







1. 这篇论文要解决什么问题(problem)?
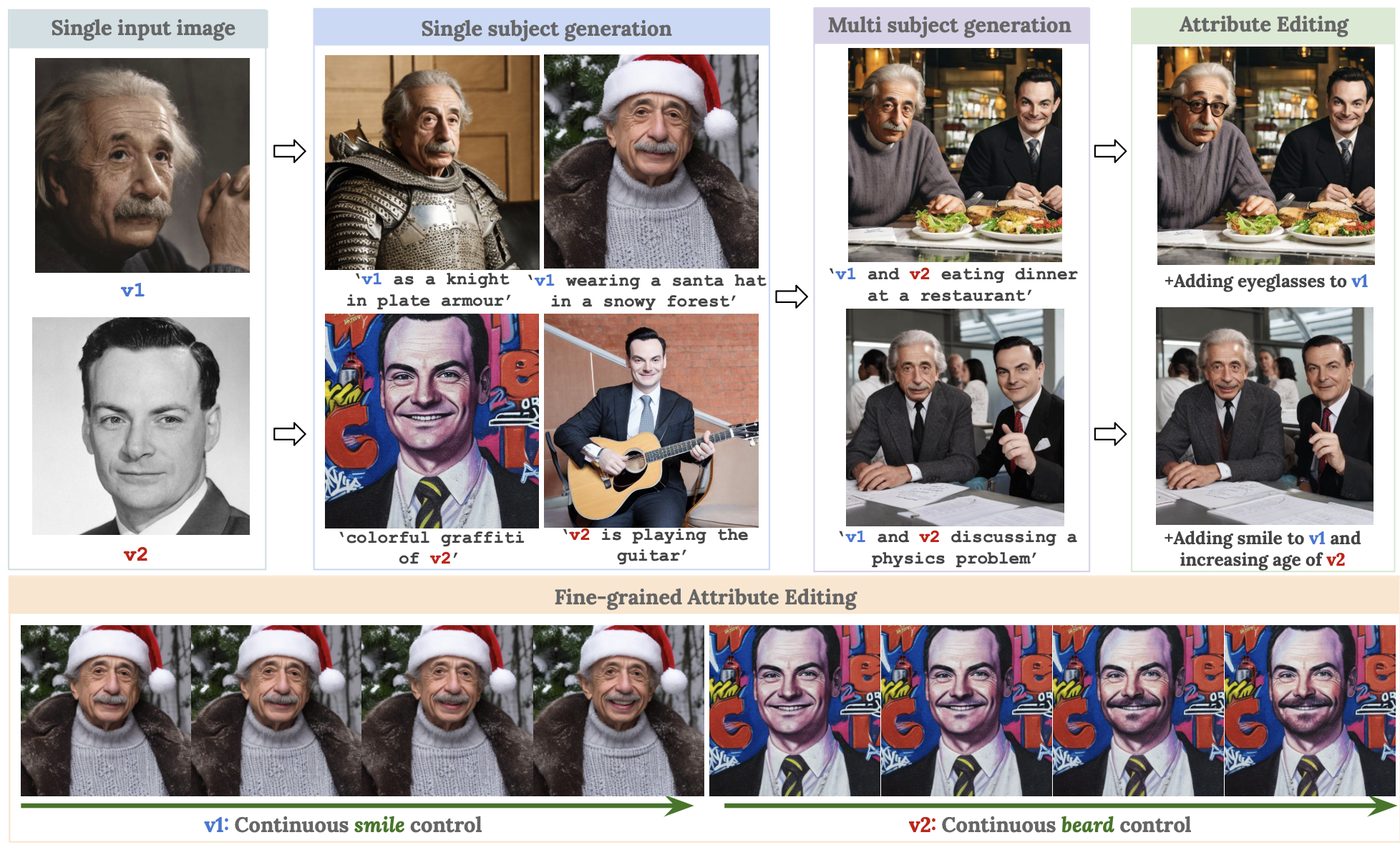
论文主要解决的问题是:现有的文本到图像(T2I)扩散模型在面部个性化生成和精细属性编辑方面存在局限性。具体表现为:
- 身份保留不足:现有方法在面部个性化生成时难以忠实保留输入图像的身份特征。
- 精细控制不足:仅依赖文本提示无法实现连续、精细的面部属性编辑(如微笑程度、年龄调整等)。
- 多主体合成的属性混合问题:在生成包含多个主体的图像时,不同主体的属性容易相互干扰(如年龄、发型等)。
2. 已有工作的思路以及不足之处(existing work)有哪些?
已有工作分类及不足:
-
通用个性化方法(如Textual Inversion、Dreambooth):
- 思路:通过优化对象特定的标记嵌入或微调模型来学习新概念。
- 不足:难以保留面部身份特征,且无法实现精细属性控制。
-
面部专用方法(如Celeb Basis、Photoverse):
- 思路:利用名人名称基或双分支条件(文本+图像)改进面部嵌入。
- 不足:生成结果可能缺乏真实感(如卡通化),且不支持精细属性编辑。
-
StyleGAN模型:
- 思路:利用解耦的 W + \mathcal{W}+ W+空间实现精细属性编辑。
- 不足:仅适用于裁剪后的肖像,无法生成多样化背景或多主体场景。
-
多主体合成方法:
- 不足:联合微调会导致属性混合(如一个主体的年龄特征转移到另一主体)。
3. 本文insight?
- 结合T2I模型与StyleGAN的优势:利用T2I模型的通用生成能力(如多样化背景)和StyleGAN的 W + \mathcal{W}+ W+空间解耦特性(精细属性控制)。
- W + \mathcal{W}+ W+空间作为桥梁:通过将 W + \mathcal{W}+ W+空间条件化到T2I模型中,既能保留身份特征,又能实现连续属性编辑。
- 时间依赖的标记嵌入:为每个扩散时间步生成不同的标记嵌入,提升身份保留能力。
4. 解决方法?
基本思想:
- 条件化T2I模型:通过训练一个轻量级MLP(潜在适配器 M \mathcal{M} M),将StyleGAN的 W + \mathcal{W}+ W+空间映射到T2I模型的标记嵌入空间。
- 两阶段训练:
- 预训练:在面部数据集上训练 M \mathcal{M} M,结合扩散损失、正则化损失和身份损失。
- 主体特定微调:使用LoRA对U-Net进行低秩更新,进一步提升身份保留。
- 多主体合成:通过并行扩散链(每个主体独立生成)和实例掩码融合,避免属性混合。
模型的输入输出:
- 输入:
- 单张面部图像(个性化生成)或多张图像(多主体合成)。
- 可选文本提示(控制生成场景或风格)。
- 属性编辑方向(如微笑、年龄)和强度参数 β \beta β(用于 W + \mathcal{W}+ W+空间操作)。
- 输出:
- 个性化生成的图像(保留输入身份,符合文本描述)。
- 支持连续属性编辑(如调整微笑程度)或多主体合成(无属性混合)。
关键模块:
- 潜在适配器 M \mathcal{M} M:输入为 W &
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









