




CNN实战+OOP面向对象编程详解
本文适合已经了解CNN卷积基础原理的读者,将从代码实战角度深入讲解PyTorch中的CNN实现和面向对象编程应用。
📑 目录
- 第一部分:从简单开始 - 你的第一个CNN模块
- 第二部分:深入理解 - 卷积参数详解
- 第三部分:面向对象编程在PyTorch中的应用
- 第四部分:进阶实践 - 完整CNN模型构建
- 第五部分:实战演练 - 完整训练流程
第一部分:从简单开始 - 你的第一个CNN模块
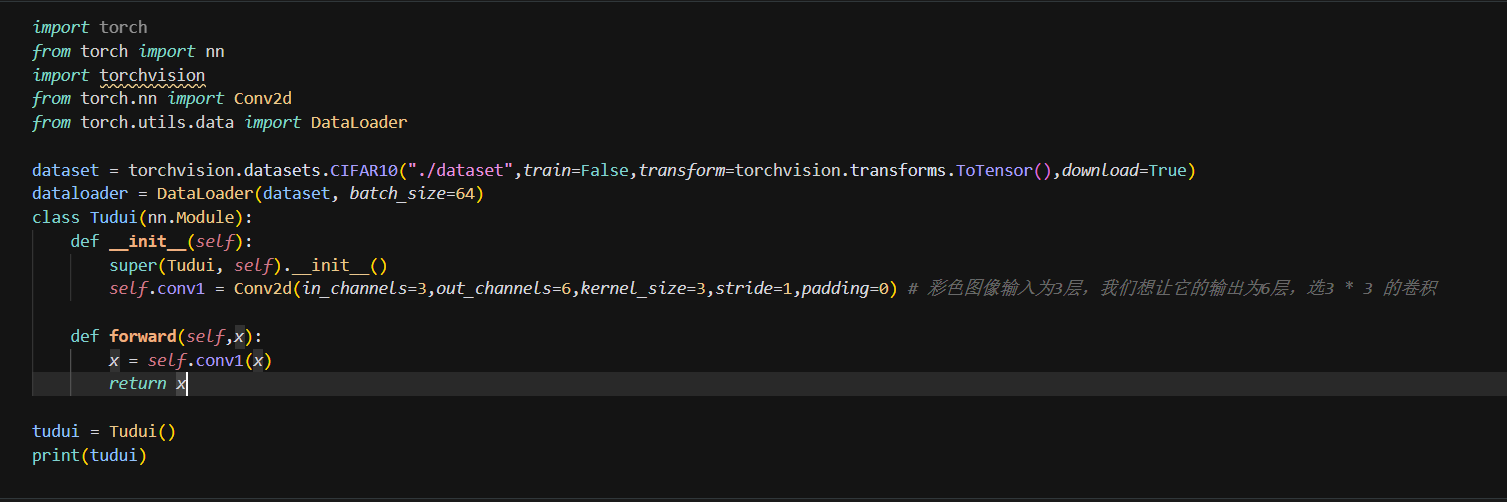
让我们从最简单的CNN模块开始,这段代码定义了一个基础的卷积神经网络模块(Tudui)(选自小土堆的代码):
🧱 类定义与继承
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
核心要点:
Tudui继承自nn.Module,这是PyTorch中所有神经网络模块的基类super()调用父类构造函数,让PyTorch正确注册参数和模块结构forward()方法定义了数据的前向传播路径
📊 数据流转示例
| 输入 | 卷积层处理 | 输出 |
|---|---|---|
[B, 3, H, W] | Conv2d(3→6) | [B, 6, H-2, W-2](无padding时) |
例如:输入 [1, 3, 32, 32] 的RGB图像 → 输出 [1, 6, 30, 30] 的特征图
第二部分:深入理解 - 卷积参数详解
🔍 Conv2d参数深度解析
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
| 参数 | 含义 | 影响 |
|---|---|---|
in_channels=3 | 输入通道数(RGB图像为3) | 决定接受什么样的输入 |
out_channels=6 | 输出通道数(使用6个不同的卷积核) | 决定提取多少种不同特征 |
kernel_size=3 | 卷积核大小(3×3) | 感受野大小,影响特征提取范围 |
stride=1 | 步长(每次移动1个像素) | 控制输出尺寸和计算密度 |
padding=0 | 边缘填充(不填充) | 是否保持原图尺寸信息 |
📐 输出尺寸计算公式
掌握这个公式,你就能预测任何卷积层的输出尺寸:
output_size = floor((input_size - kernel_size + 2×padding) / stride) + 1
实际计算示例:
输入: (1, 1, 5, 5)
卷积核: 3×3, stride=1, padding=0
计算过程:
output_height = (5 - 3 + 0) / 1 + 1 = 3
output_width = (5 - 3 + 0) / 1 + 1 = 3
结果: (1, 1, 3, 3)
🛠️ padding的妙用
| padding值 | 效果 | 使用场景 |
|---|---|---|
| 0 | 输出尺寸缩小 | 特征提取,降维 |
| 1 | 近似保持原尺寸 | 保留空间信息 |
| ‘same’ | 输出与输入尺寸完全相同 | 需要精确尺寸保持时 |
第三部分:面向对象编程在PyTorch中的应用
🎯 OOP三大核心特性
| 特性 | Python含义 | PyTorch中的体现 |
|---|---|---|
| 封装 | 数据和方法打包到类中 | 网络结构封装在自定义类中 |
| 继承 | 子类自动获得父类的所有属性和方法 | 继承nn.Module获得训练相关功能 |
| 多态 | 同一接口在不同类中有不同的实现方式 | 不同网络类重写forward()方法 |
🔗 1. 封装:模块化设计
封装让代码更整洁、更易维护:
class MyNet(nn.Module):
def __init__(self):
super().__init__()
# 数据(网络层)封装在类中
self.conv = nn.Conv2d(3, 6, 3)
self.relu = nn.ReLU()
def forward(self, x):
# 方法(前向传播逻辑)封装在类中
x = self.conv(x)
x = self.relu(x)
return x
# 外部使用者只需要简单调用,无需了解内部细节
net = MyNet()
output = net(input_tensor)
🏗️ 2. 继承:站在巨人的肩膀上
继承nn.Module后,你的网络自动拥有:
- ✅ 参数自动注册和管理
- ✅ GPU/CPU设备转换:
.cuda(),.cpu() - ✅ 训练/评估模式切换:
.train(),.eval() - ✅ 参数访问:
.parameters(),.named_parameters() - ✅ 模型保存/加载支持
关键代码:
super().__init__() # 🚨 千万不能省略!
🎭 3. 多态:一个接口,多种实现
class LinearNet(nn.Module):
def forward(self, x):
return self.fc(x) # 全连接网络的forward
class ConvNet(nn.Module):
def forward(self, x):
return self.conv(x) # 卷积网络的forward
# 统一的调用方式,不同的内部实现
for model in [LinearNet(), ConvNet()]:
output = model(input_data) # 多态体现
第四部分:进阶实践 - 完整CNN模型构建
🏗️ 构建一个完整的图像分类网络
网络架构设计:
输入[B,3,32,32] → Conv1[6] → ReLU → MaxPool → Conv2[16] → ReLU → MaxPool → Flatten → FC → 分类[10]
import torch
import torch.nn as nn
import torch.nn.functional as F
class CompleteCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# 特征提取部分
self.conv1 = nn.Conv2d(3, 6, kernel_size=5) # [3,32,32] → [6,28,28]
self.pool = nn.MaxPool2d(kernel_size=2, stride=2) # [6,28,28] → [6,14,14]
self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # [6,14,14] → [16,10,10]
# 池化后: [16,5,5]
# 分类器部分
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
# 特征提取
x = self.pool(F.relu(self.conv1(x))) # 卷积→激活→池化
x = self.pool(F.relu(self.conv2(x))) # 卷积→激活→池化
# 展平
x = torch.flatten(x, 1) # 保留batch维度,展平其他维度
# 分类
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 最后一层不加激活,交给损失函数处理
return x
📦 模块容器:让网络更灵活
| 容器类型 | 特点 | 适用场景 |
|---|---|---|
Sequential | 顺序执行,自动连接 | 线性网络结构 |
ModuleList | 列表管理,需手动控制执行顺序 | 动态深度、循环结构 |
ModuleDict | 字典管理,支持名称索引 | 条件分支、模块动态选择 |
Sequential示例:
self.feature_extractor = nn.Sequential(
nn.Conv2d(3, 6, 3),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(6, 16, 3),
nn.ReLU(),
nn.MaxPool2d(2)
)
ModuleList示例:
self.layers = nn.ModuleList([
nn.Linear(10, 10) for _ in range(5) # 动态创建5层
])
def forward(self, x):
for layer in self.layers:
x = F.relu(layer(x))
return x
第五部分:实战演练 - 完整训练流程
🎯 训练流程全览
📊 1. 数据准备(CIFAR-10示例)
import torch
import torchvision
import torchvision.transforms as transforms
# 数据预处理管道
transform = transforms.Compose([
transforms.ToTensor(), # PIL → Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到[-1,1]
])
# 训练集
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=64, shuffle=True, num_workers=2
)
# 测试集
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=64, shuffle=False, num_workers=2
)
🏗️ 2. 模型、损失函数和优化器配置
import torch.optim as optim
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 模型实例化
model = CompleteCNN(num_classes=10).to(device)
# 损失函数(多分类交叉熵)
criterion = nn.CrossEntropyLoss()
# 优化器(SGD + 动量)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 可选:学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
🔄 3. 训练循环
def train_model(model, trainloader, criterion, optimizer, num_epochs=5):
model.train() # 设置为训练模式
for epoch in range(num_epochs):
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for batch_idx, (inputs, labels) in enumerate(trainloader):
# 数据移到设备
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 模型预测
loss = criterion(outputs, labels) # 计算损失
# 反向传播
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 统计信息
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# 打印进度
if batch_idx % 100 == 99:
avg_loss = running_loss / 100
accuracy = 100 * correct_predictions / total_samples
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Batch [{batch_idx+1}], '
f'Loss: {avg_loss:.4f}, '
f'Accuracy: {accuracy:.2f}%')
running_loss = 0.0
# 可选:更新学习率
scheduler.step()
# 开始训练
train_model(model, trainloader, criterion, optimizer, num_epochs=10)
📊 4. 模型评估
def evaluate_model(model, testloader):
model.eval() # 设置为评估模式
correct = 0
total = 0
with torch.no_grad(): # 关闭梯度计算,节省内存
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'测试集准确率: {accuracy:.2f}%')
return accuracy
# 评估模型
final_accuracy = evaluate_model(model, testloader)
💾 5. 模型保存和加载
# 保存模型(推荐方式:只保存参数)
torch.save(model.state_dict(), 'best_model.pth')
# 保存完整信息
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'accuracy': final_accuracy,
}
torch.save(checkpoint, 'checkpoint.pth')
# 加载模型
def load_model(model_path, model_class, num_classes=10):
model = model_class(num_classes=num_classes)
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
return model
# 使用示例
loaded_model = load_model('best_model.pth', CompleteCNN)
🎓 总结与要点回顾
核心知识点梳理
| 阶段 | 关键技术点 | 核心代码 |
|---|---|---|
| 模型设计 | 继承nn.Module,重写forward | class MyNet(nn.Module) |
| 参数配置 | 卷积层参数、输出尺寸计算 | Conv2d(in_ch, out_ch, kernel_size) |
| 数据处理 | DataLoader、数据预处理 | transforms.Compose([...]) |
| 训练过程 | 前向传播、反向传播、参数更新 | loss.backward(), optimizer.step() |
| 模型评估 | 准确率计算、模型状态切换 | model.eval(), torch.no_grad() |
💡 最佳实践提示
- ✅ 始终使用
super().__init__()初始化父类 - ✅ 合理设置batch_size和学习率
- ✅ 训练时使用
.train(),推理时使用.eval() - ✅ 使用
torch.no_grad()节省推理时的内存 - ✅ 定期保存模型checkpoints
通过本文的学习,你应该已经掌握了PyTorch中CNN的完整实现流程和面向对象编程的核心概念。现在可以开始你的深度学习实战之旅了!🎉


















 5万+
5万+



 到【灌水乐园】发言
到【灌水乐园】发言








