






11.计算天数
描述
编写程序,计算给定日期是当年的第几天。
日期结构体:struct Date{ int year,month,day;};
输入
三个整数分别代表年year,月month,日day, 1<=year<=10000, 1<=month<=12, 1<=day<=31
输出
输出在该年,这一天是第几天。(1月1日是第一天)

提示
注意判断闰年
代码:
1.switch-语句技术含量较低版
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <string.h>
struct Date
{
int year,month,day;
};
//封装函数-判断是否是闰年
bool isLeapYear(int year)
{
return ((year%400==0)||(year%4==0 && year%100!=0));
}
int main() {
struct Date date;
scanf("%d %d %d",&date.year,&date.month,&date.day);
int num=0;
//1 3 5 7 8 10 12 都是31
//4 6 9 11 都是30
switch(date.month)
{
case 1:num+=date.day;break;
case 2:num+=(date.day+31);break;//2-28
case 3:num+=(date.day+59);break;
case 4:num+=(date.day+90);break;
case 5:num+=(date.day+120);break;
case 6:num+=(date.day+151);break;
case 7:num+=(date.day+181);break;
case 8:num+=(date.day+212);break;
case 9:num+=(date.day+243);break;
case 10:num+=(date.day+273);break;
case 11:num+=(date.day+304);break;
case 12:num+=(date.day+334);break;
}
//判断是否是3月之后
if(date.month>=3)
{
//是-判断是否是闰年-是-总天数+1
if(isLeapYear(date.year))
{
num++;//2-29
}
}
printf("%d",num);
return 0;
}
2.存放在int数组中,使用for循环迭代
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <math.h>
#include <string.h>
struct Date
{
int year,month,day;
};
//封装函数-判断是否是闰年
bool isLeapYear(int year)
{
return ((year%400==0)||(year%4==0 && year%100!=0));
}
int main() {
struct Date date;
scanf("%d %d %d",&date.year,&date.month,&date.day);
//1 3 5 7 8 10 12 都是31
//4 6 9 11 都是30
int num=0;
int i;
int daysInmonth[11]={31,28,31,30,31,30,31,31,30,31,30};
for(i=0;i<date.month-1;i++)
{
num+=daysInmonth[i];//加了month之前月份的天数
}
num+=date.day;
//判断是否是3月之后
if(date.month>=3)
{
//是-判断是否是闰年-是-总天数+1
if(isLeapYear(date.year))
{
num++;//2-29
}
}
printf("%d",num);
return 0;
}
12.{A} + {B} (重要)
描述
给你两个集合,要求{A} + {B}.
注:同一个集合中不会有两个相同的元素.
输入
有多组测试数据
每组输入数据分为三行,第一行有两个数字n,m(分别代表第一个集合和第二个集合的元素个数);第二行有 n 个数字,代表集合A中的元素;第三行有 m 个数字,代表集合B中的元素。所有元素范围:[1,1000]
输出
针对每组数据输出一行数据,表示合并后的集合,要求从小到大输出,每个元素之间有一个空格隔开.

提示
最后一个数后面没空格
代码:
#include <stdio.h>
#include <stdlib.h>
//比较函数
int compare(const void *a,const void *b)
{
//返回两整数差值,决定排序顺序,a-b负数代表a要排在b前
return (*(int*)a-*(int*)b);
}
int main() {
int n,m;
while(scanf("%d %d",&n,&m)!=EOF)
{
//定义int类型指针/数组 动态分配内存给集合A B
int *A=(int*)malloc(n*sizeof(int));
int *B=(int*)malloc(m*sizeof(int));
int *result=(int*)malloc((n+m)*sizeof(int));
int i,j;
//读取集合A元素
for(i=0;i<n;i++)
{
scanf("%d",&A[i]);
}
//读取集合B元素
for(i=0;i<m;i++)
{
scanf("%d",&B[i]);
}
int result_size=0;
for(i=0;i<n;i++)
{
result[result_size++]=A[i];
//走完n次循环,最终result_size数值是n,且result[n]中无元素
}
// 遍历集合B的每个元素,如果不在结果数组中,则添加到结果数组中
for(i=0;i<m;i++)
{
int found=0;//标记变量,默认没找到
for(j=0;j<result_size;j++)
{
if(B[i]==result[j])//如果找到相同元素
{
found=1;
break;//跳出内层循环
}
}
//如果集合B中元素不在result数组中
if(!found)
{
result[result_size++]=B[i];
}
}
//qsort库函数排序
qsort(result,result_size,sizeof(int),compare);
//输出排序后的合并数组
for(i=0;i<result_size;i++)
{
printf("%d",result[i]);
if(i!=result_size-1)printf(" ");
}
printf("\n");//一组数据输出结束
//释放动态分配的内存
free(A);
free(B);
free(result);
}
return 0;
}
cpp代码:
利用set模板类的去重性即可
#include <iostream>
#include <set>
using namespace std;
int main() {
int n, m;
while (cin >> n >> m) {
set<int> s;
int num;
// 读取集合A
for (int i = 0; i < n; ++i) {
cin >> num;
s.insert(num);
}
// 读取集合B
for (int i = 0; i < m; ++i) {
cin >> num;
s.insert(num);
}
// 输出合并后的集合
//单独输出第一个元素
set<int>::iterator it = s.begin();
cout << *it;
it++;
//其余元素之前都有空格
for (; it != s.end(); ++it) {
cout << " " << *it;
}
cout << endl;
}
return 0;
}
13.闰年展示
描述
输入x,y(1000≤x<y≤3000) ,输出 [x,y] 区间中闰年个数,并在下一行输出区间内所有闰年年份数字,使用空格隔开。
输入
两个数字x,y
输出
第一行输出区间[x,y]内闰年的个数
第二行从小到大依次输出闰年年份,注意每个年份后面都有一个空格

代码:
#include <stdio.h>
#include <stdlib.h>
int isLeapYear(int year)
{
if((year%4==0&&year%100!=0)||year%400==0)
{
return 1;
}
return 0;
}
int main() {
int n,m;
scanf("%d %d",&n,&m);
int i,count=0;
int *LeapYear=(int*)malloc((m-n+1)*sizeof(int));//m也包含
for(i=n;i<=m;i++)
{
if(isLeapYear(i))
{
LeapYear[count++]=i;
}
}
printf("%d\n",count);
for(i=0;i<count;i++)
{
printf("%d",LeapYear[i]);
if(i!=count-1)printf(" ");
}
free(LeapYear);
return 0;
}
cpp代码:
注意:vector是动态数组,直接使用下标添加元素的话会导致内存泄漏,要使用push_back()添加元素,之后使用size()返回数组大小即可
#include <iostream>
#include <set>
#include <vector>
using namespace std;
bool flag(int year){
if((year%4==0&&year%100!=0)||(year%400)==0){
return 1;
}else{
return 0;
}
}
int main() {
int begin,end;
cin>>begin>>end;
vector<int> LeapYear;
for(int i=begin;i<=end;i++){
if(flag(i)){
//LeapYear是动态数组,直接使用下标访问可能会导致内存泄漏
//LeapYear[count++]=i;
LeapYear.push_back(i);
}
}
cout<<LeapYear.size()<<endl;
for(int i=0;i<LeapYear.size();i++){
cout<<LeapYear[i]<<" ";
}
return 0;
}
14.文字处理(很好的题)
描述
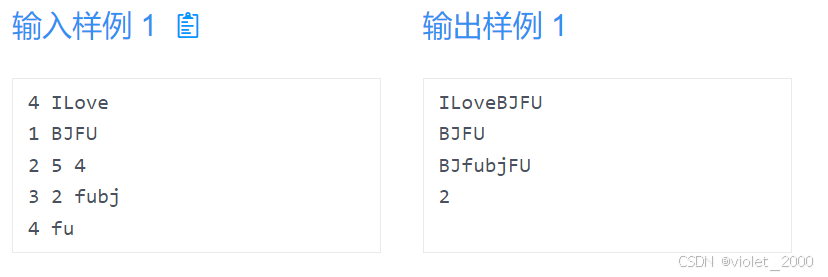
你需要开发一款文字处理软件。最开始时输入一个字符串(不超过 100 个字符)作为初始文档。可以认为文档开头是第 0 个字符。需要支持以下操作:
1 str:后接插入,在文档后面插入字符串 str,并输出文档的字符串。
2 a b:截取文档部分,只保留文档中从第 a 个字符起 b 个字符,并输出文档的字符串。
3 a str:插入片段,在文档中第 a 个字符前面插入字符串 str,并输出文档的字符串。
4 str:查找子串,查找字符串 str 在文档中最先的位置并输出;如果找不到输出 -1。
规定初始的文档和每次操作中的 str 都不含有空格或换行。最多会有 q(q≤100) 次操作。
输入
第一行有一个数字 n 和一个字符串 s ,n代表操作的次数,s 代表初始的文档内容
接下来 n 行分别是 n 次操作,每一行第一个数字代表操作的类型,按照题目描述对字符串进行处理。
输出
每次操作完,按照规定输出内容
代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_LEN 101//'\0'作为字符串结尾
//打印文档函数
void print_doc(const char *doc)
{
printf("%s\n",doc);
}
//文档末尾插入字符串,重点注意内存泄漏
void insert_end(char** doc,const char* str)
{//双重指针,使在函数内部修改指针指向在函数外部也保留
size_t new_len=strlen(*doc)+strlen(str)+1;//strlen计算字符串长度时不包括'\0'
char* temp=(char*)realloc(*doc,new_len);
//temp只是为了让*doc有足够内存而建立的一个副本
//处理内存分配失败的情况
if(temp==NULL)
{
exit(EXIT_FAILURE);
}
*doc=temp;
//此时*doc和temp指向了同一块内存,temp只是realloc返回的指针的副本
strcat(*doc,str);
//最后应调用free(*doc)
}
//截取文档内容
char* slice(char* doc,int a,int b)
{
char* result=(char*)malloc(b+1);//a最小是0
if(result==NULL)//内存分配失败
{
exit(EXIT_FAILURE);
}
strncpy(result,doc+a,b);
result[b]='\0';
return result;//直接返回新分配的字符串,之后要记得释放
}
//在文档指定位置插入字符串
//与尾端插入不同,temp里要存入数据,不是一个简单的副本,要用malloc
void insert_at(char** doc,int a,const char* str)
{
size_t new_len=strlen(*doc)+strlen(str)+1;
char* temp=(char*)malloc(new_len);
//新分配了内存总要检验是否分配成功,避免程序崩溃
if(temp==NULL)
{
exit(EXIT_FAILURE);
}
strncpy(temp,*doc,a);
strcpy(temp+a,str);
strcpy(temp+a+strlen(str),*doc+a);
free(*doc);//避免内存泄漏,如果此时不释放*doc指向的内存,后续就无法再访问它
//无法访问也无法释放,从而导致内存泄漏
//分配新内存以替换旧内存时,始终先释放旧内存,有助于防止内存泄漏
*doc=temp;
//此时不用释放temp,因为temp和*doc实际指向了同一块内存,最后释放*doc即可
}
//在文档中查找子串
int find_str(const char* doc,const char* str)
{
char* pos=strstr(doc,str);//没找到pos是NULL
return pos?pos-doc:-1;
}
int main() {
int n;
int i;
char s[MAX_LEN];
scanf("%d %s",&n,s);//字符串不用取址符
char* current_doc=(char*)malloc(strlen(s)+1);
if(current_doc==NULL)
{
exit(EXIT_FAILURE);
}
strcpy(current_doc,s);
for(i=0;i<n;i++)
{
int type,a,b;
char str[MAX_LEN];
scanf("%d",&type);
switch(type)
{
case 1://末尾插入
scanf("%s",str);
insert_end(¤t_doc,str);
print_doc(current_doc);
break;
case 2://截取文档
scanf("%d %d",&a,&b);
{
char* sliced_doc=slice(current_doc,a,b);
print_doc(sliced_doc);//打印截取后的文档
free(current_doc);//释放旧current_doc分配的内存
current_doc=sliced_doc;//将其更新为截取后的文档
}
break;
case 3://指定位置插入
scanf("%d %s",&a,str);
insert_at(¤t_doc,a,str);
print_doc(current_doc);
break;
case 4://查找字符串
scanf("%s",str);
printf("%d\n",find_str(current_doc,str));
break;//跳出for循环剩余部分,不会执行print_doc函数
}
}
free(current_doc);
return 0;
}
cpp代码:
使用cpp代码更为简洁,实际上就是考察了string类的几个函数,doc.size(); doc.substr(a,b); doc.insert(a,str); doc.find(str);
#include <iostream>
#include <string>
using namespace std;
int main() {
int q;//操作次数
string doc,str;
int a,b,operation;
int i;
cin>>q>>doc;
for(i=0;i<q;i++){
//输入操作名
cin>>operation;
if(operation==1){//在文档尾端插入
cin>>str;
doc+=str;
cout<<doc<<endl;
}else if(operation==2){//保留从a起b个字符
cin>>a>>b;
//检查文档长度,若不足则修改b为doc长度-a
if(a+b>doc.size()){
b=doc.size()-a;
}
//substr(a,b)从a开始截取b个字符
doc=doc.substr(a,b);
cout<<doc<<endl;
}else if(operation==3){//在第a个字符后插入str
cin>>a>>str;//cin遇到空格或换行会结束
//insert(a,str)在位置a前插入str
doc.insert(a,str);
cout<<doc<<endl;
}else if(operation==4){//查找子串
cin>>str;
//find函数找到doc中str的位置
//返回size_t类型的值,首次出现位置的索引
//没找到会返回std::string::npos;
size_t pos=doc.find(str);
if(pos!=string::npos){//npos静态成员常量,表示一个不可能的位置值
cout<<pos<<endl;
}else{
cout<<-1<<endl;
}
}
}
return 0;
}
15.随机数
描述
阿狗想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助阿狗完成“去重”与“排序”的工作
输入
输入有两行,第1行为1个正整数,表示所生成的随机数的个数N
第2行有N个用空格隔开的正整数,为所产生的随机数。
输出
输出也是两行,第1行为1个正整数M,表示不相同的随机数的个数。
第2行为M个用空格隔开的正整数,为从小到大排好序的不相同的随机数,每个数字后面都有一个空格

代码:
#include <stdio.h>
#include <stdlib.h>
#define MAX_N 100
int cmp(const void* a,const void* b)
{
return (*(int*)a-*(int*)b);
}
int main() {
int n;
int i,j;
int nums[MAX_N];
int unique_nums[MAX_N]={0};
int unique_count=0;
scanf("%d",&n);
for(i=0;i<n;i++)
{
scanf("%d",&nums[i]);
}
//去重
for(i=0;i<n;i++)
{
int num=nums[i];
int found=0;
for(j=0;j<unique_count;j++)
{
if(num==unique_nums[j])
{
found=1;
break;
}
}
if(!found)
{
unique_nums[unique_count++]=num;
}
}
//排序
qsort(unique_nums,unique_count,sizeof(int),cmp);
//输出
printf("%d\n",unique_count);
for(i=0;i<unique_count;i++)
{
printf("%d ",unique_nums[i]);
}
printf("\n");
return 0;
}
cpp代码:
cpp中直接使用set容器和vector容器,set标准类有去重和自动排序(默认升序)的功能,先放入set类,再将set中的元素逐步转存到vector容器中,用size函数输出元素个数,再逐项输出即可
#include <iostream>
#include <string>
#include <set>
#include <vector>
using namespace std;
int main() {
int n;
int i;
cin>>n;
//将元素都放进set容器中
//自动去重和排序
set<int> numbers;
for(i=0;i<n;i++){
int num;
cin>>num;
numbers.insert(num);
}
//建立动态数组vector
vector<int> sortedNumbers(numbers.begin(),numbers.end());
//输出元素个数
cout<<sortedNumbers.size()<<endl;
//逐项输出排序后的数字
/*
//逐项输出数组
for(i=0;i<sortedNumbers.size();i++){
cout<<sortedNumbers[i]<<" ";
}*/
//或使用范围for循环
for(int num:sortedNumbers){
cout<<num<<" ";
}
cout<<endl;
return 0;
}
16.判断素数(埃氏筛)
描述
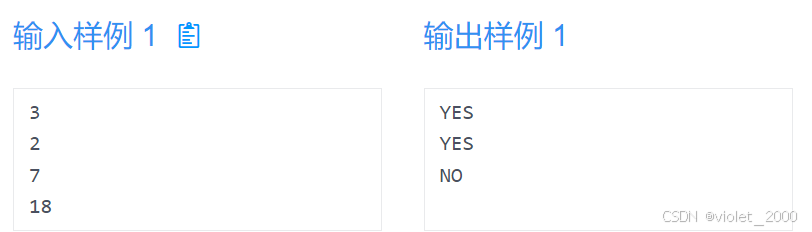
判断一个数是不是素数。
输入
输入一个整数T,代表测试组数。然后输出T个整数N。(T<=1000000,N<=1000000)
输出
如果整数是素数,输入YES,否则输入NO。
提示
数据量比较大,如果TLE,考虑用素数筛优化
代码:
#include <stdio.h>
#include <stdlib.h>//qsort
#include <stdbool.h>//bool
#include <string.h>//memset
#include <math.h>//sqrt
#define MAXN 1000000
//定义一个长度为n+1的布尔数组
bool is_prime[MAXN+1];
//埃氏筛
void sieve()//筛子
{
int i,j;
//将布尔数组都初始化为true,memset函数
memset(is_prime,true,sizeof(is_prime));
//特殊处理1和0
is_prime[0]=is_prime[1]=false;
//从2开始遍历到sqrt(MAXN)
for(i=2;i<=sqrt(MAXN);i++)
{
//如果当前i是素数
if(is_prime[i])
{
//从i*i开始将i的所有倍数都标记为合数flase
for(j=i*i;j<=MAXN;j+=i)
{
is_prime[j]=false;
}
}
}
}
int main() {
sieve();
int T;
scanf("%d",&T);
while(T--)
{
int N;
scanf("%d",&N);
if(is_prime[N])
{
printf("YES\n");
}else
{
printf("NO\n");
}
}
return 0;
}
cpp代码:
埃氏筛:先构建一个长度为MAXN+1(从0开始)的布尔数组,并将其全部初始化为true,然后将0和1初始化为false,从2开始循环到i*i<=MAXN,若i为素数,则从i*i开始将i的倍数全部变为false,完成预处理。
#include <iostream>
#include <vector>
using namespace std;
const int MAXN =1000001;
vector<bool> isPrime(MAXN,true);//初始化为真
//埃氏筛预处理
void sieve(){
//先处理0和1
isPrime[0]=isPrime[1]=false;
//从2开始检查
for(int i=2;i*i<=MAXN;i++){
if(isPrime[i]){
for(int j=i*i;j<=MAXN;j+=i){
isPrime[j]=false;
}
}
}
}
int main() {
//关闭同步
ios::sync_with_stdio(false);
//关闭cin与cout连接
cin.tie(NULL);
//预处理
sieve();
int T;
cin>>T;
while(T--){
int N;
cin>>N;
if(isPrime[N]){
cout<<"YES"<<endl;
}else{
cout<<"NO"<<endl;
}
}
return 0;
}
17.回文字符串
描述
输入一个字符串,输出该字符串是否回文。回文是指顺读和倒读都一样的字符串。
输入
输入一行字符串,长度小于 100100。
输出
如果字符串是回文,输出 yes;否则,输出 no。

代码:
#include <stdio.h>
#include <stdlib.h>//qsort
#include <stdbool.h>
#include <string.h>
#include <math.h>
bool flag(char* str)
{
int len=strlen(str);
int i;
for(i=0;i<len/2;i++)//数组最后是n-1,len/2>(n-1)/2
{
if(str[i]!=str[len-1-i])
{
return false;
}
}
return true;
}
int main() {
char str[100100];
scanf("%100099s",str);//最多读取100099个字符,最后一个'\0'
if(flag(str))
{
printf("yes\n");
}else
{
printf("no\n");
}
return 0;
}
cpp代码:
直接利用头文件#include <algorithm>中的reverse()即可,对比反转后的字符串是否==原来的字符
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string s;
cin>>s;
string reversed(s);//复制字符串
//反转字符串
reverse(reversed.begin(),reversed.end());
if(s==reversed){
cout<<"yes"<<endl;
}else{
cout<<"no"<<endl;
}
return 0;
}
18.巧妙的公式(斐波那契数列)
所谓斐波那契数列就是从第3项开始,第n项的值都等于前两项之和,第一项和第二项都是1
实际就是斐波那契数列前40项,将数据类型由int转换为double,再保留2位小数输出即可
描述

有上述公式可知,F1=1.00;F2=1.00;F3=2.00;F4=3.00;F5=5.00;......
输入
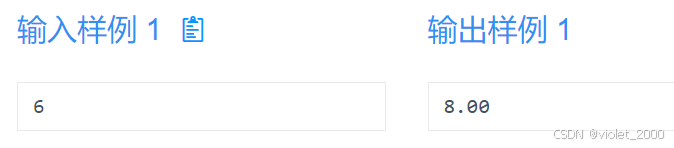
一行一个自然数 n,0≤n≤40。
输出
一个实数 Fn , 保留两位小数。
提示
发现规律
代码:
#include <stdio.h>
#include <stdlib.h>//qsort
#include <stdbool.h>
#include <string.h>
#include <math.h>
int main() {
double fiboArray[40];
double a=1,b=1;
double temp;
int i;
int num;
scanf("%d",&num);
for(i=0;i<40;i++)
{
fiboArray[i]=a;
temp=a+b;
a=b;
b=temp;
}
printf("%.2f\n",fiboArray[num-1]);
return 0;
}
cpp代码:
算法无新意,注意cout的输出格式,别漏掉fixed即可
#include <iostream>
#include <string>
#include <algorithm>
#include <iomanip>
using namespace std;
//1 1 2 3 5
//从第三项开始,每一项都等于前两项之和
//输出斐波那契数列第n项
int main() {
double fiboArray[40];
double a=1.00,b=1.00;
double temp;
int n;
cin>>n;
//构造数列前40项
for(int i=0;i<40;i++){
fiboArray[i]=a;
temp=a+b;
a=b;
b=temp;
}
//输出所需项n=i+1
//cout默认省略为0的小数部分,需要加上fixed
cout<<fixed<<setprecision(2)<<fiboArray[n-1];
return 0;
}
19.最大公约数/最小公倍数
两个数乘积=它们的最大公约数*最小公倍数
描述
求两数最大公约数/最小公倍数
输入
一行有两个正整数a,b,(0<a<10000,0<b<10000)
输出
输出a,b的最大公约数/最小公倍数


代码:
#include <stdio.h>
#include <stdlib.h>//qsort
#include <stdbool.h>
#include <string.h>
#include <math.h>
int gcd(int a,int b)//greatest common devisor
{
while(b!=0)
{
int temp=b;
b=a%b;
a=temp;
}
return a;
}
int main() {
int a,b;
scanf("%d %d",&a,&b);
int result=(int)a*b/gcd(a,b);//最小公倍数
int result=gcd(a,b);//最大公约数
printf("%d\n",result);
return 0;
}
cpp代码:
1.辗转相除法:a%b=c,先将b值存在temp中,令b=a%b,a=temp,若b=0,则说明b能被a整除,则最大公约数就为b
#include <iostream>
#include <string>
#include <algorithm>
#include <iomanip>
using namespace std;
//辗转相除法求a b最大公约数
//6%4=2 a=6,b=4,
//先把b的值存到temp,再令b=a%b,a=temp
int gcd(int a,int b){
if(a==0||b==0){
return 0;
}
while(b!=0){//若b为0,则此时的a就是greatest common devisor
int temp=b;
b=a%b;
a=temp;
}
return a;
}
int main() {
int a,b;
cin>>a>>b;
int result=(int)a*b/gcd(a,b);//最小公倍数
cout<<gcd(a,b)<<endl;//最大公因数
cout<<result<<endl;
return 0;
}
2.从较小数开始循环,当a,b均能整除i时,输出i
#include <iostream>
#include <iomanip>
#include <string>
#include <cmath>
#include <algorithm>//min
#include <bitset>//去除前缀0
using namespace std;
//遍历
void gcd(int a,int b){
for(int i=min(a,b);i>=1;i--){
if(a%i==0 && b%i==0){
cout<<i<<endl;
break;
}
}
}
int main() {
int a,b;
cin>>a>>b;
gcd(a,b);
return 0;
}
20.多少个数字?
关键是对比每一个数每位上的数字
描述
求出1~n之间有几个数字x?
输入
给定两个数n,x(n<=10^6,0<=x<=9)
求出1,2,3,...,n-1,n之间有多少个数字x
例如:数字1有1个1,数字10有1个1,数字117有两个1
数字2227有3个2
输出
一个数字表示答案

提示
输入样例:100 1
有1,10,11,12,13,14,15,16,17,18,19,21,31,41,51,61,71,81,91,100
共计20个数,其中11含有2个1,所以答案为21
代码:
#include <stdio.h>
#include <stdlib.h>//qsort
#include <stdbool.h>
#include <string.h>
#include <math.h>
int countFrequency(int number,int key)
{
int count=0;
while(number!=0)
{
if(number%10==key)
{
count++;
}
number/=10;
}
return count;
}
int main() {
int n,key;
scanf("%d %d",&n,&key);
int i;
int count=0;
//从1到n遍历,每次count加上此时i中含key的个数
for(i=1;i<=n;i++)
{
count+=countFrequency(i,key);
}
printf("%d\n",count);
return 0;
}

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









