




OCR模型选型:从专业OCR到多模态VLM的全面对比
前言
随着AI技术的快速发展,OCR(光学字符识别)技术已经从传统的文字识别演进为复杂的文档理解和多模态处理。本文对当前主流的OCR模型进行了全面评估,包括专业OCR模型和多模态视觉语言模型,为不同应用场景提供选型参考。
新增+1
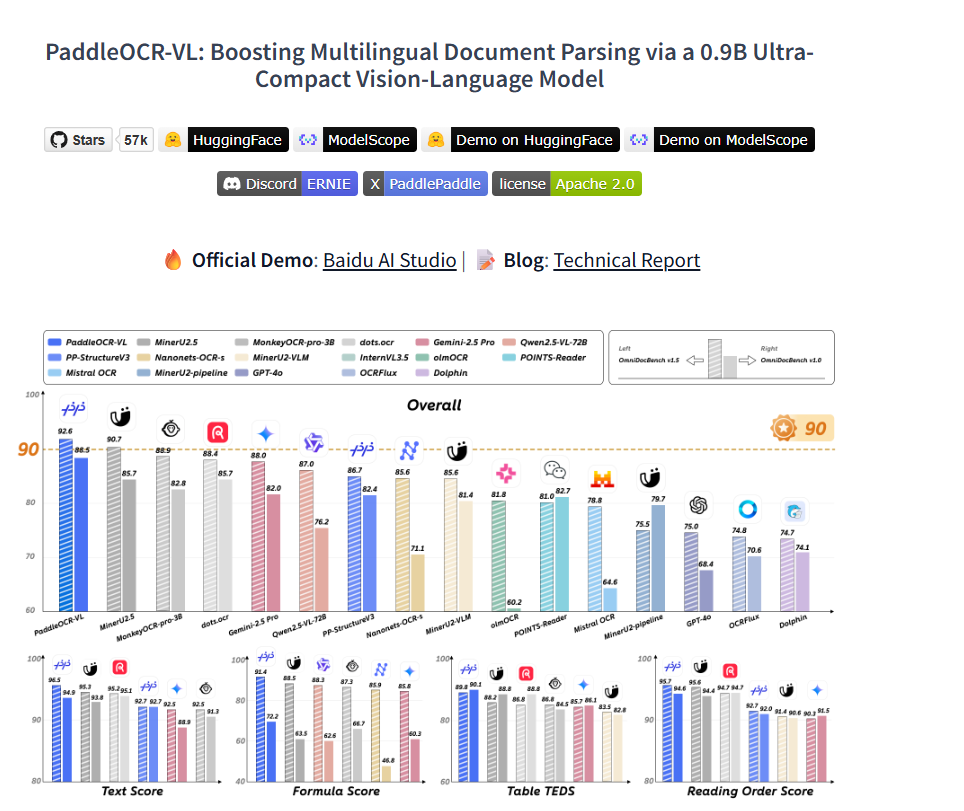
2025.9.16发布的PaddleOCR-VL是一款专为文档解析量身定制的 SOTA 且资源高效的模型。其核心组件是 PaddleOCR-VL-0.9B,这是一个紧凑但功能强大的视觉语言模型 (VLM),它将 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型相结合,以实现精准的元素识别。该创新模型高效支持 109 种语言,并且在识别复杂元素(例如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过对广泛使用的公共基准测试和内部基准测试的全面评估,PaddleOCR-VL 在页面级文档解析和元素级识别方面均达到了 SOTA 性能。它的性能显著优于现有解决方案,与顶级 VLM 相比具有强大的竞争力,并具有快速的推理速度。这些优势使其非常适合在实际场景中实际部署。
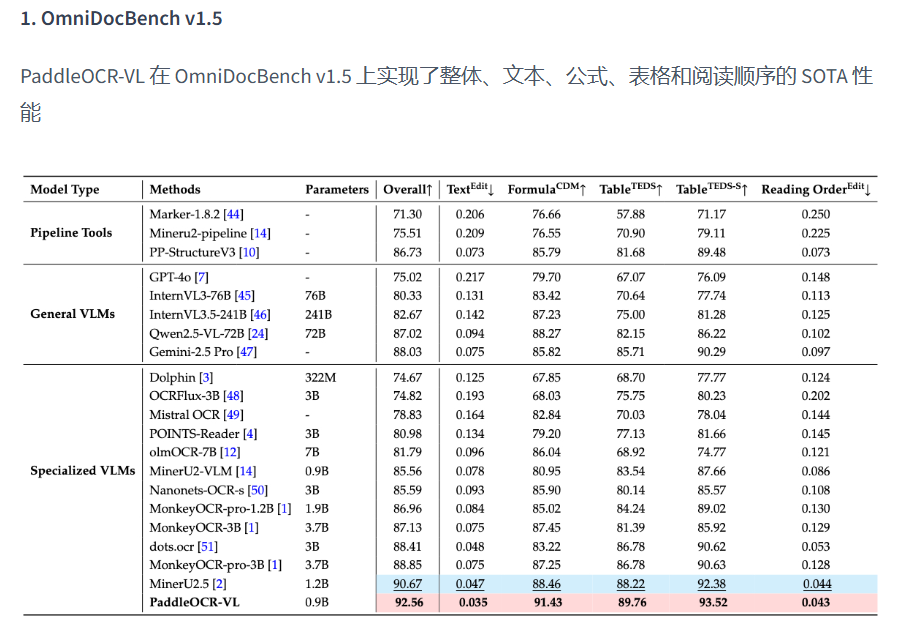
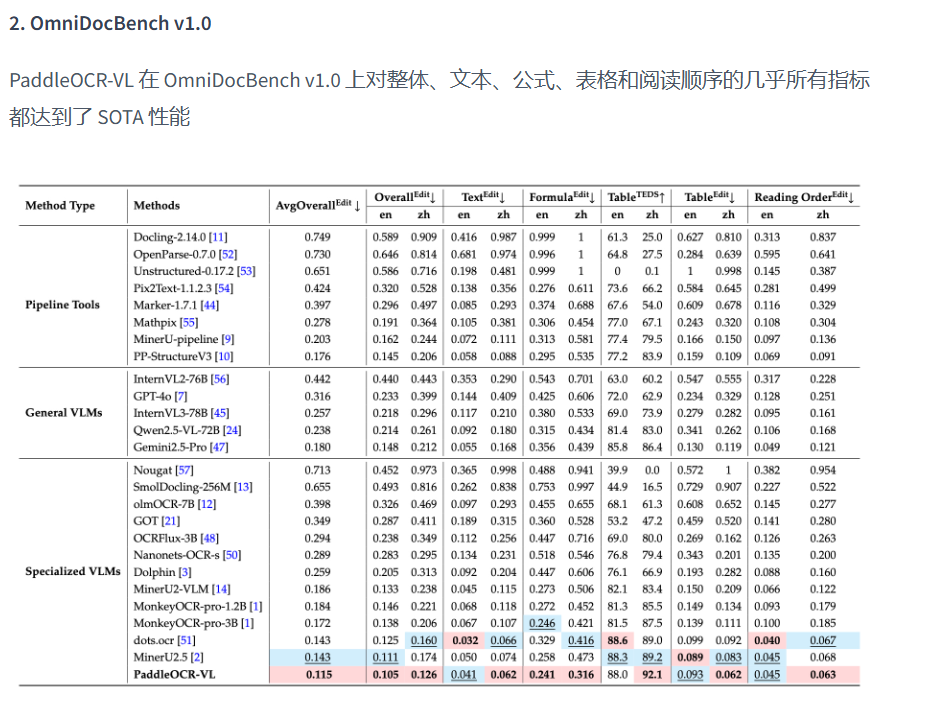

当之无愧的目前的SOTA,同时也说明了对比通用的LLM,垂直领域的模型还是很有必要的
模型概览
本次选型涵盖6个主流模型,分为两大类:
专业OCR模型
- dots.ocr - 基于1.7B参数的多语言文档解析模型
- OCRFlux-3B - 基于Qwen2.5-VL的文档转换模型
- MonkeyOCR-pro-3B - 轻量级文档解析模型
- MinerU - 高精度文档内容提取解决方案
多模态VLM模型
- InternVL3-14B - 多模态大语言模型
- Ovis2.5-9B - 原生分辨率视觉感知模型
模型详细分析
专业OCR模型
1. dots.ocr(小红书)
- 发布时间: 2025年7月
- 参数量: 1.7B
- 开发机构: rednote-hilab
核心优势: dots.ocr以仅1.7B的极小参数量实现了SOTA性能,采用统一的版面检测和内容识别架构,简化了处理流程。该模型在OmniDocBench上达到SOTA表现,推理速度快于大型基础模型,特别适合低资源语言的多语言支持场景。
局限性: 该模型不支持跨页表格处理,在处理高密度图像时可能出现错误。特殊字符(如...、___)会导致重复错误,且批量作业的吞吐量有限。
适用场景: 轻量级部署、多语言文档处理
2. OCRFlux-3B
- 发布时间: 2024年11月
- 参数量: 3B
- 开发机构: ChatDOC
核心优势: OCRFlux-3B基于Qwen2.5-VL-3B-Instruct微调,在基准测试中EDS达到96.7%。作为首个支持跨页表格/段落合并的开源项目,该模型可在GTX 3090上运行,支持大规模文档处理(vLLM加速),原生支持中英双语。
适用场景: PDF文档批量处理、跨页表格处理
3. MonkeyOCR-pro-3B
- 发布时间: 2025年6月
- 参数量: 3B
- 开发机构: Yuliang-Liu团队
核心优势: MonkeyOCR-pro-3B采用Structure-Recognition-Relation(SRR)三元组范式,相比MinerU平均提升5.1%,其中公式识别提升15.0%,表格处理提升8.6%。该模型多页文档处理速度达到0.84页/秒,在OmniDocBench上表现优于大型商业模型,支持中英文档解析。
局限性: 该模型不支持跨页表格处理,也不支持拍摄的文档。
适用场景: 结构化文档解析、高速处理需求
4. MinerU
- 发布时间: 2024年9月
- 参数量: 不详(基于PDF-Extract-Kit模型)
- 开发机构: OpenDataLab
核心优势: MinerU提供高精度文档内容提取,支持多种文档类型,具备完整的预处理和后处理规则。该模型支持公式识别和版面检测,具有自动语言识别功能。
适用场景: 科学文献处理、多格式文档转换
多模态VLM模型
5. InternVL3-14B
- 发布时间: 2024年12月
- 参数量: 14B
- 开发机构: OpenGVLab
核心优势: InternVL3-14B是先进的多模态大语言模型,采用Native Multimodal Pre-Training方法,支持工具使用、GUI代理、工业图像分析。该模型具备3D视觉感知能力,采用ViT-MLP-LLM架构,在MMMU基准测试中表现优异。
适用场景: 复杂多模态任务、高精度视觉理解
6. Ovis2.5-9B
- 发布时间: 2025年8月
- 参数量: 9B
- 开发机构: AIDC-AI
核心优势: Ovis2.5-9B具备原生分辨率感知能力,实现无损图像处理,具有深度推理能力并支持思维模式。该模型在图表和文档OCR性能方面领先,在OpenCompass评测中达到78.3分(40B以下参数模型SOTA)。采用NaViT视觉编码器保持细节和全局结构,支持反思性推理。
适用场景: 资源受限环境、高精度OCR需求
性能对比分析
模型对比分析表
| 模型 | 参数量 | 发布时间 | 核心特性 | 性能亮点 | 部署要求 | 应用场景 |
|---|---|---|---|---|---|---|
| MinerU | 未公开 | 2024.09 | 高精度提取 | 多格式支持 | 中等 | 科研文献 |
| InternVL3-14B | 14B | 2024.12 | 多模态MLLM | MMMU SOTA | 高 | 复杂视觉任务 |
| Ovis2.5-9B | 9B | 2025.08 | 原生分辨率 | OpenCompass 78.3 | 中高 | 高精度OCR |
| dots.ocr | 1.7B | 2025.07 | 轻量统一 | OmniDocBench SOTA | 低 | 多语言处理 |
| OCRFlux-3B | 3B | 2024.11 | 跨页合并 | EDS 96.7% | 中等 | PDF批处理 |
| MonkeyOCR-pro-3B | 3B | 2025.06 | SRR范式 | 速度0.84页/秒 | 中等 | 结构化解析 |
OCR模型选型 - 详细评估指标合并表格
主要评估数据汇总表
基于各模型在相同benchmark上的详细评估指标数据:
OmniDocBench 详细指标对比表

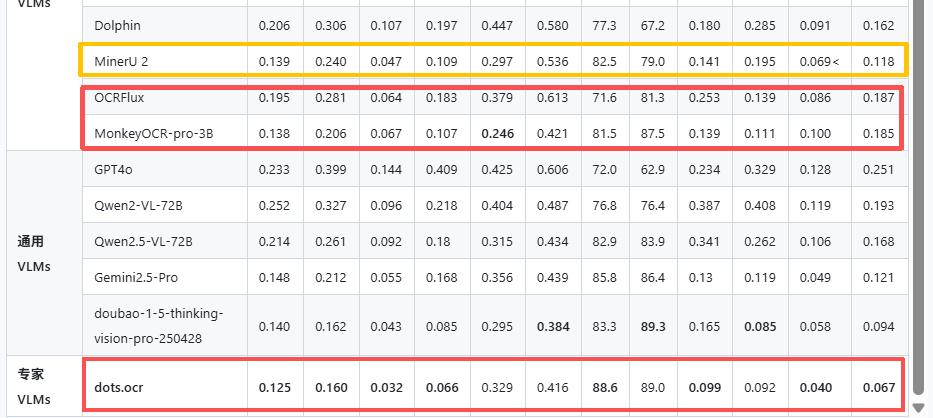
MinerU作为文档解析工具性能其实也还不错,之前我一直在用的ragflow的deepdoc还有maker等这几个里面好像属minerU2性能最强。
| Model | Overall Edit↓ | Text Edit↓ | Formula Edit↓ | Table TEDS↑ | Table Edit↓ | Read Order Edit↓ |
|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | |
| MinerU2 | 0.139 | 0.240 | 0.047 | 0.109 | 0.297 | 0.536 | 0.825 | 0.790 | 0.141 | 0.195 | 0.069 | 0.118 |
| MonkeyOCR-pro-3B | 0.138 | 0.206 | 0.067| 0.107 | 0.246 | 0.421 | 0.815 | 0.875 | 0.139 | 0.111 | 0.100 | 0.185 |
| dots.ocr | 0.125 | 0.160 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6% | 89.0% | 0.099 | 0.092 | 0.040 | 0.067 |
| OCRFlux-3B | 0.195|0.281 | 0.064|0.183 | 0.379|0.613 | 0.716|0.813 | 0.253|0.139 | 0.086|0.185 |
| InternVL3-14B | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark |
| Ovis2.5-9B | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark | 未在此benchmark |
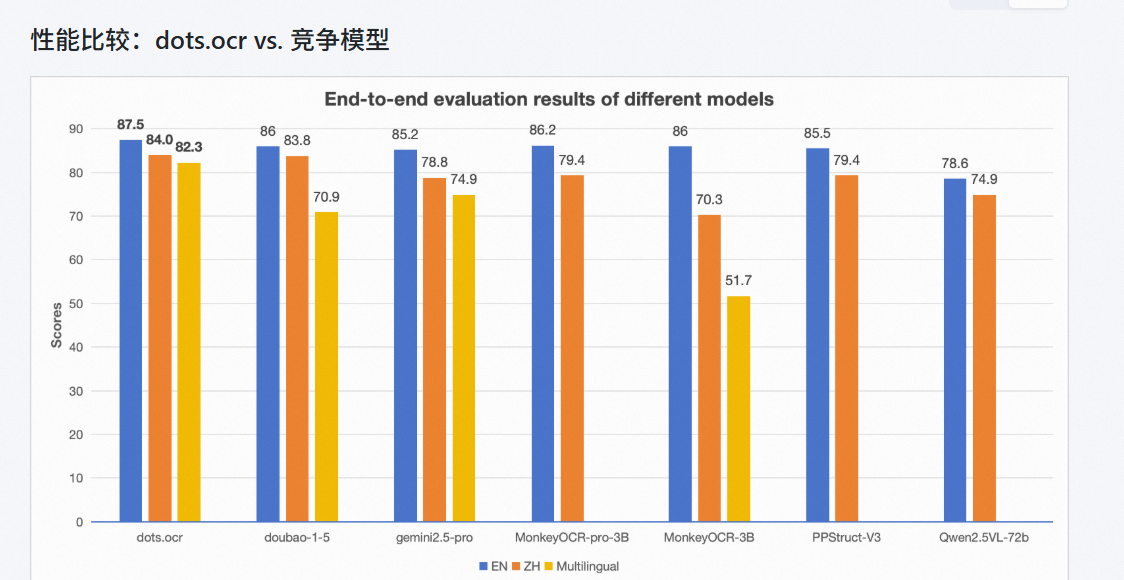
专门的ocr模型有OCRFlux、MonkeyOCR-pro-3B、dots.ocr,但是就OCRFlux-3B支持跨页表格处理 dots.ocr、MonkeyOCR-pro-3B都不支持的 还有dots.ocr有反馈>2000万像素图像需要降采样,否则会丢失细节;还有图片解析有盲区不支持流程图信息图解析(我实测过属实 流程图的文字ocr不出来就当成图片);特殊字符___`需要prompt优化一下 这都小问题 还有就是高吞吐量处理需要进行优化
dots.ocr支持图像和 PDF 输入。它能够处理包含文本的图片(如 JPEG、PNG 等格式)以及 PDF 文件中的文本提取任务。对于 PDF,通常会先将每一页转换为图片(如果是扫描版 PDF),然后进行 OCR 处理,提取其中的文本。OCRFlux好像仅支持图像输入,MonkeyOCR目前不支持拍摄文档
刚好这三个模型在OmniDocBench中已经测评过 可以看出dots.ocr的性能应该是最强的,我也试了一下个人觉得dots.ocr在日常ocr应该是没啥问题而且性能够好 但是在面对某些情况还是要处理的 像跨页表格的话可以配上merge指令或者加个xboost或者其他的检测处理 然后吞吐量还是需要测一下
跨页表格处理:
- 仅 OCRFlux-3B 支持跨页表格/段落合并
- 其他模型需要配合额外处理方案
然后是多模态非专业VLM模型 我看了一下比较惊喜的就是Ovis2.5-9B和InternVL3-14B-Instruct
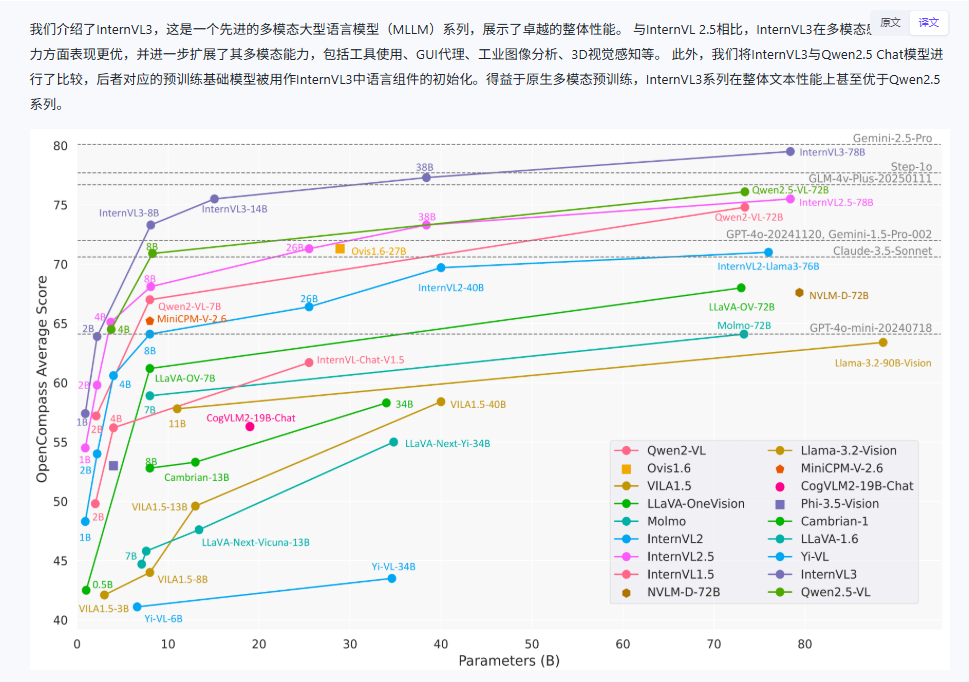

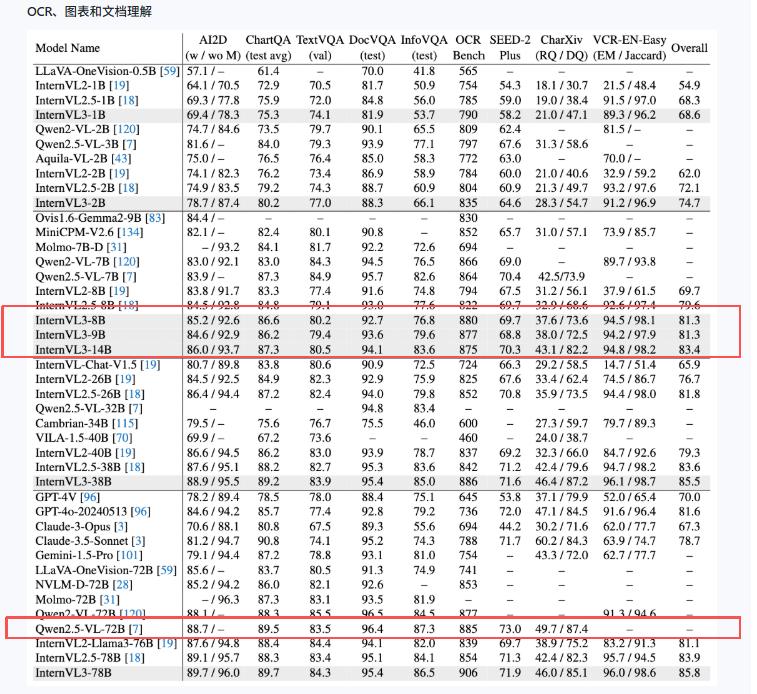

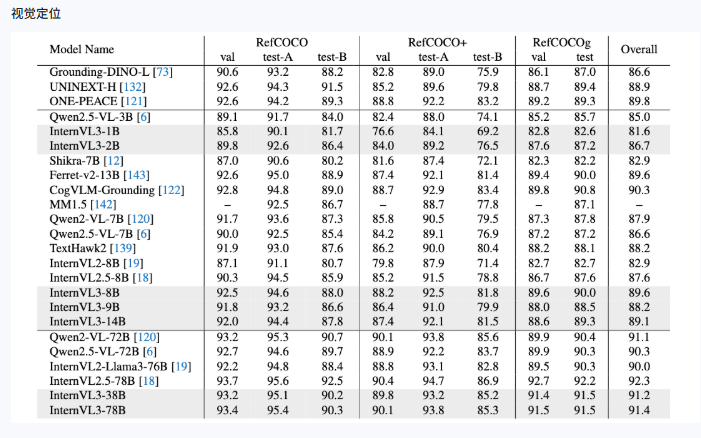
OCRBench v2 Leaderboard
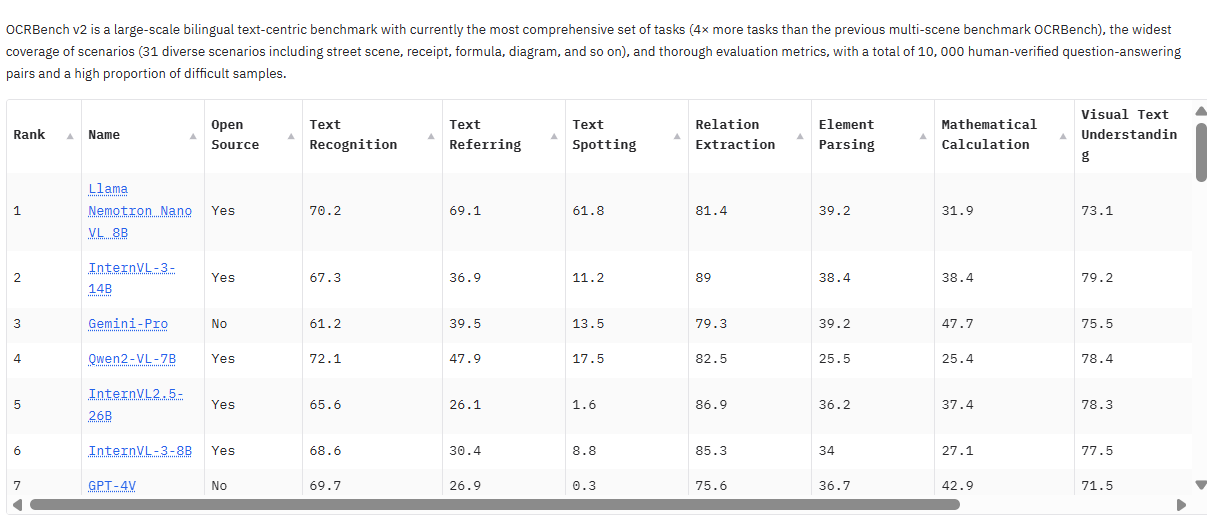
InternVL3-14B-Instruct或者InternVL3-8B-Instruct还是令我比较惊喜的 这两个还是基于Qwen2.5-14B微调训练的本身2.5能力就不弱 但是从上面的数据可以看出在只有8B或者14B的参数量下性能还是比较接近Qwen2.5-72B 不管是多模态推理还是OCR方面 Qwen2.5-72B 我是用过的ocr的效果还是可以的 并且在参数量少了这么多的情况下幻觉也和那几个差不多 所以InternVL3-8B-Instruct性能这么接近72B我觉得性价比还是挺高的也可以考虑,能够不仅识别文本,还能理解、推理、对话和执行复杂的多模态任务
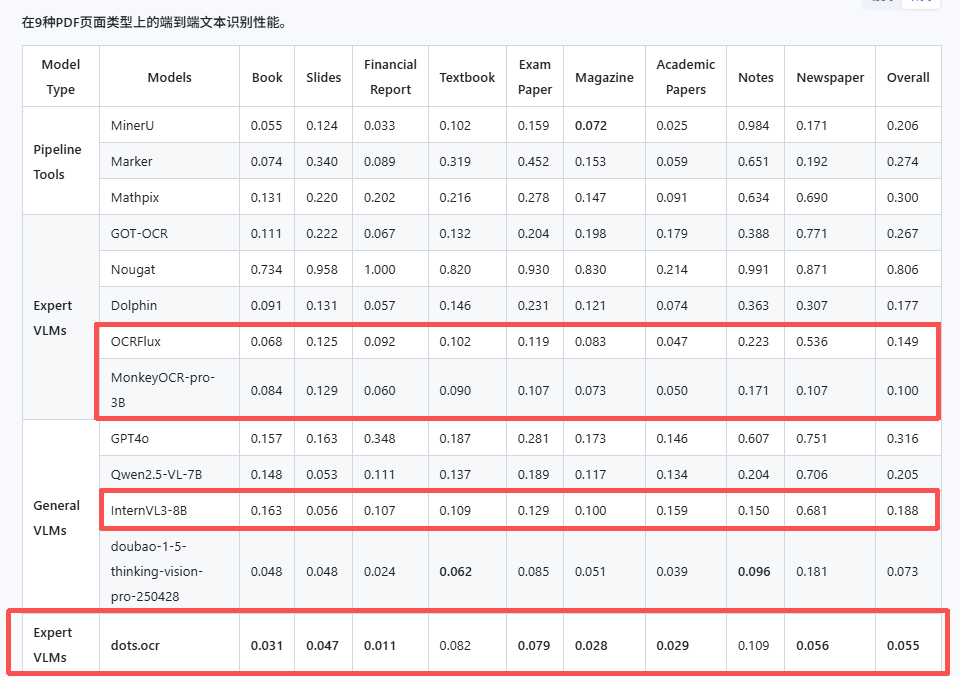
但是如果在专业ocr方面,InternVL3-8B-Instruct多模态这几个模型和专门ocr模型还是有点差距的 这么看dots.ocr的性能确实很强
下面是另外一个多模态模型Ovis2.5-9B



Ovis2.5-9B 在 OpenCompass 多模态评估套件中达到了 78.3 的平均得分(在参数少于 40B 的开源 MLLM 中说是处于 SOTA 水平)。但是我目前没有找到InternVL3-14B-Instruct和Ovis2.5-9B的直接对比的详细数据。
综上
Ovis2.5-9B 在 OpenCompass 多模态评估套件中达到了 78.3 的平均得分(在参数少于 40B 的开源 MLLM 中说是处于 SOTA 水平)。但是我目前没有找到InternVL3-14B-Instruct和Ovis2.5-9B的直接对比的详细数据。
综上
专业ocr模型的话目前了解到性能最顶的就是dots.ocr 然后doubao-1-5-thinking-vision-pro-250428豆包的效果也不错但是目前闭源 多模态VLM的话性价比较高的是Ovis2.5-9B 当然针对垂领的效果可能有偏差毕竟每个模型擅长的部分不一样



















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









