







 本文介绍了强化学习中的策略梯度方法,强调策略作为网络模型,输入为环境状态,输出为行为概率。通过调整策略网络参数以最大化期望奖励。文章探讨了在奖励始终为正的情况下可能导致的问题,并提出加入基线和适当地分配奖励信用的重要性。
本文介绍了强化学习中的策略梯度方法,强调策略作为网络模型,输入为环境状态,输出为行为概率。通过调整策略网络参数以最大化期望奖励。文章探讨了在奖励始终为正的情况下可能导致的问题,并提出加入基线和适当地分配奖励信用的重要性。
Policy Gradient

在强化学习中有3个组成部分:演员(actor)、环境(environment)和·奖励函数(reward function)·
在强化学习中,环境跟奖励函数不是你可以控制的,环境跟奖励函数是在开始学习之前,就已经事先给定的。唯一能做的就是调整演员里面的策略(policy),使得演员可以得到最大的奖励。演员里面会有一个策略,这个策略决定了演员的行为。
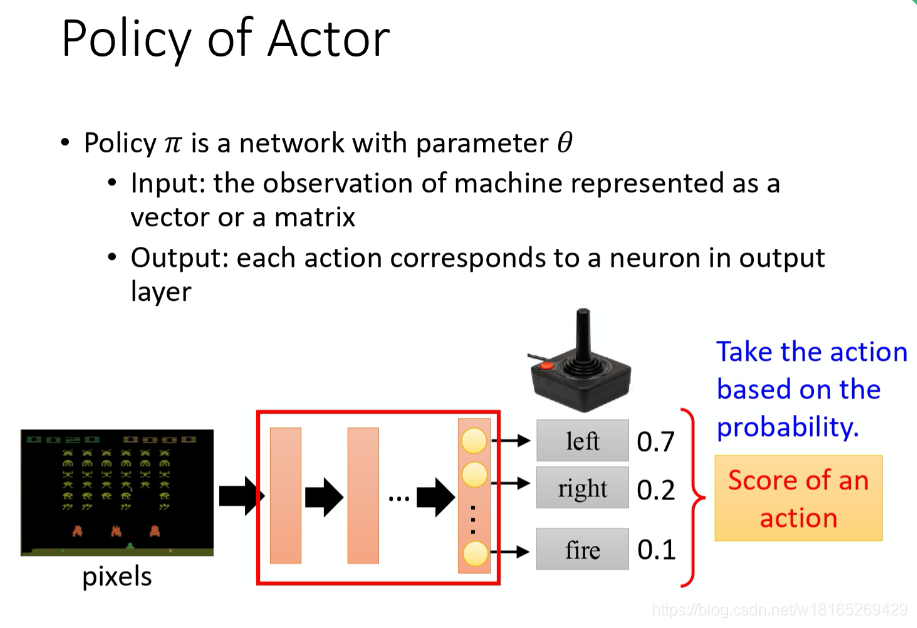
策略一般写成π。假设用深度学习的技术来做强化学习的话,策略就是一个网路。网络里面就有一堆参数,我们用 θ 来代表 \piπ 的参数。
网络的输入就是现在机器看到的东西,如果让机器打电玩的话,机器看到的东西就是游戏的画面。机器看到什么东西,会影响你现在训练到底好不好训练。举例来说,在玩游戏的时候, 也许你觉得游戏的画面前后是相关的,也许你觉得你应该让你的策略,看从游戏初始到现在这个时间点,所有画面的总和。你可能会觉得你要用到 RNN 来处理它,不过这样子会比较难处理。要让你的机器,你的策略看到什么样的画面,这个是你自己决定的。让你知道说给机器看到什么样的游戏画面,可能是比较有效的。
输出就是机器要采取什么样的行为。
上图就是具体的例子,
策略就是一个网络;
输入 就是游戏的画面,它通常是由像素(pixels)所组成的;
输出就是看看说有哪些选项是你可以去执行的,输出层就有几个神经元。
假设你现在可以做的行为有 3 个,输出层就是有 3 个神经元。每个神经元对应到一个可以采取的行为。
输入一个东西后,网络就会给每一个可以采取的行为一个分数。你可以把这个分数当作是概率。演员就是看这个概率的分布,根据这个概率的分布来决定它要采取的行为。比如说 70% 会向左走,20% 向右走,10% 开火等等。概率分布不同,演员采取的行为就会不一样。
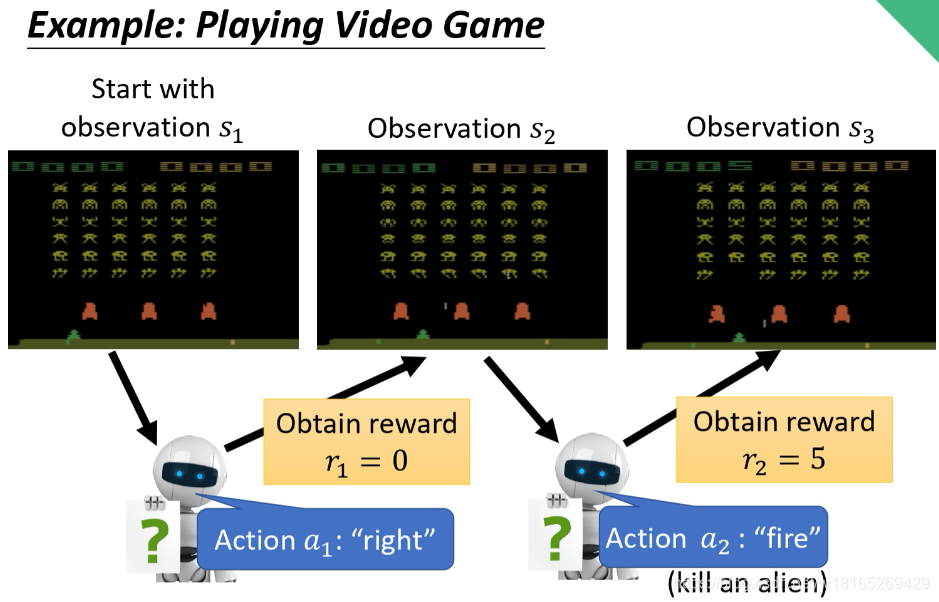
接下来用一个例子来说明演员是怎么样跟环境互动的。
首先演员会看到一个游戏画面,我们用 s1来表示游戏初始的画面。接下来演员看到这个游戏的初始画面以后,根据它内部的网络,根据它内部的策略来决定一个动作。假设它现在决定的动作 是向右,它决定完动作 以后,它就会得到一个奖励,代表它采取这个动作以后得到的分数。
我们把一开始的初始画面记作 s1, 把第一次执行的动作记作 a1,把第一次执行动作完以后得到的奖励记作 r1。不同的书会有不同的定义,有人会觉得说这边应该要叫做 r2,这个都可以,你自己看得懂就好。演员决定一个行为以后,就会看到一个新的游戏画面,这边是 s2
。然后把这个 s2输入给演员,这个演员决定要开火,然后它可能杀了一只怪,就得到五分。这个过程就反复地持续下去,直到今天走到某一个时间点执行某一个动作,得到奖励之后,这个环境决定这个游戏结束了。比如说,如果在这个游戏里面,你是控制绿色的船去杀怪,如果你被杀死的话,游戏就结束,或是你把所有的怪都清空,游戏就结束了。
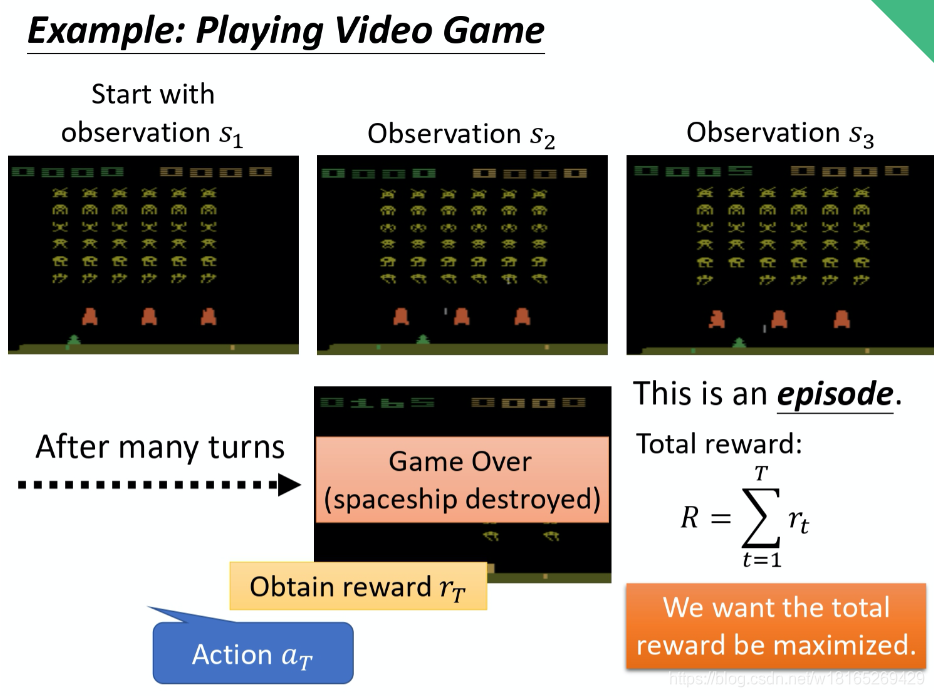
一场游戏叫做一个回合(episode)或者试验(trail)。
把这场游戏里面所得到的奖励都加起来,就是总奖励(total reward),称之为回报(return)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









