




出发点:
2024年1月份,斯坦福华人团队开发的“炒虾机器人”Mobile ALOHA出圈。仅用50个人工演示就能够让机器人始终如一地完成一项任务(如炒菜、洗碗、开柜门、乘电梯等)。重要的是,成本仅为20万元出头,且全部开源。
期待收获对“多模态AI模型赋能机器人(具身智能)”、“模仿学习”、“行为克隆”多一点认知。
提纲:
- 项目原理介绍
- 算法运行情况
- 附录及更多
一、项目原理介绍

1、硬件

依据官方硬件组装教程,主要组件包括:
轮式底盘:AgileX Tracer 价格:$6,999.95 x 1个,可承载100kg,移动速度可达1.6m/s
从动臂:ViperX 300,6自由度 价格:$6,129.95 × 2个
主动臂:WidowX 250,6自由度 价格:$3,549.95 × 2个
笔记本:Lambda Tensorbook i7 + 3070Ti (8GB) 价格:$2,399.00 x 1台
电池组:1.26 千瓦时,14 公斤 价格:$699.00 × 2个
相机:Logitech C922x,RGB 480×640,两个在从动臂腕部,一个俯视前方,价格:$98.35 x 3个硬件代码位于:https://github.com/MarkFzp/mobile-aloha
- 包含:启动机器人和摄像头的Ros代码 远程操作和数据收集的Python代码。
- 已验证运行环境为:
- ✅ Ubuntu 18.04 + ROS 1 noetic
- ✅ Ubuntu 20.04 + ROS 1 noetic
- 数据存储格式为:hdf5
2、算法
2.1 模仿学习(Imitation Learning)
参看模仿学习简洁教程:
- 普遍认为模仿学习有两大类算法:行为克隆(Behavioral Cloning)和对抗式模仿学习(Adversarial Imitation Learning)。
- 行为克隆算法尝试最小化智能体策略和专家策略的动作差异,把模仿学习任务归约到常见的回归或者分类任务。而对抗式模仿学习算法则是通过逆强化学习(Inverse Reinforcement Learning)来构建一个对抗的奖赏函数,然后最大化这个奖赏函数去模仿专家行为。
2.2 核心算法
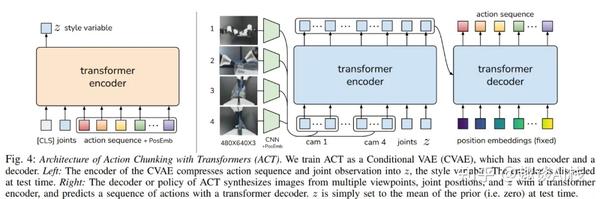
Mobile ALOHA 运用行为克隆算法,主体采用变分自编码器(Variational Autoencoder,VAE),其Encoder和Decoder组件的内部均使用Transformer架构(当前主流大型语言模型如GPT中均使用)。
训练时,上图左侧的Encoder部分依据人工示教数据生成风格变量Z分布,再喂给上图右侧的Decoder部分。
算法延用团队前作ALOHA(Static ALOHA、桌面固定式系统)的Action Chunking with Transformers (ACT) ,将来自多个视点的图像和关节位置作为输入并预测一系列动作。
在ACT基础上,Mobile ALOHA将移动底座的线速度和角速度添加到输入向量中,并减少1个视角(前部Front)输入。
- 输入(观测值):3视角图像(480×640 image x 3) + 14维的从臂关节位置(6DOF × 2 + 1 Gripper爪 × 2)
- 输出(动作):14维的主臂关节位置 + 2维的底盘线速度和角速度
直观来说,该算法试图模仿人类操作员在给定当前观察结果的后续时间步骤中会做什么动作。

- ACT算法关键点包括:
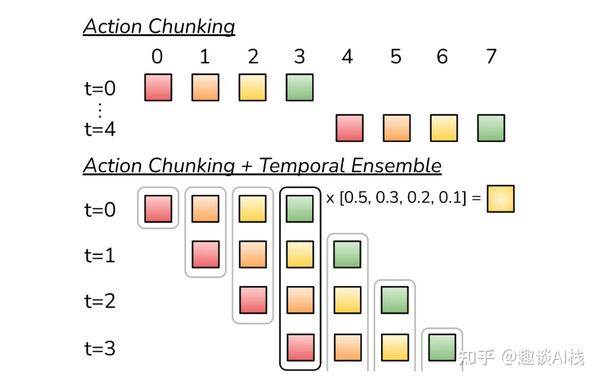
- 1)动作分块(Action Chunking):将一系列动作分成块(k个时间步),一次预测接下来k个时间步的目标关节位置,减小视界(减小k倍),以避免累计复合误差。
- 2)时间集成(Temporal Ensemble):对预测的每个时间步的动作,指数加权之前时间步的预测结果,让执行动作平滑顺畅。

2.3 数采与训练
数据采集:由操作员使用主动臂来操控机器完成一系列动作,在运动的过程中,机器会记录各个关键的运动轨迹,作为训练数据。
联合训练(Co-training):对mobile和static数据样本的占比相同,针对两者差异进行数据处理(zero-pad)。

二、算法运行情况
1、代码介绍
代码位于:https://github.com/MarkFzp/act-plus-plus
亦可参看国内Fork微修版本:https://github.com/huiwenzhang/act-plus-plus
imitate_episodes.py,训练和评估 ACT
detr,ACT 的模型定义 修改自 DETR
sim_env.py,具有 joint space control的 Mujoco + DM_Control 环境
scripted_policy.py,模拟环境的脚本化策略
constants.py,跨文件共享的常量
utils.py,数据加载和辅助函数等实用程序
visualize_episodes.py,可视化 .hdf5 数据集2、运行环境
- CPU:12th Gen Intel(R) Core(TM) i9-12900K【16核24线程】
- GPU:NVIDIA GeForce RTX 3080 Ti【12G显存】
- 内存:32G
- 系统:Ubuntu 20.04.4 LTS
3、数据准备
数据集分为两类,分别是实际采集的数据和仿真数据。作者提供下载地址(需科学上网):
- 实际数据:https://drive.google.com/drive/folders/1FP5eakcxQrsHyiWBRDsMRvUfSxeykiDc
- 仿真数据:https://drive.google.com/drive/folders/1gPR03v05S1xiInoVJn7G7VJ9pDCnxq9O
由于不具备实际硬件支持,本文以仿真数据完成模型训练及推理。

# 仿真数据,也可以自主生成:
python3 record_sim_episodes.py --task_name <task_name> --dataset_dir <data save dir> --num_episodes 50 --onscreen_render4、运行效果
4.1 数据可视化:下载数据后,在constants.py中指定文件路径DATA_DIR
# 仿真数据可视化:
python3 visualize_episodes.py --dataset_dir <data save dir> --episode_idx 0
# 实际数据可视化,可使用https://github.com/MarkFzp/mobile-aloha/tree/main/aloha_scripts中的代码:
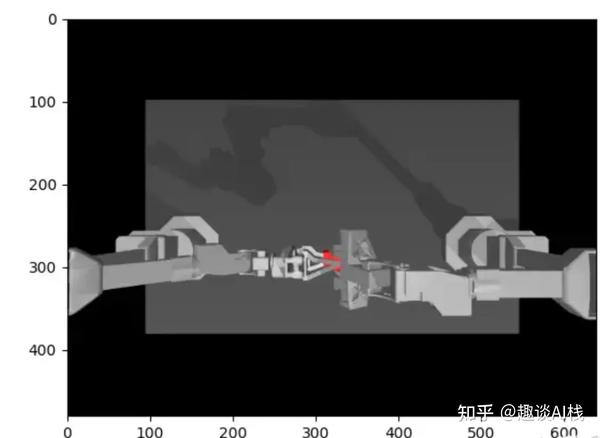
python3 aloha_scripts/visualize_episodes.py --dataset_dir <data save dir> --episode_idx 0如任务sim_transfer_cube_scripted(一个机械臂拾取随机放置的方块,并递给另一个机械臂):
4.2 模型训练: 先在imitate_episodes.py中完成wandb(训练可视化工具)的配置修改:wandb.init(project="mobile-aloha2", reinit=True, entity="vison20080808", name=expr_name)
python3 imitate_episodes.py --task_name sim_transfer_cube_scripted --ckpt_dir <ckpt dir> \
--policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 \
--batch_size 8 --dim_feedforward 3200 --num_steps 20000 --lr 1e-5 --seed 0 \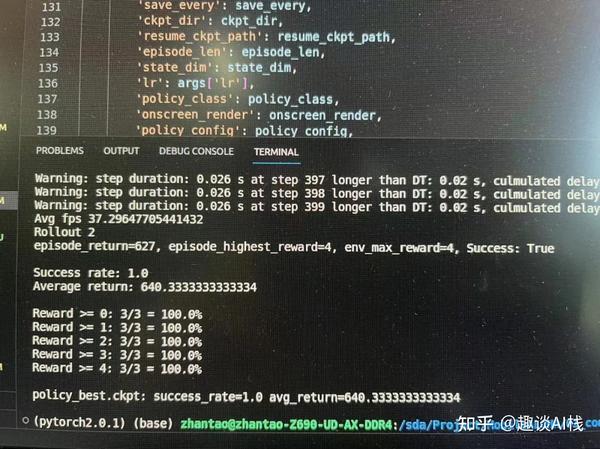
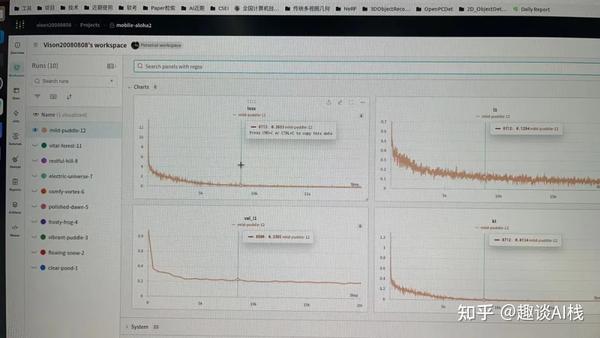
4.3 模型预测:
python3 imitate_episodes.py --eval --task_name sim_transfer_cube_scripted --ckpt_dir <ckpt dir> \
--policy_class ACT --kl_weight 10 --chunk_size 100 --hidden_dim 512 \
--batch_size 4 --dim_feedforward 3200 --num_steps 2000 --lr 1e-5 --seed 0 --onscreen_render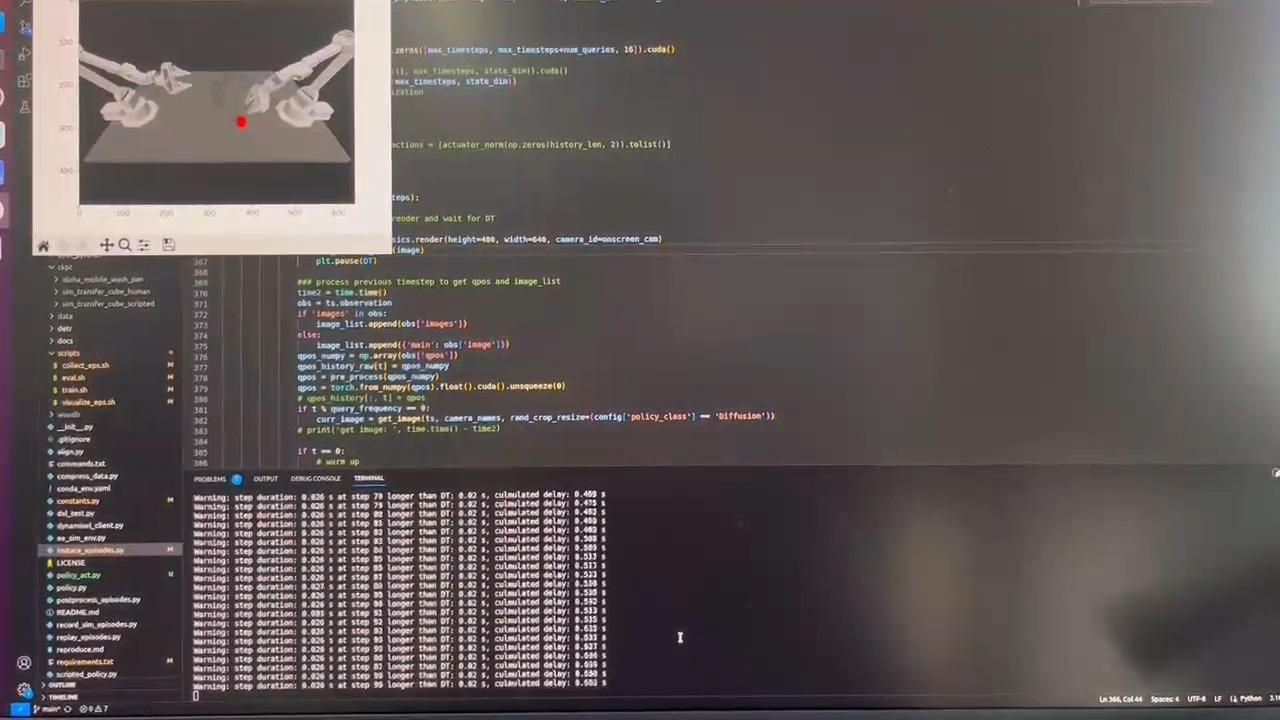
顺利完成任务~
三、附录及更多
- 原理介绍:https://blog.youkuaiyun.com/weixin_54338498/article/details/135476997
- ACT代码解读:https://blog.youkuaiyun.com/v_JULY_v/article/details/135566948
- 搭建过程参考:https://zhuanlan.zhihu.com/p/680100021
- 斯坦福团队后作(HumanPlus 人形机器人):https://humanoid-ai.github.io/

以上Enjoy~

















 1645
1645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









