







AI往往是为了最优化解决生活中的某类问题。此时首先需要考虑针对具体任务来构造一个目标函数(定个目标),然后摸索使目标函数取得最大/最小值(达成目标)的方法。
目标函数是建立在损失函数的基础上(贴近目标->降低损失),而损失函数则是为了衡量算法预测值与事物真实值之间的差异,以确认AI模型在变得越来越好(损失越来越小)。
0、提纲:
-
是猫是狗?(分类任务)
-
房价预测?(回归任务)
-
小结
1、是猫是狗?(分类任务)
“猫狗问题”,指的是给定一张图片判定图像内容是猫还是狗,它是计算机视觉领域经典的图像二分类问题。
该任务目标很明确——准确判定图像是猫还是狗,其损失函数是分类任务中最常用的交叉熵损失(Cross-Entropy Loss)。
它是为了衡量模型预测【推测】的概率分布与真实标签【实际】之间的差异。AI的目标就是缩小这个差异了。
-
数学公式如下:
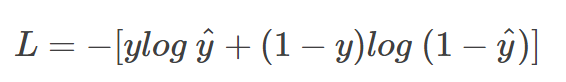
上图中,y是真实标签(假定猫为0、狗为1),而y_hat(y帽子^)是模型预测为正类(推测是狗)的概率。
-
怎么来直观理解呢?
我们现在给AI一个具体的样本(一张图片):
(1)给定一只狗的图片,那它的真实标签y=1(假定狗为1),于是:损失函数L = -log(y_hat)
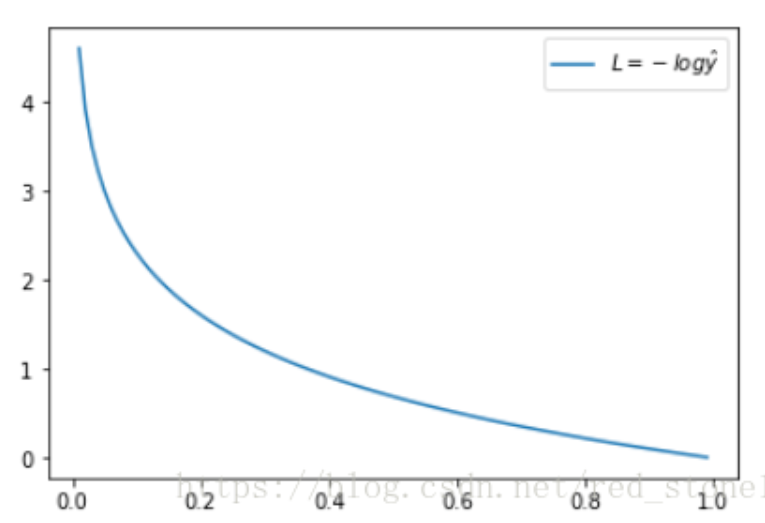
看上面L 函数的图形,简单明了!其中,横坐标是推测值y_hat,纵坐标是交叉熵损失函数 L的计算值。显然,横坐标(推测值y_hat)越靠近真实样本标签1(狗),纵坐标(损失函数L)就越小;而横坐标(推测值y_hat)越接近0(猫),纵坐标L就越大。
因此,函数L的变化趋势完全符合实际需要的情况!【目标正是缩小L值——让模型推测这个图片为狗(标签1)】。
(2)给定一只猫的图片,那它的真实标签y=0(假定猫为0),于是:损失函数L = -log(1-y_hat)

再看下此时L的图形,此时,横坐标(推测值y_hat)越接近其真实样本标签 0(猫),损失函数 L就越小;而横坐标(推测值y_hat)越接近1(狗),纵坐标L就越大。
因此,函数的变化趋势也完全符合实际需要的情况!【目标正是缩小L值——让模型推测这个图片为猫(标签0)】。
看完上面的内容,相信你已经理解:AI模型训练的目标,正是通过最小化交叉熵损失函数(L),让我们可以使模型预测值(y_hat)的概率分布逐步接近真实(y)的概率分布。
2、房价预测?(回归任务)
房价预测问题是利用历史数据和各种特征(如位置、面积、房间数量等)来估算某个特定房产的价格。它是一个经典的AI回归任务,旨在根据多个影响因素预测房屋的市场价格。接下来介绍一个常用的回归任务损失函数:均方差损失(Mean Square Error,MSE)。
-
MSE
MSE又称为二次损失、L2损失。它通过计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣。预测值和真实值越接近,两者的均方差就越小。
假如现在有 n 个训练数据 xi,每个训练数据 xi 的真实输出为 yi,而模型对 xi 的预测值为 y^i。则该模型在 n 个训练数据下所产生的均方误差损失如下:

-
一个直观例子:
假如现在喂给模型1个样本,它的真实目标值为100。假设预测范围(X 轴)在-10000到10000之间,我们绘制MSE函数曲线如下:
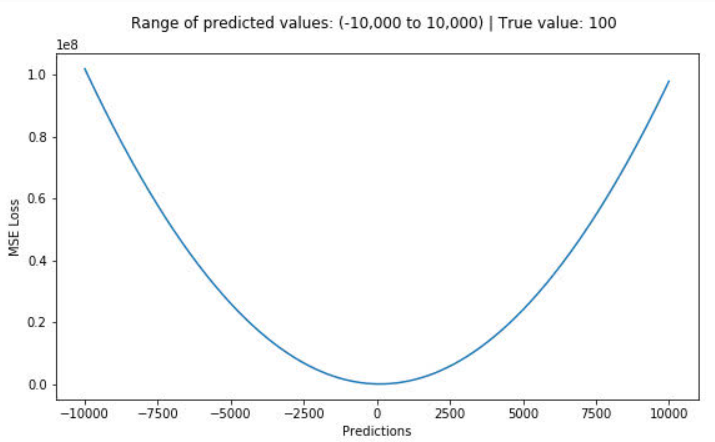
可以看到,当预测值(X 轴)越接近100时,MSE损失值(Y 轴)越小。
3、小结
本文介绍了两类最主流AI任务(分类/回归)中主流的目标函数(损失函数),让读者初步了解AI是奔着什么目标去精进的。
当今流行的语言大模型,也往往是建立在上述基础之上。比如,文字生成任务可以简单理解为根据前面的文本来推测生成下一个最合适的词(Token),其末端也是对候选词(于上万个词的大词表中)进行分类。
复杂的AI任务往往需要设计更复杂的目标函数。比如一些图像目标检测任务(如自动驾驶过程中识别车辆、人等目标),会引入如平衡L1损失(Balanced L1 Loss)来调整两个子任务(分类/回归)损失的权重以改进模型训练。
后续还会更新一篇来讲述:如何衡量“文生图”效果?(分布差异)、ChatGPT如何奖励好的回答?(排序任务)。敬请关注~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









