




 本文介绍了学习曲线和验证曲线的概念,如何通过它们判断模型是欠拟合、过拟合还是最佳状态。通过实例展示了SVM模型在不同参数下的表现,并强调了在模型选择时结合验证曲线的重要性。
本文介绍了学习曲线和验证曲线的概念,如何通过它们判断模型是欠拟合、过拟合还是最佳状态。通过实例展示了SVM模型在不同参数下的表现,并强调了在模型选择时结合验证曲线的重要性。
Learning Curve
学习曲线是什么?
简单来说,就是用学习曲线(learning curve)来判断模型状态:过拟合还是欠拟合。
学习曲线是根据不同训练集大小,模型在训练集和验证集上的得分变化曲线。也就是以样本数为横坐标,训练和交叉验证集上的得分(如准确率)为纵坐标。learning curve可以帮助我们判断模型现在所处的状态:过拟合(overfiting / high variance) or 欠拟合(underfitting / high bias,模型欠拟合、过拟合、偏差和方差平衡 时对应的学习曲线如下图所示:
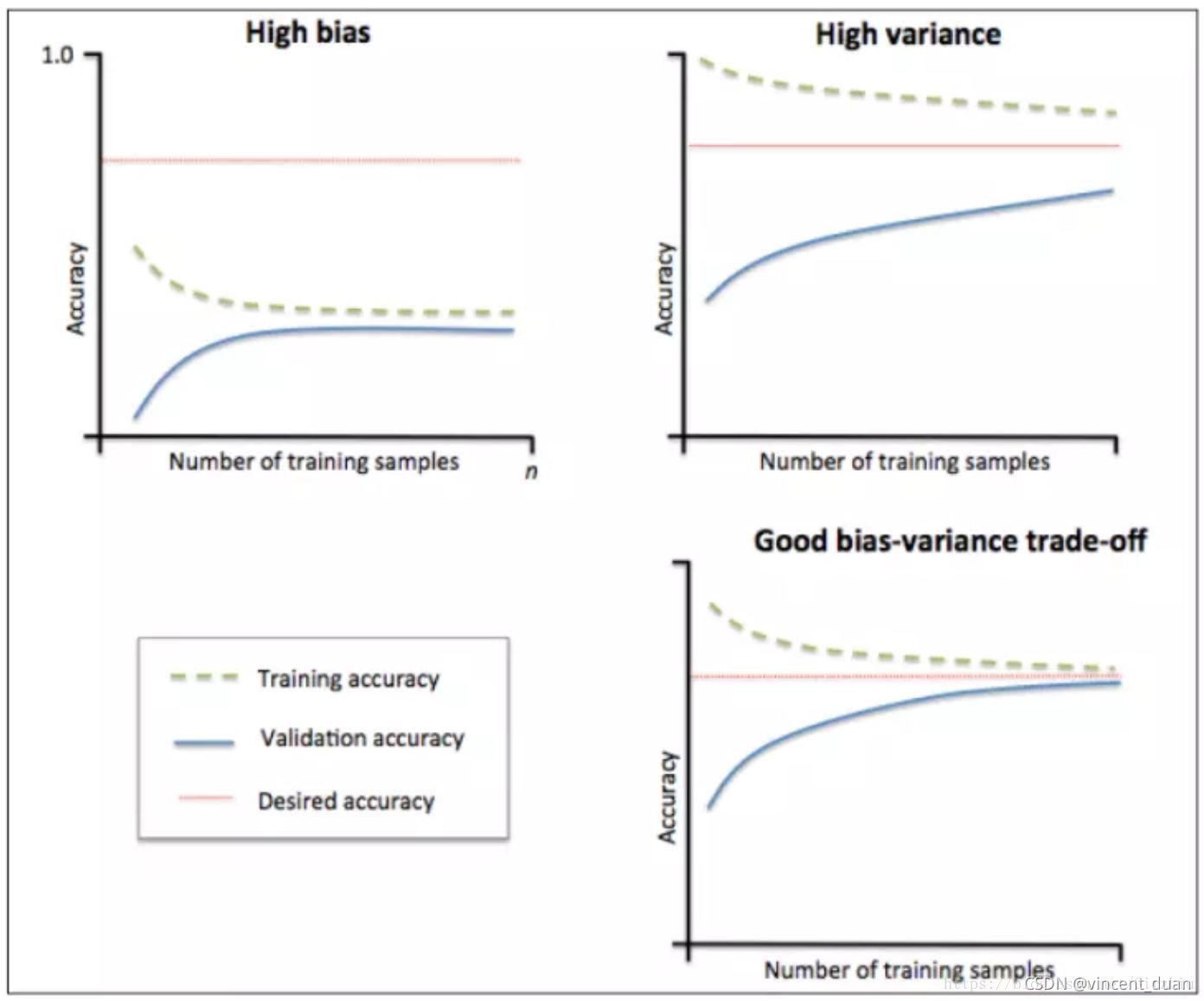
(1)左上角的图中训练集和验证集上的曲线能够收敛。在训练集合验证集上准确率相差不大,却都很差。这说明模拟对已知数据和未知都不能进行准确的预测,属于高偏差。这种情况模型很可能是欠拟合。可以针对欠拟合采取对应的措施。
欠拟合措施:
我们可以增加模型参数(特征),比如,构建更多的特征,减小正则项。
采用更复杂的模型
此时通过增加数据量是不起作用的。(为什么?)
(2)右上角的图中模型在训练集上和验证集上的准确率差距很大。说明模型能够很好的拟合已知数据,但是泛化能力很差,属于高方差。模拟很可能过拟合,要采取过拟合对应的措施。
过拟合措施:
我们可以增大训练集,降低模型复杂度,增大正则项,
或者通过特征选择减少特征数,即做一下feature selection,挑出较好的feature的subset来做training
(3)理想情况是找到偏差和方差都很小的情况,即收敛且误差较小。如右角的图。
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
print(X.shape) # (1797, 64)
train_sizes,train_loss, val_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1] # 在整个过程中的10%取一次,25%取一次,50%取一次,75%取一次,100%取一次
)
learning_curve函数中参数解释:
- SVC(gamma=0.001)表示我们所使用的的分类器是SVC
- X : 输入的feature,numpy类型
- y : 输入的target
- cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份),我们这里做了10份,
- train_sizes: 随着训练集的增大,选择在10%,25%,50%,75%,100%的训练集大小上进行采样loss
print(train_sizes) # [ 161 404 808 1212 1617]
print(train_loss)
print(val_loss)
train_loss_mean = -np.mean(train_loss, axis=1)
val_loss_mean = -np.mean(val_loss,axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-',color='r',label='Training')
plt.plot(train_sizes,val_loss_mean,'o-',color='g', label='Cross-validation')
plt.xlabel('Training examples')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
train_loss输出如下:
[[-0. -0.09937888 -0.09937888 -0.09937888 -0.09937888 -0.09937888
-0.09937888 -0.09937888 -0.09937888 -0.09937888]
[-0. -0.03960396 -0.03960396 -0.03960396 -0.03960396 -0.03960396
-0.03960396 -0.03960396 -0.03960396 -0.03960396]
[-0. -0.01980198 -0.01980198 -0.06435644 -0.01980198 -0.01980198
-0.01980198 -0.01980198 -0.01980198 -0.01980198]
[-0. -0.01650165 -0.01320132 -0.01320132 -0.01320132 -0.01320132
-0.01320132 -0.01320132 -0.01320132 -0.01320132]
[-0.02226345 -0.03215832 -0.00989487 -0.03215832 -0.03215832 -0.03215832
-0.03215832 -0.03215832 -0.03215832 -0.00989487]]
test_loss输出如下:
[[-1.26666667e+00 -1.43333333e+00 -3.96666667e+00 -9.73888889e+00
-6.95000000e+00 -5.24444444e+00 -3.02777778e+00 -5.25139665e+00
-3.48044693e+00 -4.85474860e+00]
[-1.81111111e+00 -1.13333333e+00 -1.35555556e+00 -3.06666667e+00
-2.08333333e+00 -2.85000000e+00 -8.38888889e-01 -1.94413408e+00
-5.41899441e-01 -1.35195531e+00]
[-1.71111111e+00 -3.61111111e-01 -5.11111111e-01 -9.61111111e-01
-6.16666667e-01 -5.88888889e-01 -1.22222222e-01 -9.16201117e-01
-7.76536313e-01 -1.14525140e+00]
[-1.22222222e+00 -3.61111111e-01 -4.44444444e-01 -7.00000000e-01
-5.55555556e-01 -2.66666667e-01 -8.88888889e-02 -1.11731844e-02
-9.21787709e-01 -8.43575419e-01]
[-9.33333333e-01 -0.00000000e+00 -2.66666667e-01 -2.83333333e-01
-2.77777778e-01 -3.61111111e-01 -8.88888889e-02 -5.58659218e-03
-9.21787709e-01 -4.18994413e-01]]
Validation curve
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
param_range = np.logspace(-6,-2.3,5) # 参数范围从-6到-2.3,之间 取5个点
train_loss, validation_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range , cv=10, scoring='neg_mean_squared_error'
) # 对于SVC()分类器中的gamma参数设置取值范围param_range
print(train_loss)
print(validation_loss)
train_loss_mean = -np.mean(train_loss, axis=1)
validation_loss_mean = -np.mean(validation_loss,axis=1)
plt.plot(param_range,train_loss_mean, 'o-',color='r',label='Training')
plt.plot(param_range,validation_loss_mean,'o-',color='g', label='Cross-validation')
plt.xlabel('gamma')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
输出结果如下:
[[-1.04347557e+01 -1.04329004e+01 -1.04329004e+01 -1.04242424e+01
-1.04199134e+01 -1.04199134e+01 -1.04199134e+01 -1.35568603e+01
-9.54017305e+00 -9.39431397e+00]
[-1.84415584e+00 -2.09338281e+00 -2.14038343e+00 -1.71552257e+00
-1.72232529e+00 -2.21150278e+00 -2.14409400e+00 -2.16687268e+00
-1.81582200e+00 -1.99381953e+00]
[-3.37043908e-01 -5.62152134e-01 -4.28571429e-01 -4.32282004e-01
-4.76190476e-01 -4.68769326e-01 -4.74335189e-01 -5.61804697e-01
-3.96168109e-01 -3.93695921e-01]
[-6.24613482e-02 -7.48299320e-02 -2.04081633e-02 -4.26716141e-02
-7.48299320e-02 -2.04081633e-02 -4.20531849e-02 -4.20271941e-02
-4.20271941e-02 -1.23609394e-02]
[-0.00000000e+00 -0.00000000e+00 -0.00000000e+00 -0.00000000e+00
-0.00000000e+00 -0.00000000e+00 -0.00000000e+00 -0.00000000e+00
-0.00000000e+00 -0.00000000e+00]]
[[-1.03666667e+01 -1.03833333e+01 -1.03833333e+01 -1.04611111e+01
-1.05000000e+01 -1.05000000e+01 -1.05000000e+01 -1.44357542e+01
-9.02234637e+00 -1.04078212e+01]
[-4.01111111e+00 -1.65555556e+00 -1.50555556e+00 -5.84444444e+00
-2.69444444e+00 -1.56666667e+00 -8.66666667e-01 -1.56424581e+00
-5.07821229e+00 -1.74301676e+00]
[-1.40000000e+00 -6.33333333e-01 -4.44444444e-01 -2.53888889e+00
-1.12777778e+00 -4.16666667e-01 -4.11111111e-01 -1.11731844e-02
-3.55307263e+00 -1.39106145e+00]
[-7.33333333e-01 -0.00000000e+00 -3.16666667e-01 -8.33333333e-01
-2.77777778e-01 -3.61111111e-01 -8.88888889e-02 -5.58659218e-03
-9.44134078e-01 -6.14525140e-01]
[-2.18333333e+00 -1.90555556e+00 -9.38888889e-01 -3.68333333e+00
-1.20555556e+00 -2.54444444e+00 -1.61111111e-01 -1.46927374e+00
-2.31843575e+00 -1.82122905e+00]]
print(train_loss.shape) # (5, 10)
print(validation_loss.shape) # (5, 10): 因为参数取了5个点,将训练集和验证集分为了10份cv=10,每一个参数对应10个loss
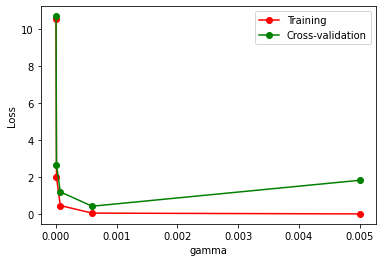
SVC()分类器在不同gamma参数下,它在训练集和交叉验证上的分数如下:当gamma=0时,他们的loss都很大,说明欠拟合;当gamma=0.006时,他们的loss都很低,效果不错;当gamma=0.005时,验证集上的loss很大,而训练集上的loss变小,说明发生了过拟合。因此我们会选择gamma=0.006时,在测试集上进行测试。
验证曲线(validation_curve)和学习曲线(sklearn.model_selection.learning_curve())的区别是,验证曲线的横轴为某个超参数,如一些树形集成学习算法中的max_depth、min_sample_leaf等等。
从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适,再到过拟合的过程,进而选择一个合适的位置,来提高模型的性能。
一般我们需要把一个数据集分成三部分:train、validation和test,我们使用train训练模型,并通过在 validation数据集上的表现不断修改超参数值(例如svm中的C值,gamma值等),当模型超参数在validation数据集上表现最优时,我们再使用全新的测试集test进行测试,以此来衡量模型的泛化能力。

















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









