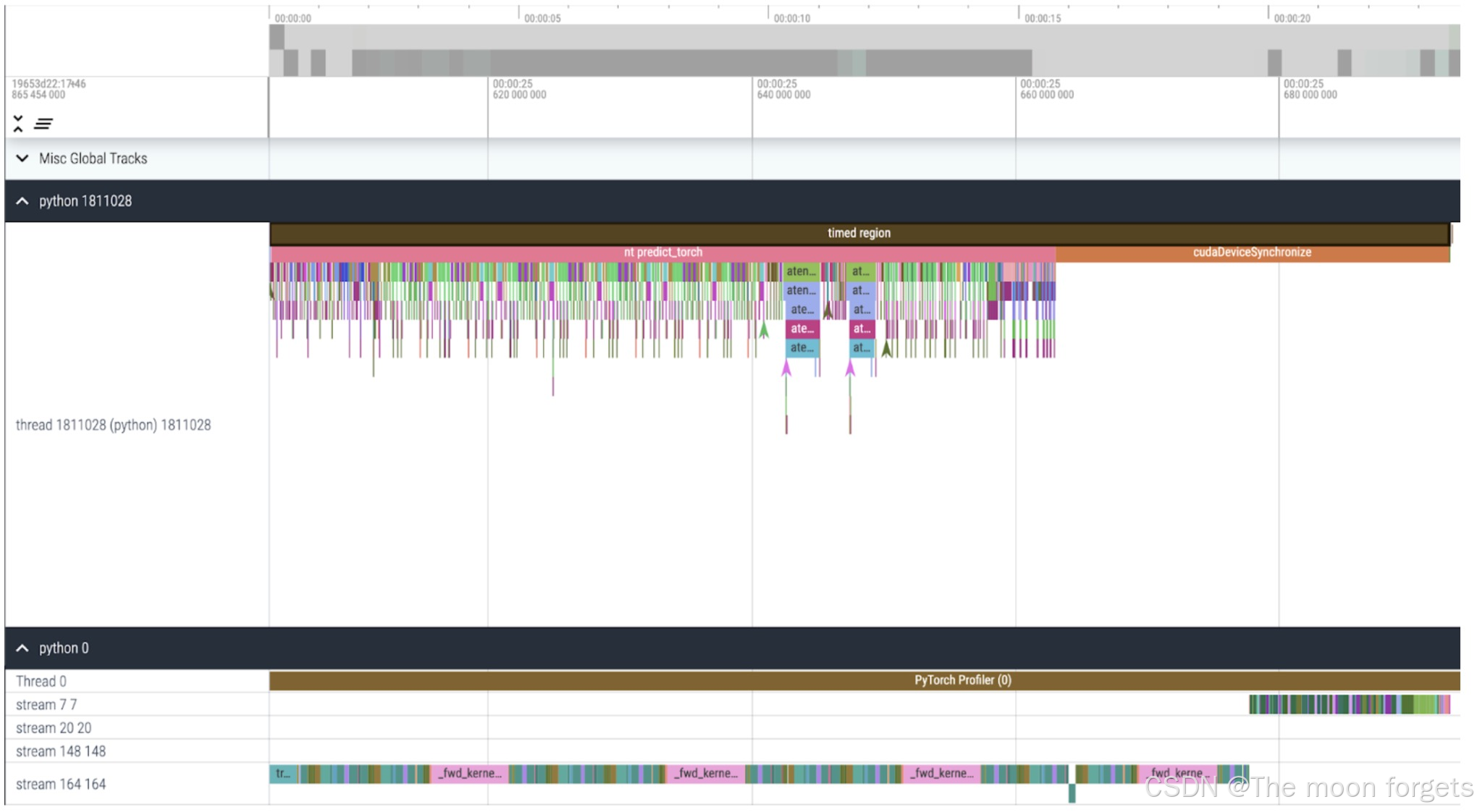
NT: NestedTensor and batching predict_torch
在 mask prediction pipeline中,我们观测到对于每张图像,我们有一个associated size, coords, 和 fg_labels Tensor。这些张量的batch_size大小都不同。每张图像本身的大小也不同。这种数据表示看起来像是Jagged Data (不规则数据)。使用PyTorch最近发布的NestedTensor,可以将batch coords 和 fg_labels Tensors修改为1个NestedTensor。这可以给prompt encoder 和 mask decoder带来很大提升:
torch.nested.nested_tensor(data, dtype=dtype, layout=torch.jagged)

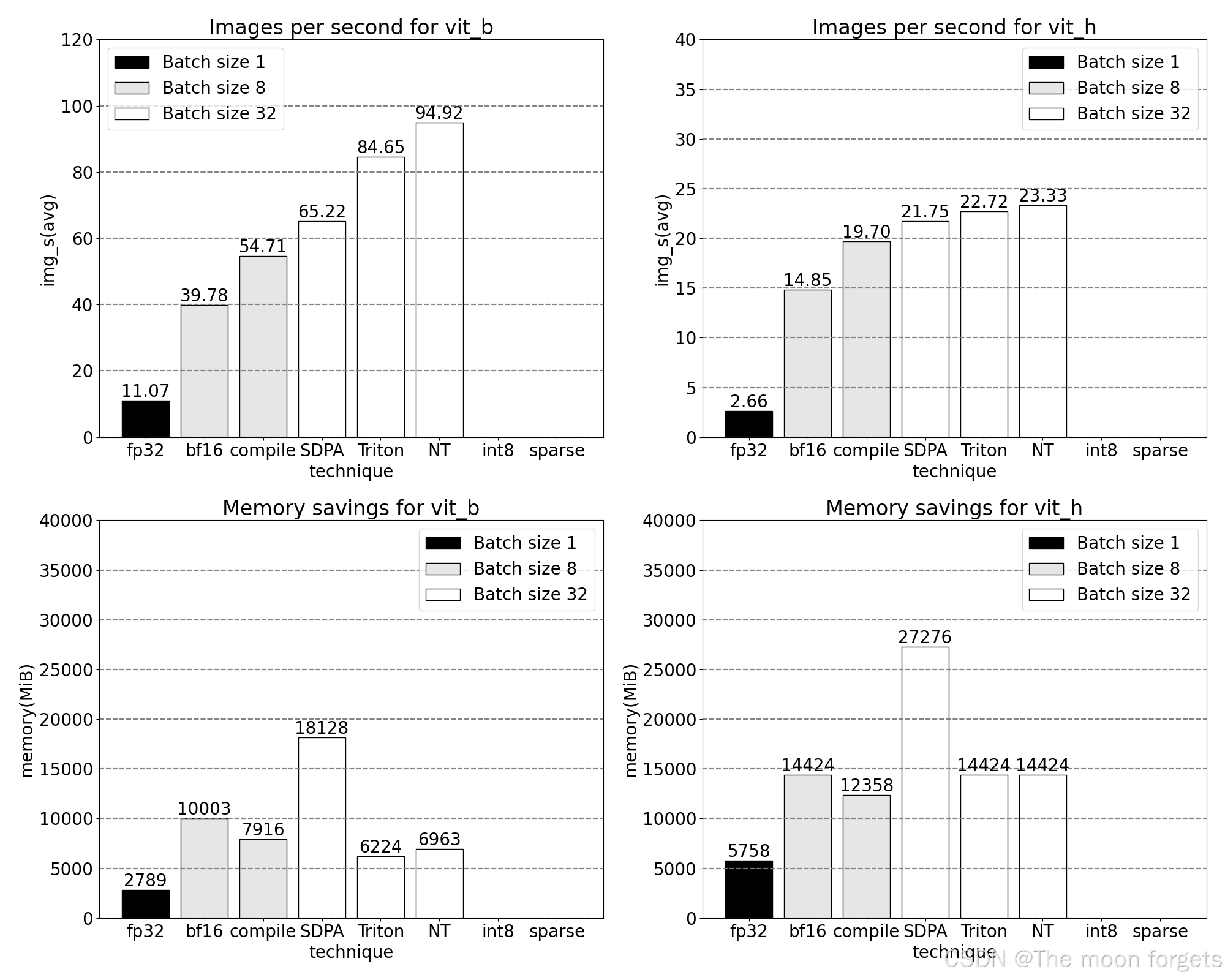
int8: quantization and approximating matmul
在从fp32到bfloat16的基础上再进一步,引入int8量化。
在量化方法方面,我们关注于Dynamic quantization (动态量化)
减少精度可以立即带来峰值内存节省,但要实现推理加速,我们必须充分利用int8通过SAM操作。这需要构建一个高效的int8@int8矩阵乘法核心,以及转换逻辑,从高精度到低精度(量化),以及从低精度到高精度的逆向转换(反量化)。利用torch.compile的功能,我们可以将这些量化和反量化例程编译和融合成高效的单个核心和矩阵乘法的最后
虽然在推理时对模型进行量化常常会导致一些精度下降,但SAM在低精度推理时表现尤为稳健,几乎没有精度损失。
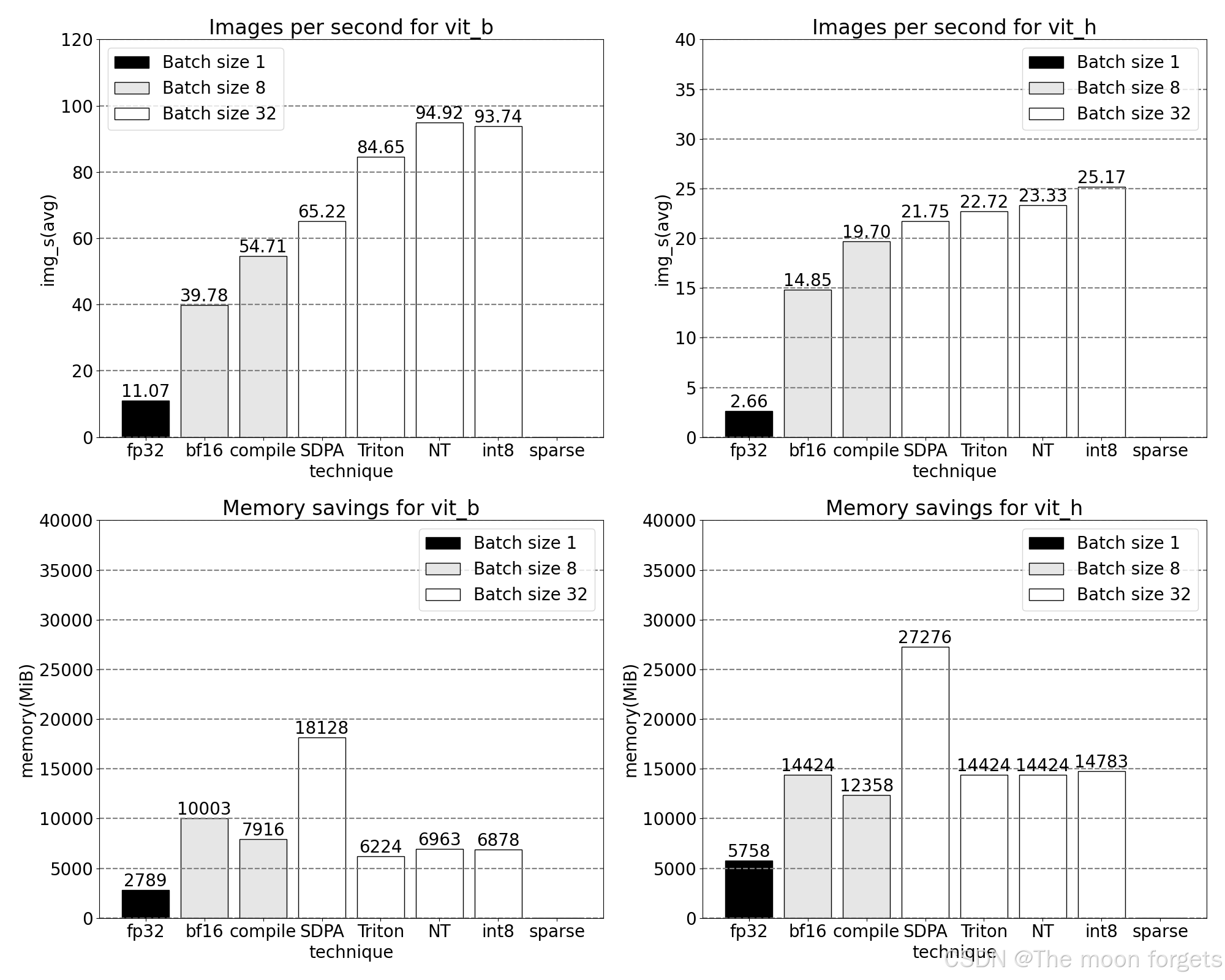
sparse: Semi-structured (2:4) sparsity
矩阵乘法仍然是我们的瓶颈。我们可以转向模型加速手册中另一种经典方法来近似矩阵乘法:稀疏化。通过稀疏化我们的矩阵(即将某些值置零),理论上可以使用更少的位来存储权重和激活张量。我们决定在张量中将哪些权重设为零的过程称为剪枝。剪枝的理念是权重张量中的小权重对层的净输出贡献较小,通常是权重与激活的乘积。剪枝掉小权重可以潜在地减小模型大小而几乎不损失精度。
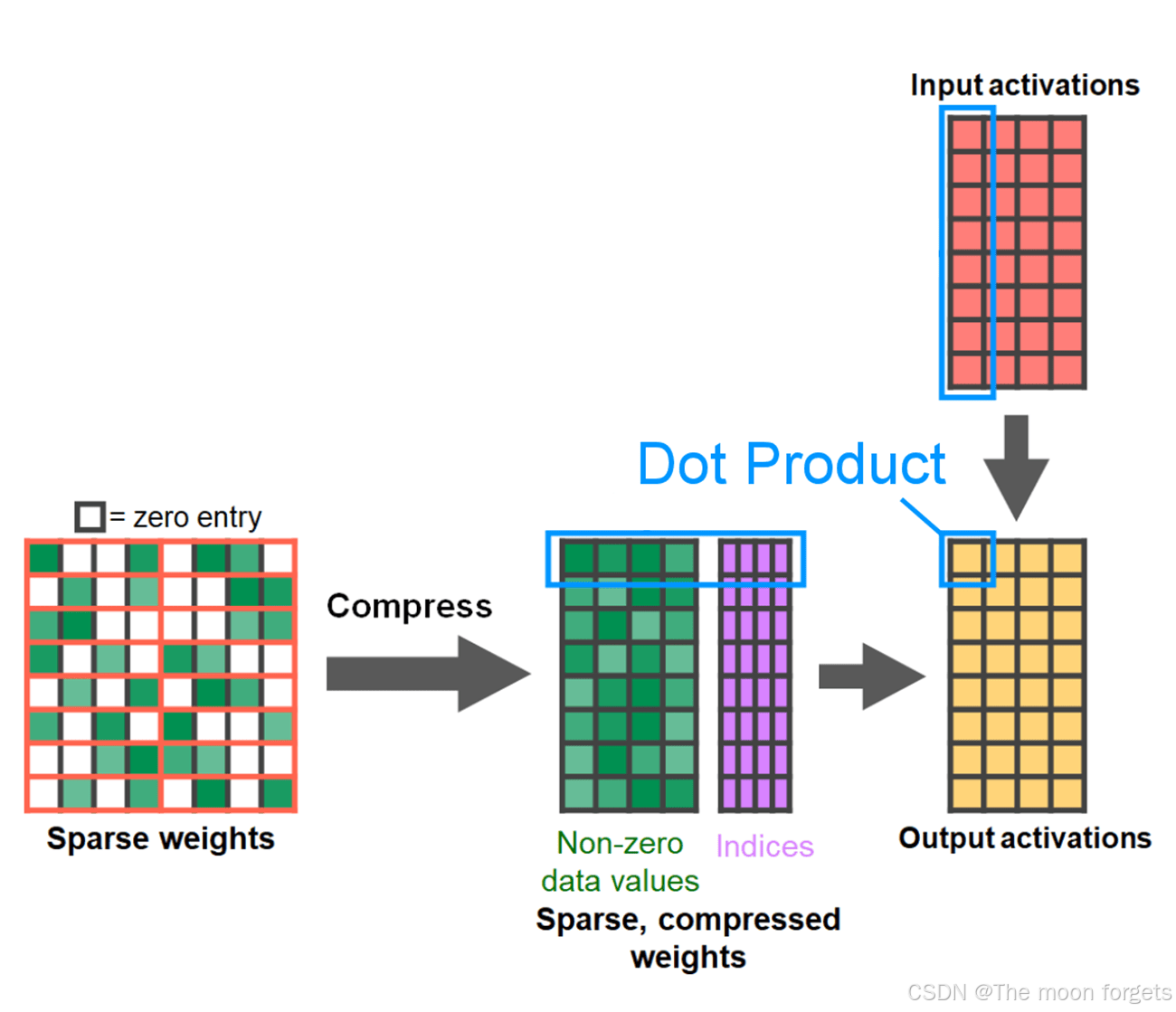
剪枝的方法多种多样,从完全非结构化到高度结构化。虽然非结构化剪枝理论上对精度的影响最小,但 GPU 在进行大型密集矩阵乘法方面尽管非常高效,然而在稀疏情况下可能还会遭受显着的性能下降。PyTorch 最近支持的一种剪枝方法旨在寻求平衡,称为半结构化(或 2:4)稀疏性。这种稀疏存储将原始张量减少了 50%,同时产生密集张量输出。参见下图的说明。
为了使用这种稀疏存储格式和相关的快速内核,接下来要做的是剪枝权重。本文在 2:4 的稀疏度下选择最小的两个权重进行剪枝,将权重从默认的 PyTorch(“strided”)布局更改为这种新的半结构化稀疏布局很容易。要实现 apply_sparse (model),只需要 32 行 Python 代码:
import torch
from torch.sparse import to_sparse_semi_structured, SparseSemiStructuredTensor
# Sparsity helper functions
def apply_fake_sparsity(model):
"""
This function simulates 2:4 sparsity on all linear layers in a model.
It uses the torch.ao.pruning flow.
"""
# torch.ao.pruning flow
from torch.ao.pruning import WeightNormSparsifier
sparse_config = []
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
sparse_config.append({"tensor_fqn": f"{name}.weight"})
sparsifier = WeightNormSparsifier(sparsity_level=1.0,
sparse_block_shape=(1,4),
zeros_per_block=2)
sparsifier.prepare(model, sparse_config)
sparsifier.step()
sparsifier.step()
sparsifier.squash_mask()
def apply_sparse(model):
apply_fake_sparsity(model)
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
mod.weight = torch.nn.Parameter(to_sparse_semi_structured(mod.weight))
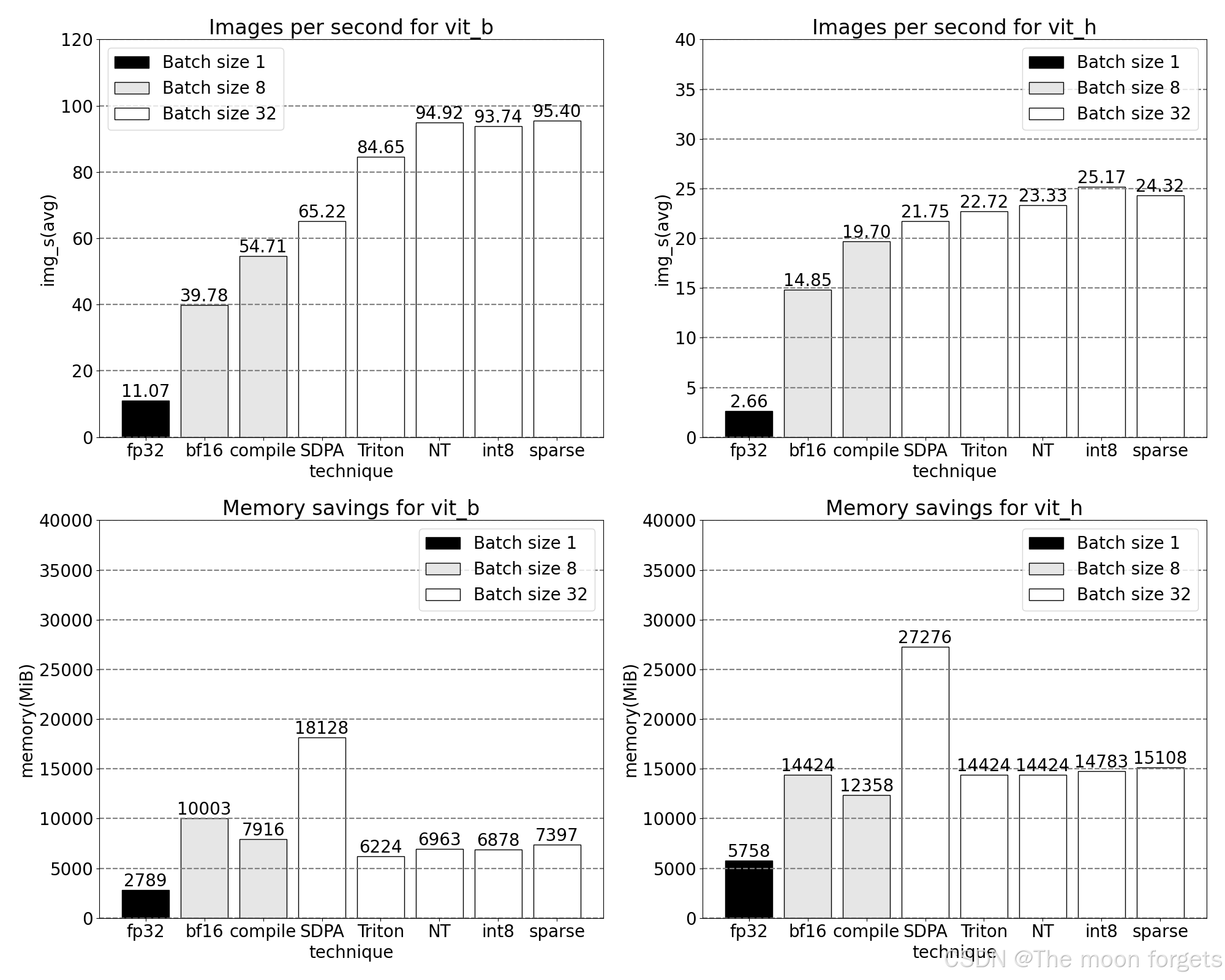
Conclusion
总结一下,我们很高兴地宣布我们迄今为止实现的最快的Segment Anything。我们使用了许多新发布的功能,将Meta原始的SAM纯粹重写为PyTorch,并没有损失准确性:
- Torch.compile PyTorch的原生JIT编译器,提供快速、自动融合PyTorch操作的功能
- GPU量化加速采用降低精度操作的模型
- Scaled Dot Product Attention (SDPA) Attention的新型、内存高效实现
- Semi-Structured (2:4) Sparsity 使用更少的位数存储权重和激活的模型加速
- Nested Tensor 高度优化的、用于非均匀批处理和图像尺寸的不规则数组处理
- Triton kernels Triton的自定义GPU操作,通过Triton轻松构建和优化


















 2289
2289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









