






 该文详细介绍了使用PaddleOCR2.6版本进行OCR系统训练的过程,包括前期准备(代码、标注工具),环境配置(CPU或GPU环境,库安装),数据集准备,模型训练(det和rec模型),转换成推理模型以及最终的测试步骤。提供了相关工具和配置文件修改的指导。
该文详细介绍了使用PaddleOCR2.6版本进行OCR系统训练的过程,包括前期准备(代码、标注工具),环境配置(CPU或GPU环境,库安装),数据集准备,模型训练(det和rec模型),转换成推理模型以及最终的测试步骤。提供了相关工具和配置文件修改的指导。
目录
2.2 修改配置文件的参数(我这里以det_mv3_db.yml为例,需要修改的参数都差不多)
3.2 修改配置文件的参数(我这里以rec_chinese_lite_train_v2.0.yml为例,需要修改的参数都差不多)
一、前期准备
1、代码
目前用的是2.6版本的
下面这个是官方的,可能已经更新了
2、标注工具
或者直接安装
pip install PPOCRLabel # 安装
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签二、环境配置
CPU环境:
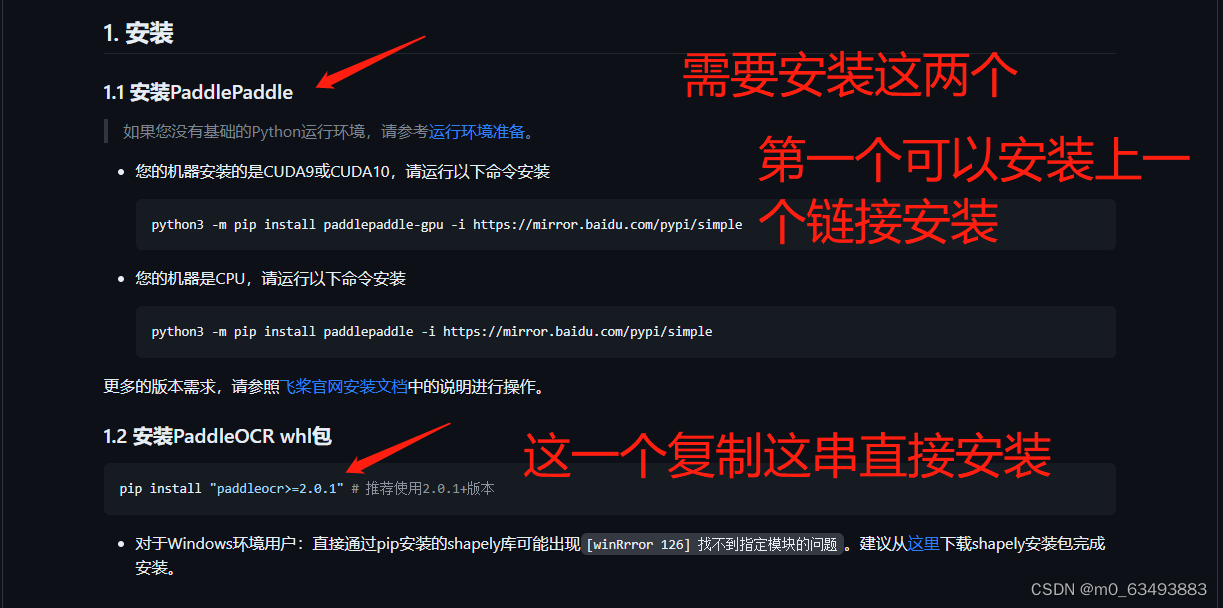
库的安装:
在文件配置完后,训练时看缺什么库就安什么库
三、数据准备
1、数据集准备
2、数据集结构
2.1 数据集文件结构
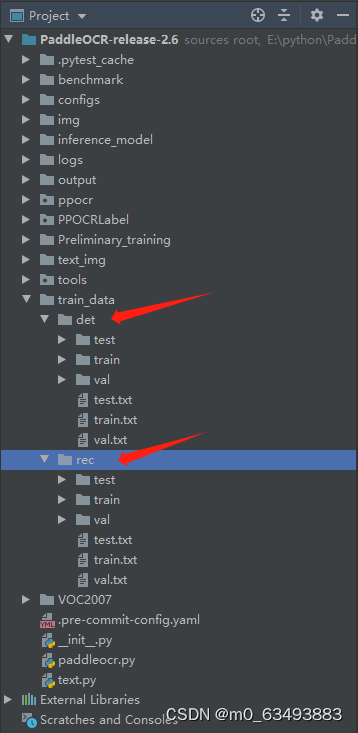
四、训练模型
1、训练模型获取
github可能下载不了模型,只能用gitcode的
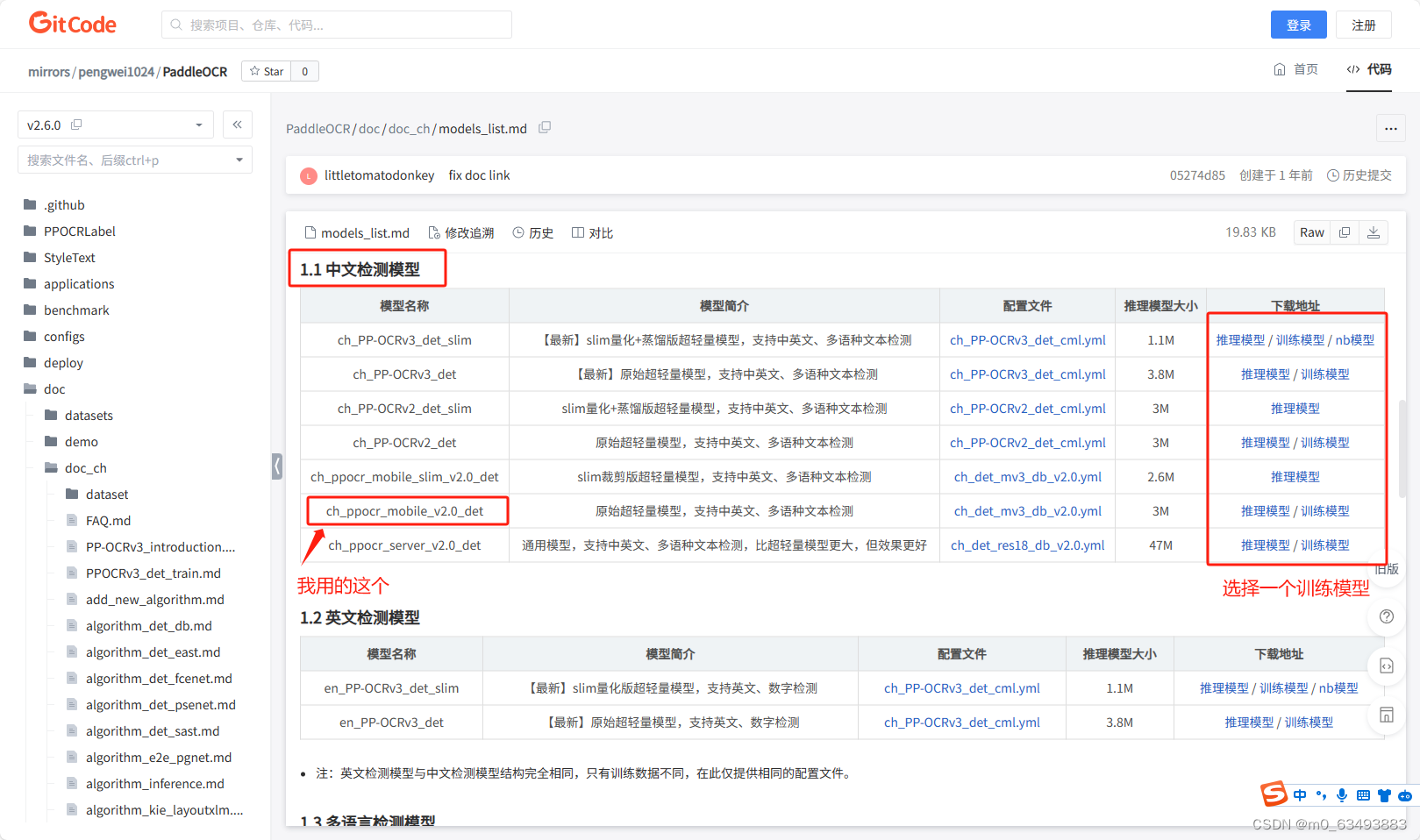
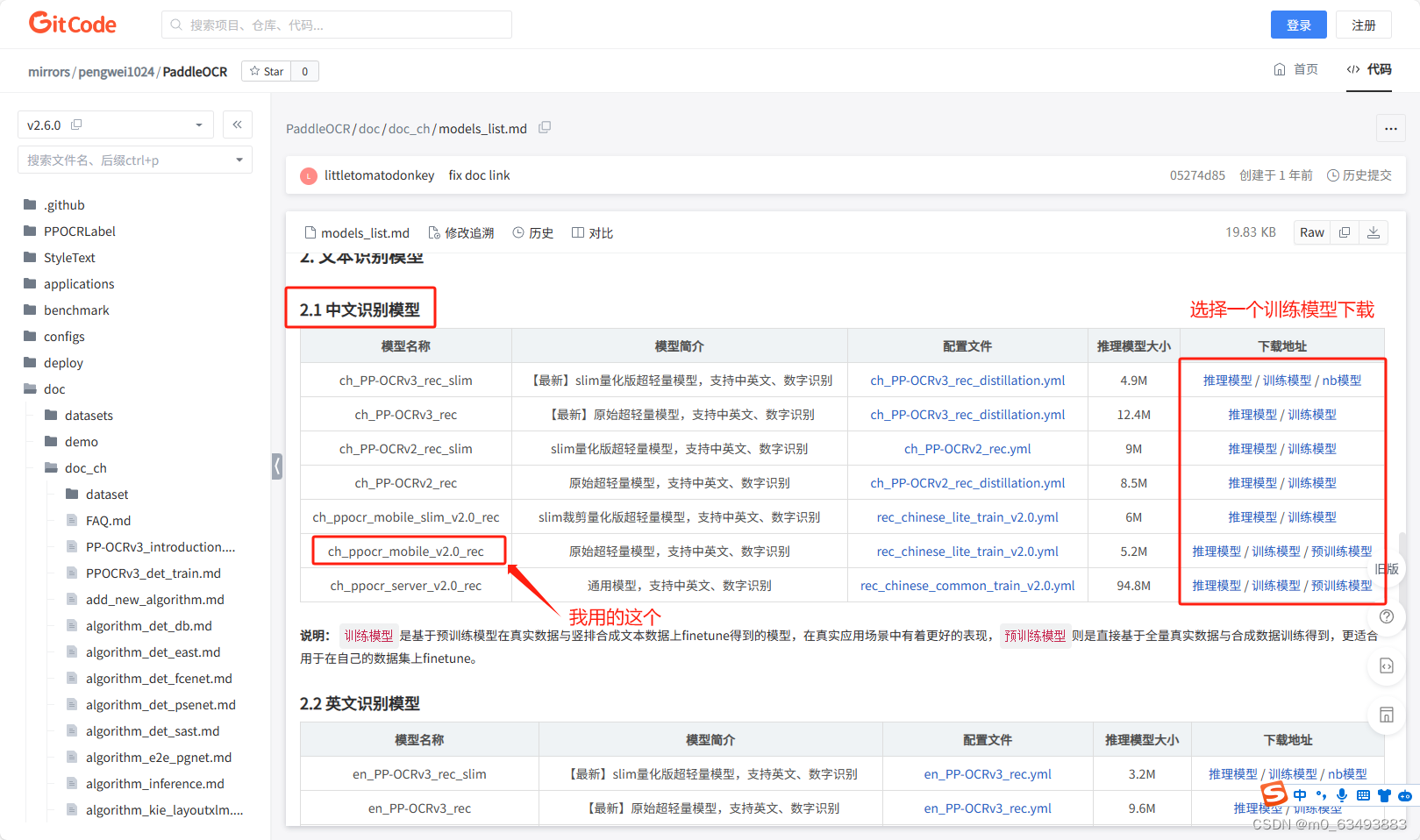
下载之后在PaddleOCR-release-2.6根目录下建立Preliminary_training文件夹,并将训练模型解压至该文件夹下。如下图所示:
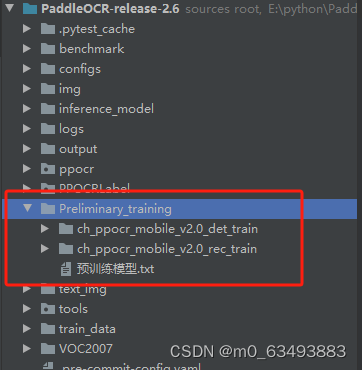
2、det模型训练
2.1 找到det模型对应的yml文件
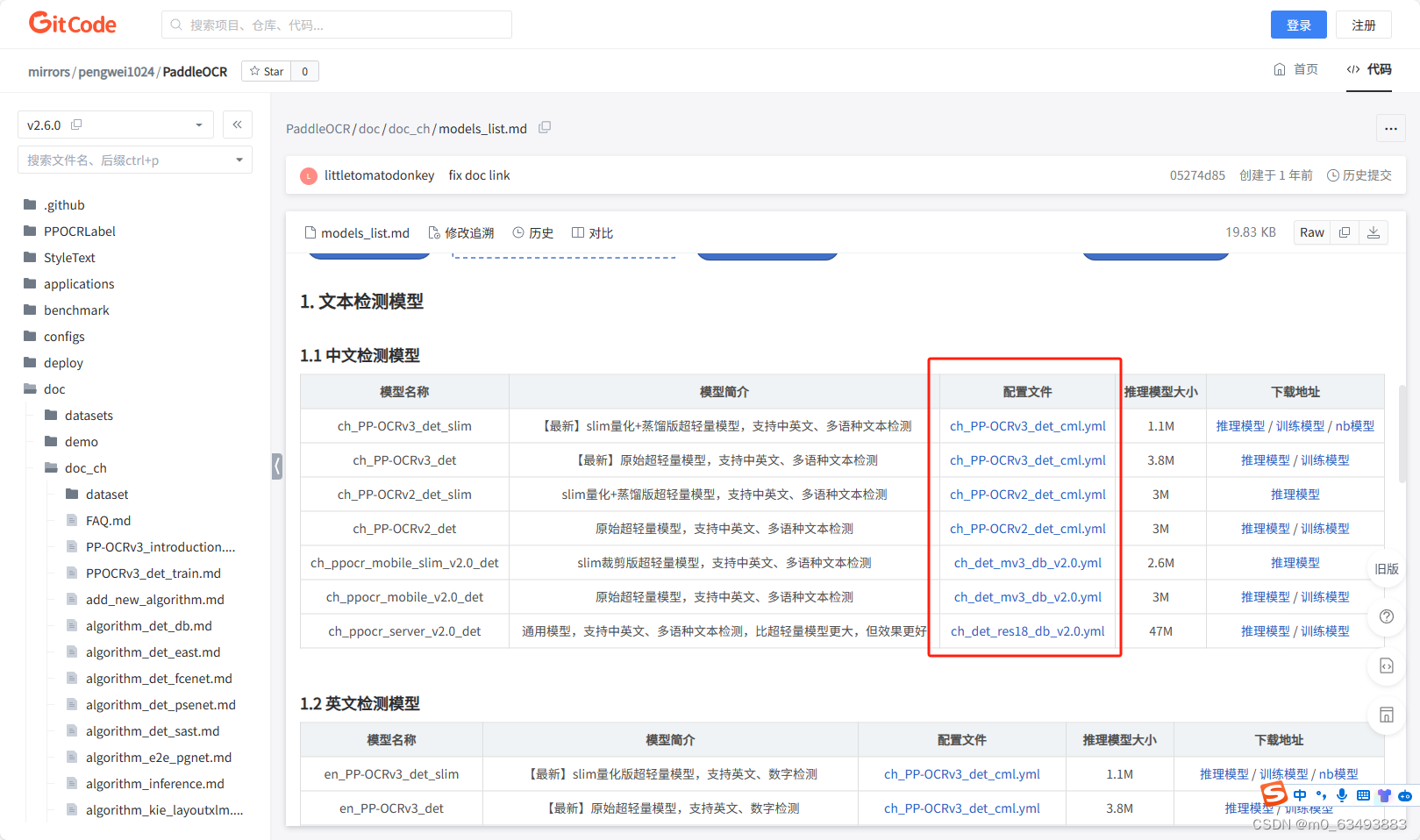
在项目的configs里面找到需要修改的yml文件
2.2 修改配置文件的参数(我这里以det_mv3_db.yml为例,需要修改的参数都差不多)
2.2.1 第一部分
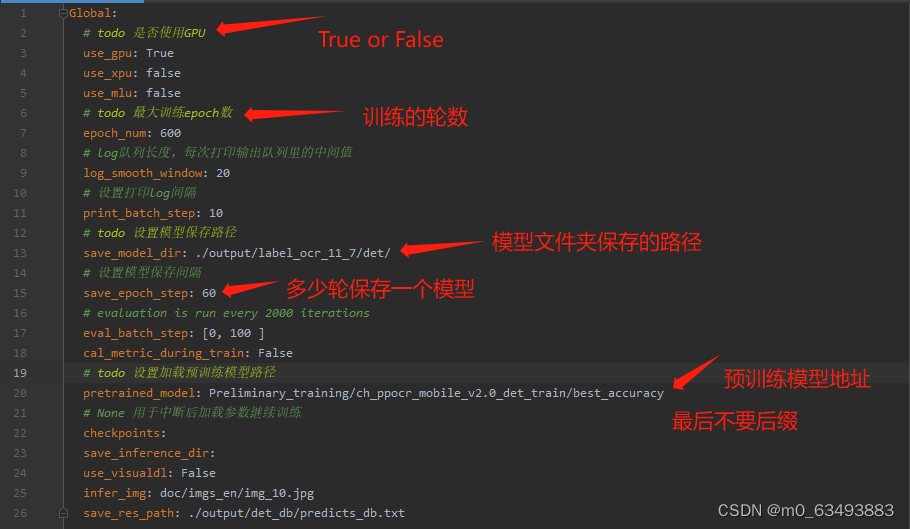
2.2.2 第二部分
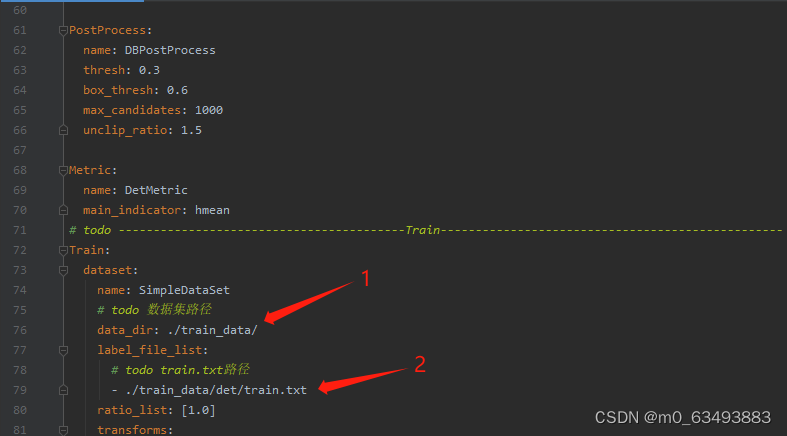
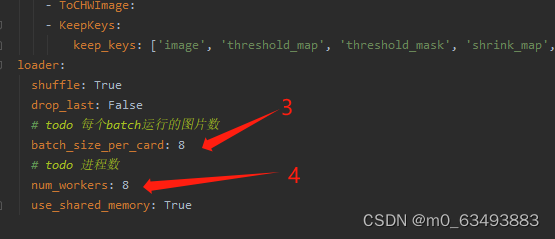
2.2.3 第三部分
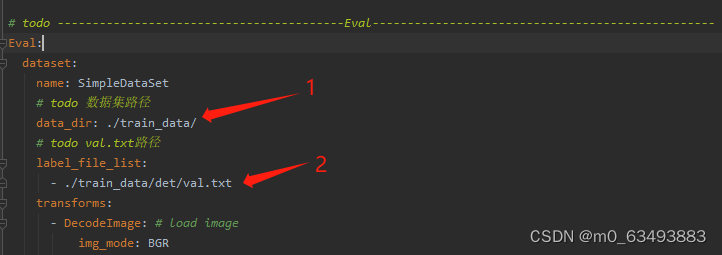
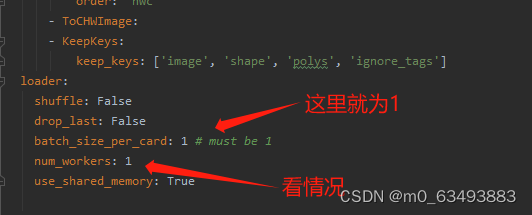
2.3 开始训练
激活环境进入到PaddleOCR-releas-2.6根目录下。输入以下指令开始模型训练
python tools/train.py -c configs/det/"自己选的 det 的yml文件路径"出现以下画面则代表成功
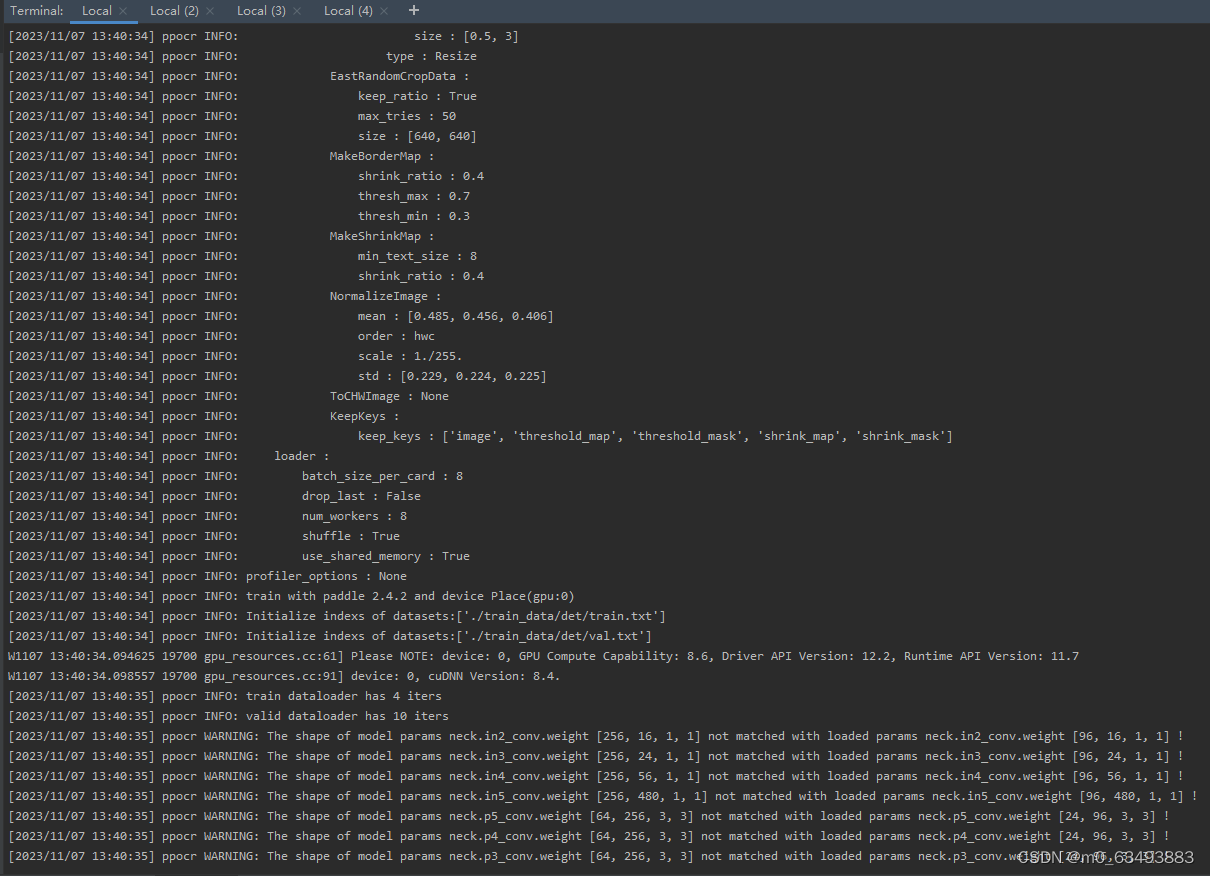
3、rec模型训练
3.1 找到rec模型对应的yml文件
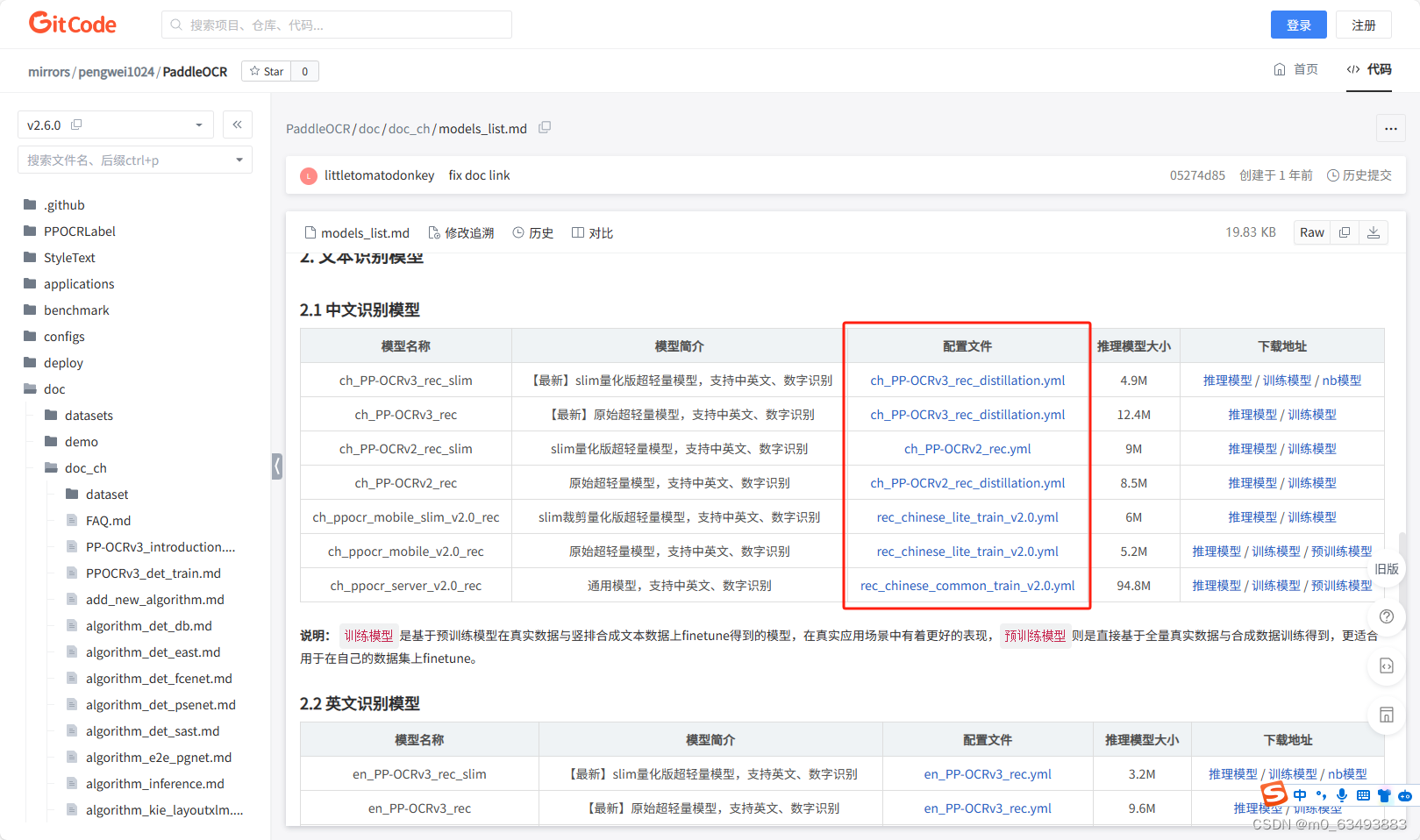
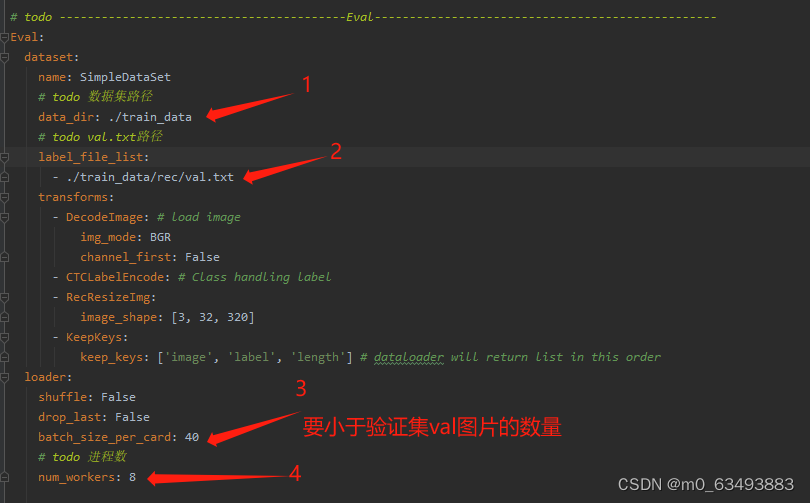
3.2 修改配置文件的参数(我这里以rec_chinese_lite_train_v2.0.yml为例,需要修改的参数都差不多)
3.2.1 第一部分
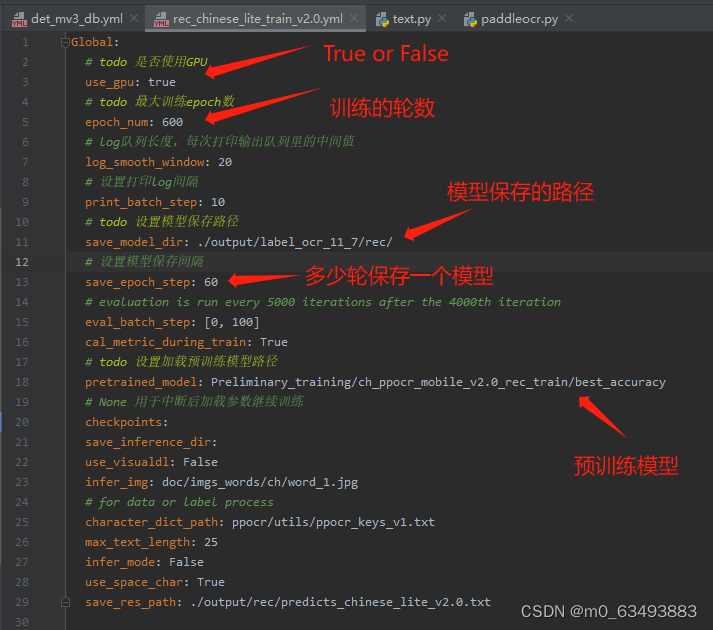
3.2.2 第二部分
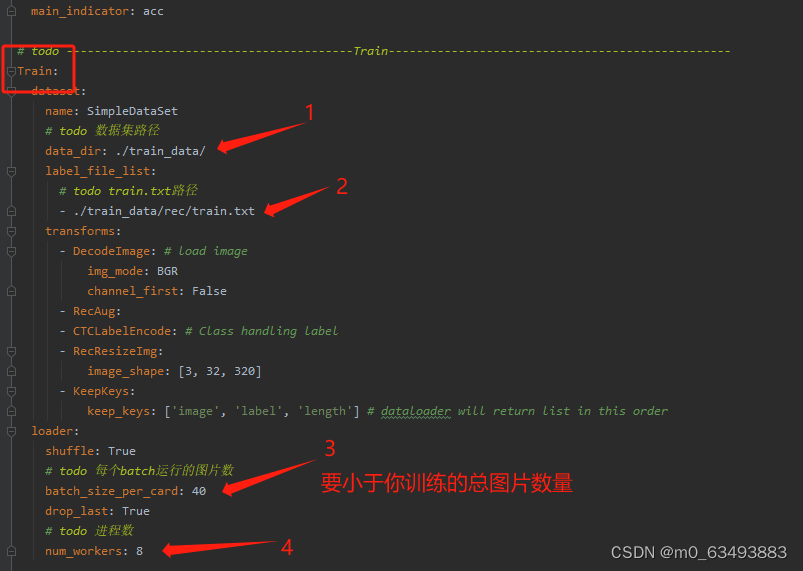
3.2.3 第三部分
3.3 开始训练
激活环境进入到PaddleOCR-releas-2.6根目录下。输入以下指令开始模型训练
python tools/train.py -c configs/rec/"自己选的 rec 的yml文件路径"出现以下画面则代表成功
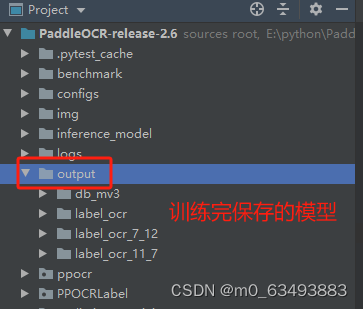
最后训练好可以在./output 下面查看训练后的模型
五、转换成推理模型
需要将生成的转换成为infer文件 命令如下:
需要修改三个地方,改的时候去掉引号
# 将生成的模型转换成 infer 文件 最好的模型轮数 保存的目录地址
python tools/export_model.py -c configs/"det or rec 对应的yml地址" -o Global.checkpoints=./output/"需要转换的模型地址"/best_accuracy Global.save_inference_dir=./"模型保存地址"/例如我的是
det 和 rec
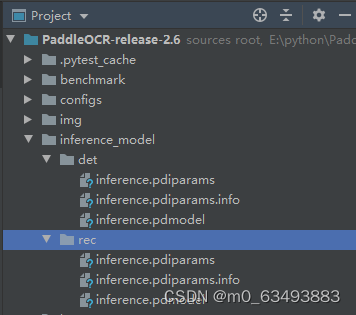
python tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./output/label_ocr_11_7/det/best_accuracy Global.save_inference_dir=./inference_model/det/python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./output/label_ocr_11_7/rec/best_accuracy Global.save_inference_dir=./inference_model/rec/转换后的模型会保存在你创建的目录下
六、测试
将det和rec模型替换成自己路径下的模型即可
这个代码是预测文件夹的示例
import os
from PIL import Image
def batch_ocr(input_dir, output_dir):
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(det_model_dir='inference_model/det',rec_model_dir='inference_model/rec', use_angle_cls=True, use_gpu=False)
# 遍历输入文件夹下的所有图片文件
for filename in os.listdir(input_dir):
if filename.endswith('.jpg') or filename.endswith('.jpeg') or filename.endswith('.png'):
img_path = os.path.join(input_dir, filename)
# 进行 OCR 识别
result = ocr.ocr(img_path, cls=True)[0]
# 获取识别结果的坐标、文本和置信度
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
# 读取原始图片
image = Image.open(img_path).convert('RGB')
# 在原始图片上绘制识别结果
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
# 保存绘制结果的图片
output_path = os.path.join(output_dir, filename)
im_show.save(output_path)
if __name__ == '__main__':
# Ocr()
input_dir = r'text_img/Eval_img'
output_dir = r'text_img/result_img'
batch_ocr(input_dir, output_dir)七、问题记录
7.1 训练时卡在不动
比如卡在:During the training process, after the 0th iteration, an evaluation is run every 200这个报错
解决方法:重新安装下面三个库,注意版本必须为2.6(因为我用的就是2.6版本的代码)
7.2 训练时只有 latest文件,没有best文件
解决方法: 可能是当前没有训练出best最好的模型,可以再等等,后面会出现(遇到过一次)
7.3 模型训练的样子
模型训练不一定每一轮都会显示详情,也可能是这样的

参考文献:
PaddlePaddle / PaddleOCR Public训练自己的数据集

















 3082
3082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









