



PPT(Point Prompt Training)
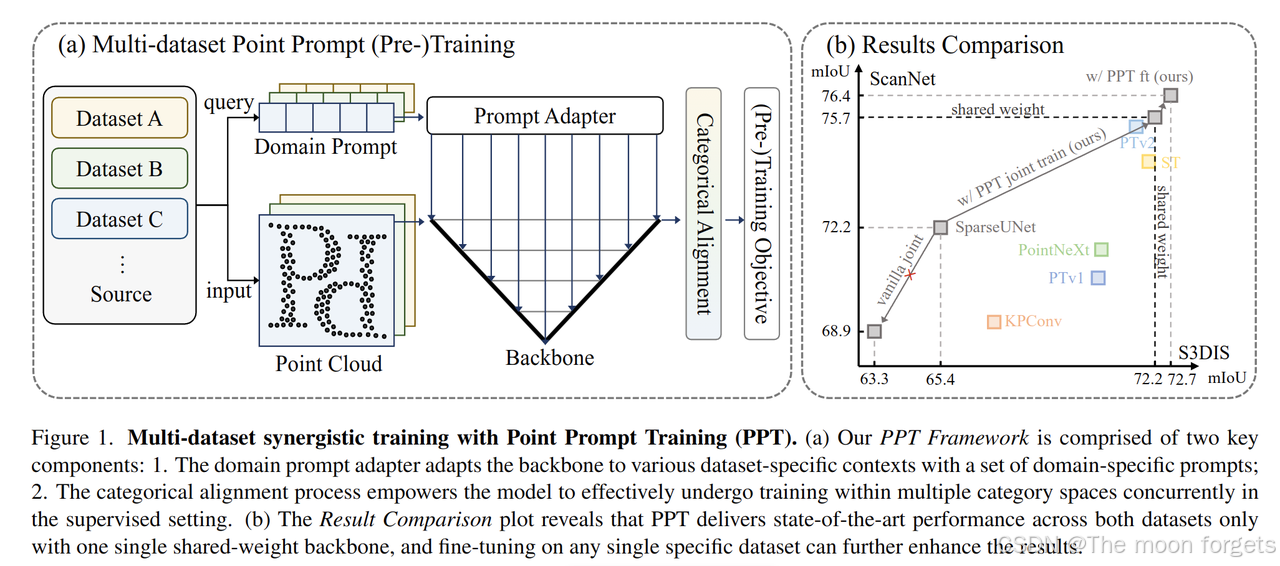
作者指出大规模3D点云d数据集的缺失限制了3D相关算法的发展,一种解决方法就是联合多个数据集训练一个模型。但是不同于图像,不同点云数据之前的差异是非常大的,直接联合训练反而会带来负面收益,因此本文提出了Point Prompt Training(PPT)来解决这一问题。
Related work
3D scene understanding
使用神经网络理解 3D 场景的深度学习技术可以根据它们处理点云的方法大致分为三类:基于投影的、基于体素的和基于点的方法。基于投影的方法涉及将3D点投影到多个图像平面上,并利用基于2D CNN的主干进行特征提取。相比之下,基于体素的方法将点云转换为常规体素表示,以完成3D卷积。通过使用sparse conv进一步增强了这些方法的效率。与之前的两种方法不同,结合Transformer-based方法,基于点的方法直接在点云上运行。本文将在在基于体素的SparseUNet上进行训练,效率更高。
3D representation learning
深度神经网络是data-driven的,扩大预训练数据已成为学习稳健和可迁移表征的一种有效途径。与 2D 视觉不同,3D 视觉中的数据收集和标注成本要高得多,点云数据集的规模非常有限。关于 3D 表征学习,以前的工作通常在单个数据集上进行预训练,这限制了从数据规模中的受益。最近的一些学者探索了合并数据的无监督预训练(ScanNet、 ArkitScenes)。然而,由于不同的3D 数据集的分布差异很大,简单的做数据集的合并可能是负收益的。
Towards large-scale pre-training
为了扩大预训练的数据规模并学习更好的表征能力,2D 视觉中的两个主流方向是更好的开发d现有数据额潜力以及利用未标注的原始数据。然而,后者不适用于 3D 数据。在一些与 2D 场景理解和 3D 目标检测相关的工作中,还探索了跨域联合学习的方向,但他们多关注在直接对目标数据集进行评估。我们的工作更针对有监督和无监督设置中的广义表征学习。此外,3D 数据集的稀疏性和长尾现象也增加了 3D 联合训练的难度。
Prompt learning
为了提高预训练模型对下游任务的泛化能力,提示工程最初是在自然语言处理中提出的。提示工程可以是启发式设计的、自动生成的或作为可学习的模型参数(提示学习)。在 2D 视觉中,快速学习已成为一种流行的参数高效的手段来让预训练模型适应特定的下游任务(fine-tune)。本文直接进行预训练。提示学习被视为特定于数据集的adapter,以允许模型分别解决预训练数据集之间的域转移,并学习最佳的整体表示。
Point Prompt Training
主要包括两部分:
- prompt adapter: 利用一个可学习的domain-specific提示工程来完成不同数据集的不同语义;
- categorical alignment: 保证模型在不同的数据集中获取恰当的监督信息。
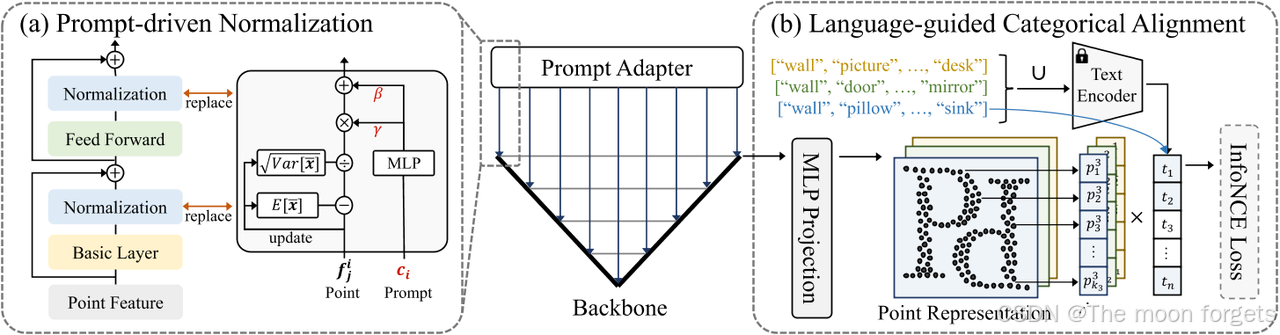
Learning with Domain Prompting
采用domain prompting直接作为可学习的参数参与训练,作为不同数据集的信息之一,而不是fine-tuning
-
Domain prompting:domain prompt用一个d维的向量表征,对于每一个数据集 D i D_i Di, 得到的 n n n个信息可以表示为: C = { c i ∈ R d ∣ i ∈ N , 1 ≤ i ≤ n } C = \{c^i\in \mathbb{R}^d|i \in \mathbb{N}, 1 ≤ i ≤ n \} C={ci∈Rd∣i∈N,1≤i≤n}
则多数据集训练目标可以表示为: argmin θ , C ∑ i = 1 n 1 ∣ D i ∣ ∑ ( x j i , y j i ) ∈ D i L ( f ( x j i , c i ; θ ) , y j i ) \text{argmin}_{\theta, C} \sum_{i=1}^{n} \frac{1}{|D_i|} \sum_{(x_j^i, y_j^i) \in D_i} L(f(x_j^i,c_i;\theta), y_j^i) argminθ,C∑i=1n∣Di∣1∑(xji,yji)∈DiL(f(xji,ci;θ),yji) -
Domain prompt adapter:确保模型可以得到特定数据集正确对应的prompt, 基于视觉提示工程的经验,利用共享的提示工程对模型进行block控制比在输入层加入提示特征更加有效。
- Direct Injection: 作为输入数据的特征之一加入到输入中
- Cross Attention : 基于DETR的思路,添加跳连的CA block
- Prompt-driven Normalization∗(PDNorm): domain 提示工程的目的是学习不同数据集(目标域)之间的共性表示,类似风格迁移方法中保留本质信息只变换上下文风格信息。根据给的domain提示特征 c c c, PDNorm会自适应学习 γ \gamma γ和 β \beta β, 可以表示为: PDNorm ( x , c ) = x − E [ x ˉ ] Var [ x ˉ ] + ϵ ⋅ γ ( c ) + β ( c ) \text{PDNorm}(x, c) = \frac{x-E[\bar{x}]}{\sqrt{\text{Var}[\bar{x}] + \epsilon}}·\gamma(c)+\beta(c) PDNorm(x,c)=Var[xˉ]+ϵx−E[xˉ]⋅γ(c)+β(c), 其中 γ ( c ) , β ( c ) \gamma(c), \beta(c) γ(c),β(c)为线性层,不同数据集的 E [ x ˉ ] E[\bar{x}] E[xˉ]和 Var [ x ˉ ] \text{Var}[\bar{x}] Var[xˉ]是相互独立的。使用PDNorm替换backboned中的Norm层。
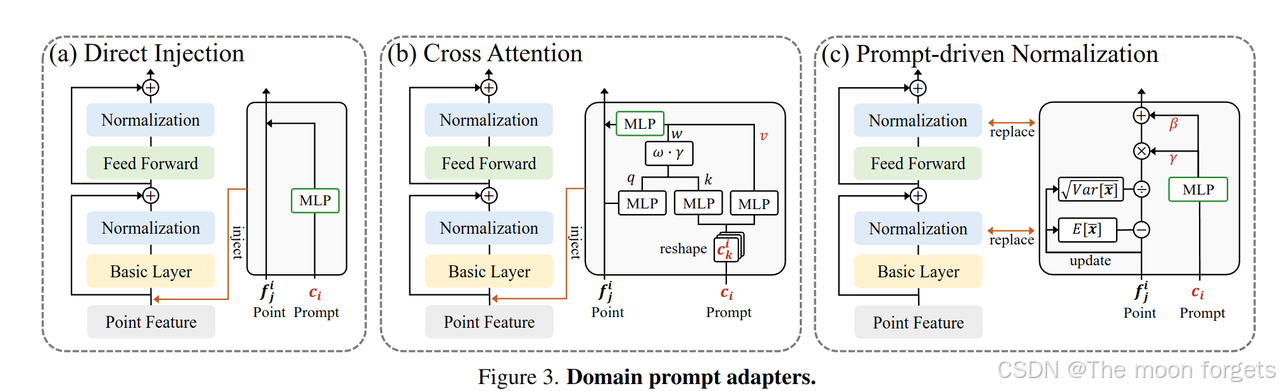
- Zero-initialization and learning rate scaling: 由于domain表征的是不同数据集的特性,随机初始化会造成训练不稳定,因此采用统一的0初始化,训练前期学习数据的共性,后期学习各个数据集的特性。
Categorical Alignment
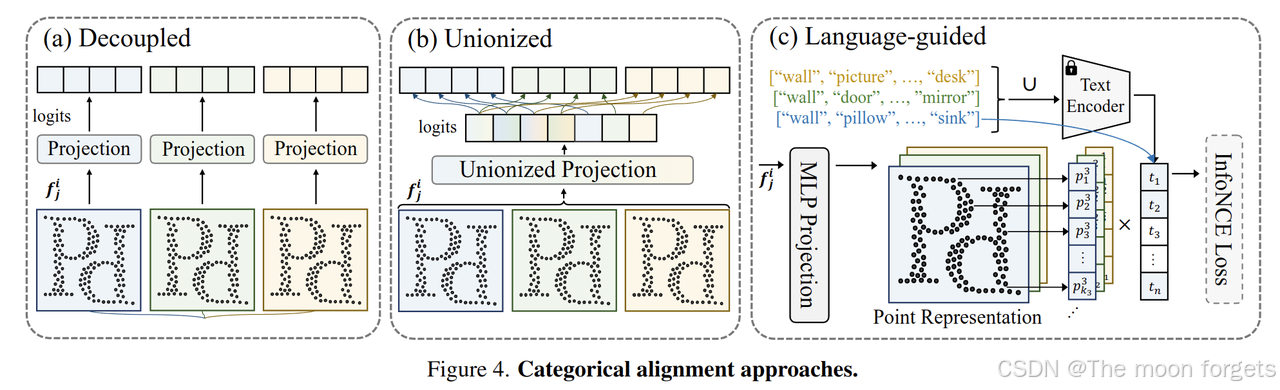
在 PPT 中,需要解决的另一个关键问题是标签空间在不同数据集上与监督学习的不一致。
- Decoupled: 一种简单的方法是为每个数据集使用单独的线性投影头。虽然这种方法在处理不一致方面是有效的,但它引入了冗余参数来解码不同数据集的相同类别。此外,它忽略了数据集之间的共性,没有考虑到它们的潜在相关性。
- Unionized:另一种直观的方法是构建一个共享的线性分割头,它将表示空间投影到包含所有数据集的统一标签空间,而损失计算保持不变,并被限制为每个数据集的不同标签空间。这种方法有效地解决了跨数据集共享标签空间相关的点表示不一致。
- Language-guided∗:上述选项独立处理每个类别并假设它们是不相关的。然而,一个自然的事实是,具有相似含义的标签应该具有相似的表示。利用这些先验信息可以进一步有利于在我们的场景中发现鲁棒表示。为此,我们提出了语言引导的分类对齐,它将投影点表示与预训练文本编码器(例如 CLIP)提取的类别语言嵌入对齐。为了实现这一目标,我们使用InfoNCE作为对齐标准,并将负样本限制在特定的数据集类别空间中。
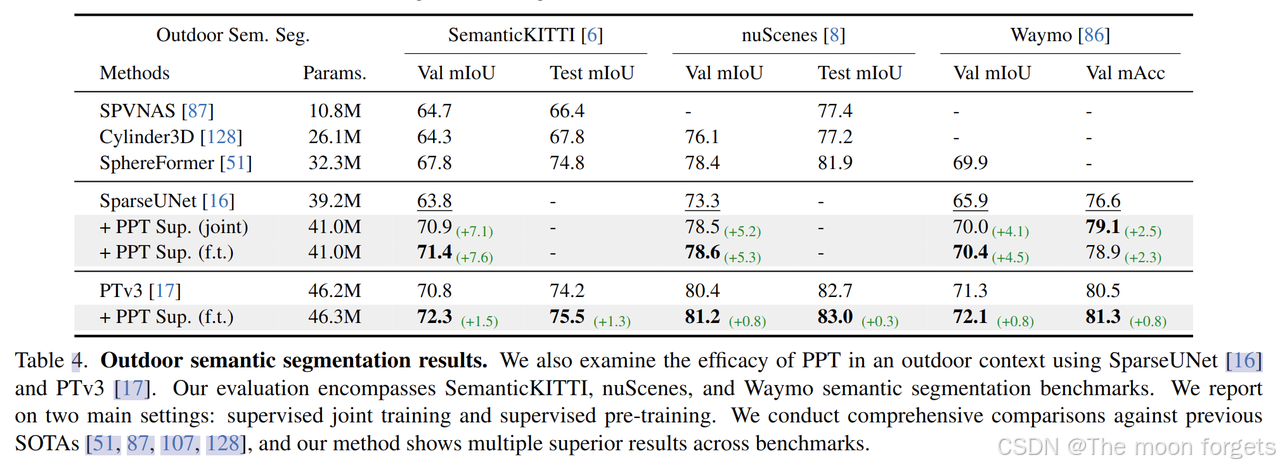
Experiments

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









