










出发点:承接上一篇 【AI实践】个人免费数学老师系列之(一):系统概述,本篇介绍识别流程的第一步。
顺带总结科普一下当下大模型的核心架构Transformer、CV领域目标 检测算法等概念。
另将该自动切题方案代码开源。
0、提纲:
- 核心概念
- 项目开源
- 参考资料
1、核心概念
目标检测(Object detection)是计算机视觉(Computer Vision,CV)中的一类重要任务(Task),旨在识别图像中的物体并确定其位置(“what objects are located at where”)。
本项目任务为,识别&框定图像中每道题目所在的位置。检测依据为题号、版面分布等特征。
在深度学习时代,几乎所有现代目标检测器都共享相同的范式:用于特征提取的主干(Backbone)、用于整合不同层次特征的脖子(Neck)、用于定位与分类任务的检测头(Head)。
1.1 主干(Backbone)

Transformer模型首次在2017年Google的论文《Attention Is All You Need》中被提出。2018年其引申的变体BERT模型引领自然语言处理(NLP)的各大榜单。
当下最成功的大模型(LLM、例如OpenAI o1、Claude3.5、LLama3.2)都是Transformer Decoder架构。

Transformer的核心是自注意力机制(上图公式)。它能够更好地捕获全局的上下文信息,这也是Transformer有别于其它特征捕捉机制(如CNN、RNN)的关键所在。

以上图为例,我们想要翻译“The animal didn't cross the street because it was too tired”。 当Transformer在第5层编码器编码“it”时的状态,可视化之后显示it有一部分注意力集中在了“The animal”上,并且把这两个词的信息融合到了"it"中。
Transformer最初是为 NLP 任务设计的(出于自然语言天然的时序属性),但该架构已被成功扩展到CV和多模态领域。 本方案采用微软2021年开源的Swin-Transformer模型:

Swin-Transformer在层叠结构的每一层中对每个局部窗口应用下图的移动窗口(Shifted Window)计算技巧,扩充关注视野的同时,有效降低了计算成本。

1.2 脖子(Neck)

本方案应用目标检测领域中主流的(历史也很悠久、2017年由Facebook提出)特征金字塔网络(FPN、上图中的d),同时利用不同层次的特征,从而提升模型对各种大小目标的检测能力。
1.3 检测头(Head)

本方案应用2021年微软提出的《Dynamic Head: Unifying Object Detection Heads with Attentions》。
通过引入多种自注意力机制,统一了不同尺度、空间位置和任务的特征处理方式,从而提升了目标检测的表现。
1.4 提升策略(ATSS)
工业应用时,做目标检测任务,出于执行速度考虑,大多会选用单阶段检测器(one-stage methods),此时往往会面临存在大量负样本而正样本稀缺的情况,导致模型训练效果不佳。

2020年北邮提出的ATSS (Adaptive Training Sample Selection)策略,通过引入自适应样本选择机制,动态选择与真实目标更为接近的样本(根据均值和标准差设定IoU阈值,确保选择的正样本质量)进行训练,取得了显著的效果提升。
2、项目开源
- 代码仓库:https://github.com/vison20080808/auto-cut-question
- 数据情况:训练集4000+张、验证集1000+张【均为手机拍摄】
- 部分标注规范:


- 安装&训练&推理:可参看代码仓库中的README.md
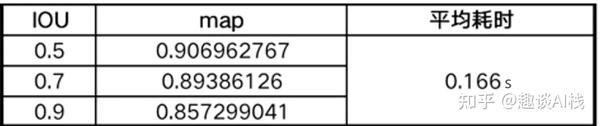
- 验证集指标:
- 运行效果截图:


3、参考资料
(1)图解 Transformer [译]:
https://baoyu.io/translations/llm/illustrated-transformer
(2)DynamicHead:
https://github.com/microsoft/DynamicHead/tree/master
(3)Swin-Transformer:
https://github.com/microsoft/Swin-Transformer
(4)Transformer动画讲解 - 注意力工作原理(Q、K、V):
https://mp.weixin.qq.com/s/IhyOJBbc9xrNAopIqPxXDg
(5)Visualizing Attention, a Transformer's Heart:
https://www.3blue1brown.com/lessons/attention
另附上该系列目录:
【AI实践】个人免费数学老师系列之(二):自动切题【目标检测】(本篇)
【AI实践】个人免费数学老师系列之(三):题目识别【OCR2.0】
【AI实践】个人免费数学老师系列之(四):题目解析【Qwen2.5-Math】
【AI实践】个人免费数学老师系列之(五):工程实践【代码开源】

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









