




 本文介绍如何启动ThriftServer及Beeline客户端,详细解释通过不同端口配置实现多客户端共享数据的方法,并对比ThriftServer与Spark-shell/Spark-sql的区别。
本文介绍如何启动ThriftServer及Beeline客户端,详细解释通过不同端口配置实现多客户端共享数据的方法,并对比ThriftServer与Spark-shell/Spark-sql的区别。
启动thriftserver
使用命令启动:./start-thriftserver.sh --master local[2] --jars /home/iie4bu/software/mysql-connector-java-5.1.35.jar。
然后使用jps -m查看,可以看到SparkSubmit
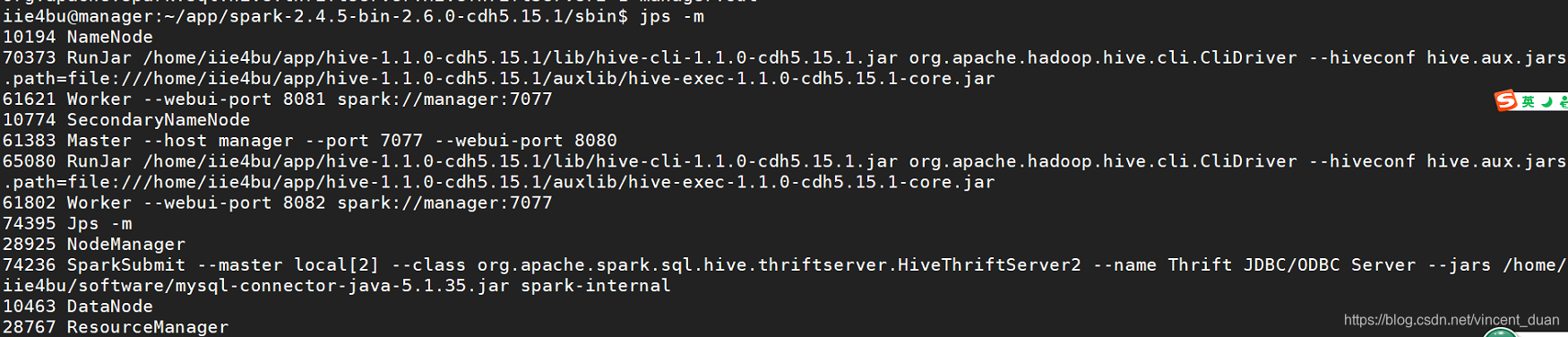
同样可以通过浏览器进行访问。实际上beeline访问端口则需要访问10000
启动客户端beeline
使用命令:bin/beeline -u jdbc:hive2://manager:10000 -n iie4bu

上面的图展示了正确连接的情况。
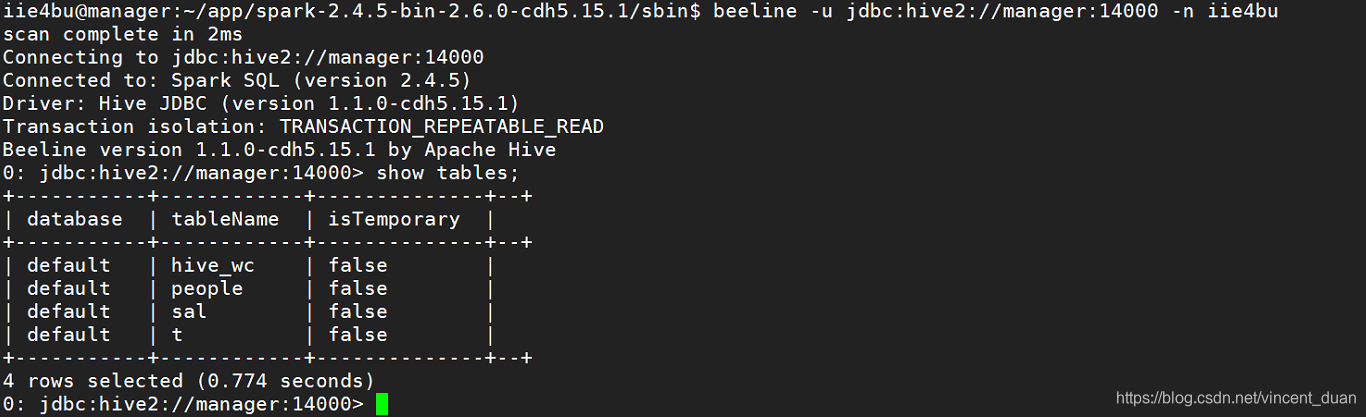
使用命令查看表:show tables;
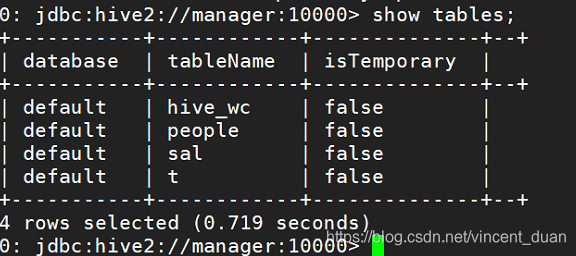
查询语句:select * from sal s join people p on s.transactionid=p.id;

可以在浏览器中查看到作业:
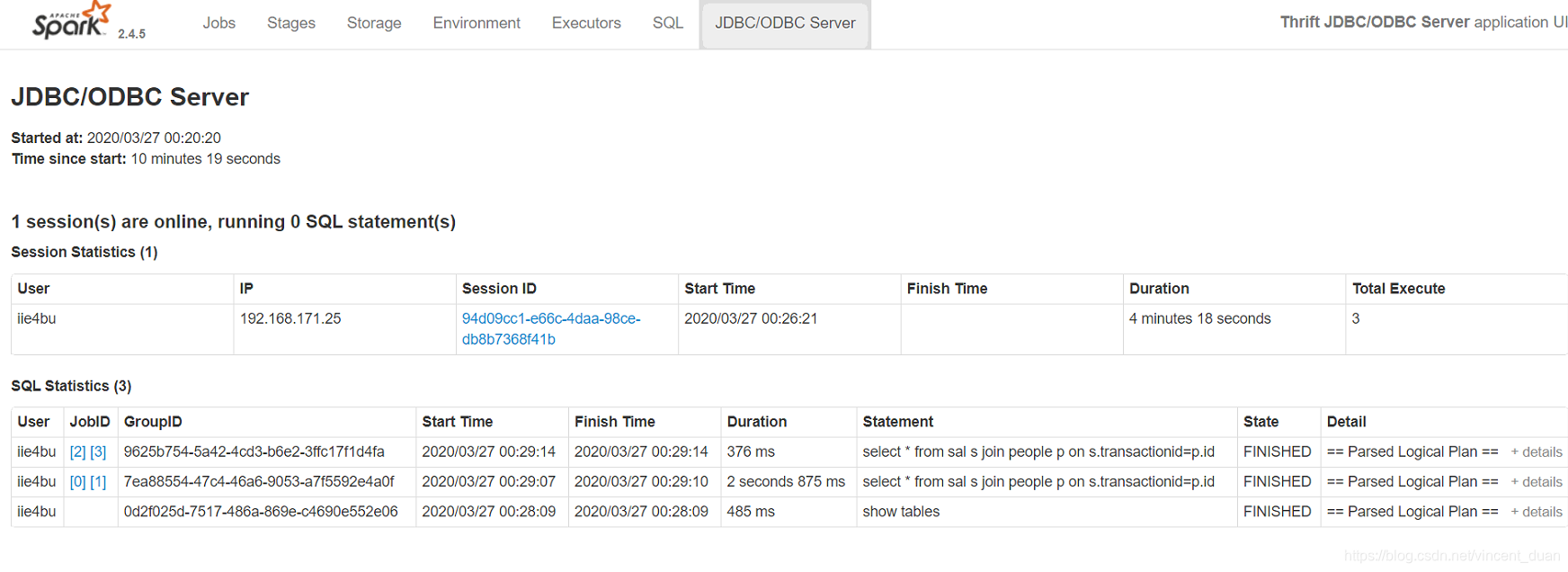
可以查看详细的执行计划。
当我们在启动一个beeline时,会出现两个session:
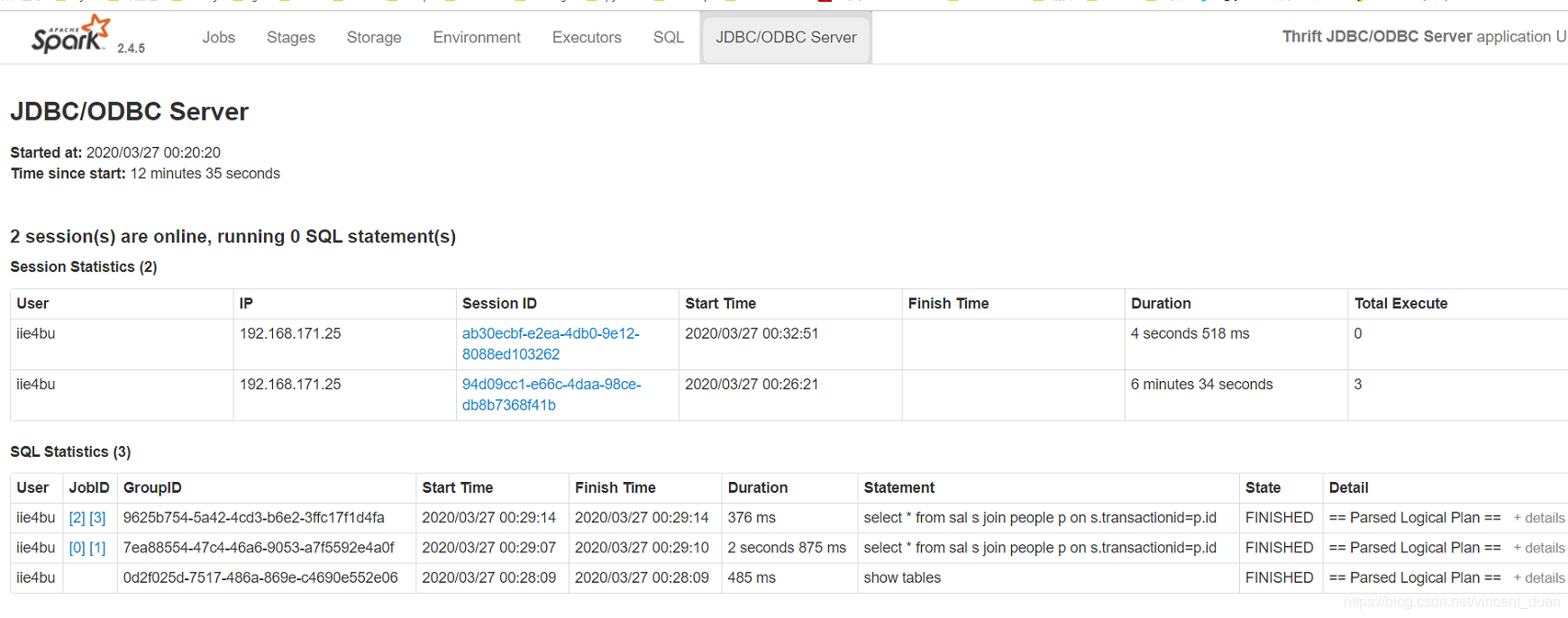
修改thriftserver启动时的默认端口
首先将上面的beeline和thriftserver停止。
然后启动thriftserver时,指定端口号:14000。
./start-thriftserver.sh --master local[2] --jars /home/iie4bu/software/mysql-connector-java-5.1.35.jar --hiveconf hive.server2.thrift.port=14000
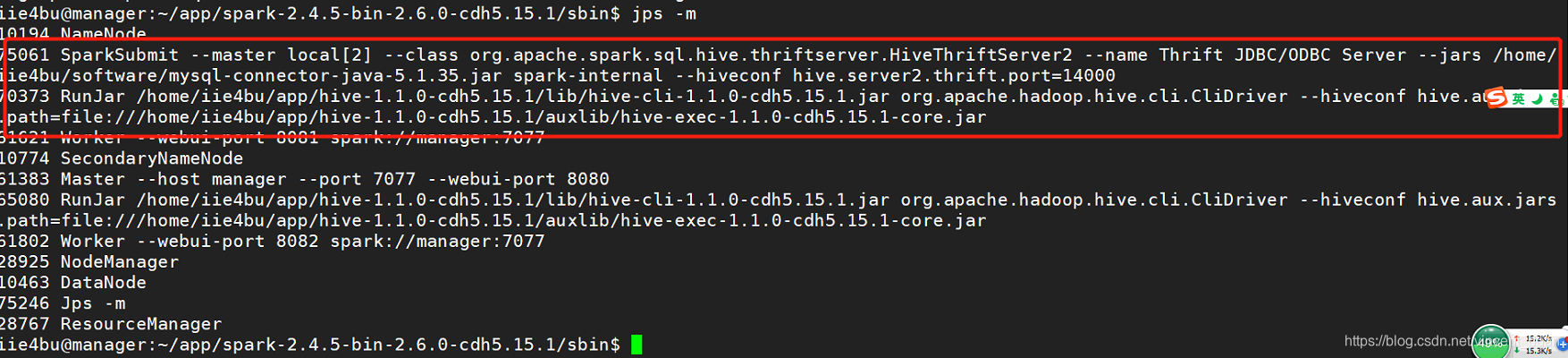
然后启动beeline客户端:
beeline -u jdbc:hive2://manager:14000 -n iie4bu,启动成功:
thriftserver与spark-shell/spark-sql区别
spark-shell和spark-sql启动时每次都需要重新申请资源,都是一个新的spark application。
thriftserver不管启动多少个客户端(beeline/jdbc方式),永远都是一个spark application。好处一:是只要在启动时申请一次就可以了,不需要在申请资源了。好处二:当一个客户端修改一个表之后,另一个客户端可以看到,解决了数据共享的问题,多个客户端可以共享数据。

















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









