




 本文对比了Spark SQL与Hive在数据处理上的性能差异,展示了Spark SQL在处理大规模数据集时的高效性。同时,深入解析了Spark SQL的执行计划,包括逻辑执行计划和物理执行计划的生成过程,以及如何通过解释命令查看这些计划。
本文对比了Spark SQL与Hive在数据处理上的性能差异,展示了Spark SQL在处理大规模数据集时的高效性。同时,深入解析了Spark SQL的执行计划,包括逻辑执行计划和物理执行计划的生成过程,以及如何通过解释命令查看这些计划。
使用命令开启一个spark-shell:
./spark-shell --master local[2] --jars /home/iie4bu/software/mysql-connector-java-5.1.35.jar
因为我们要操作hive,因此需要添加mysql的driver类。
查看表
使用命令spark.sql("show tables").show

查看表数据
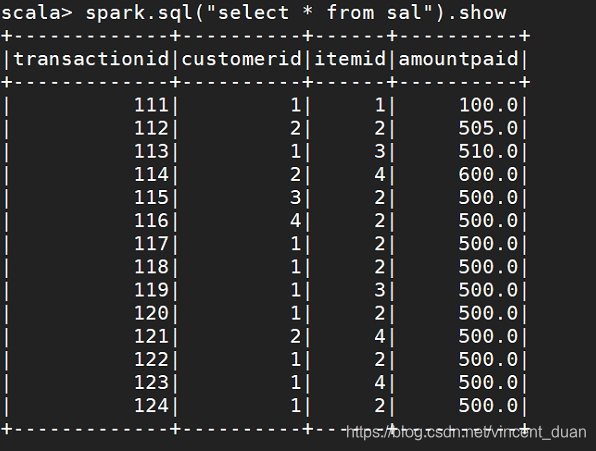
比较spark-shell和hive的性能
在hive中执行一条join操作:
hive> select * from sal s join people p on s.transactionid=p.id;
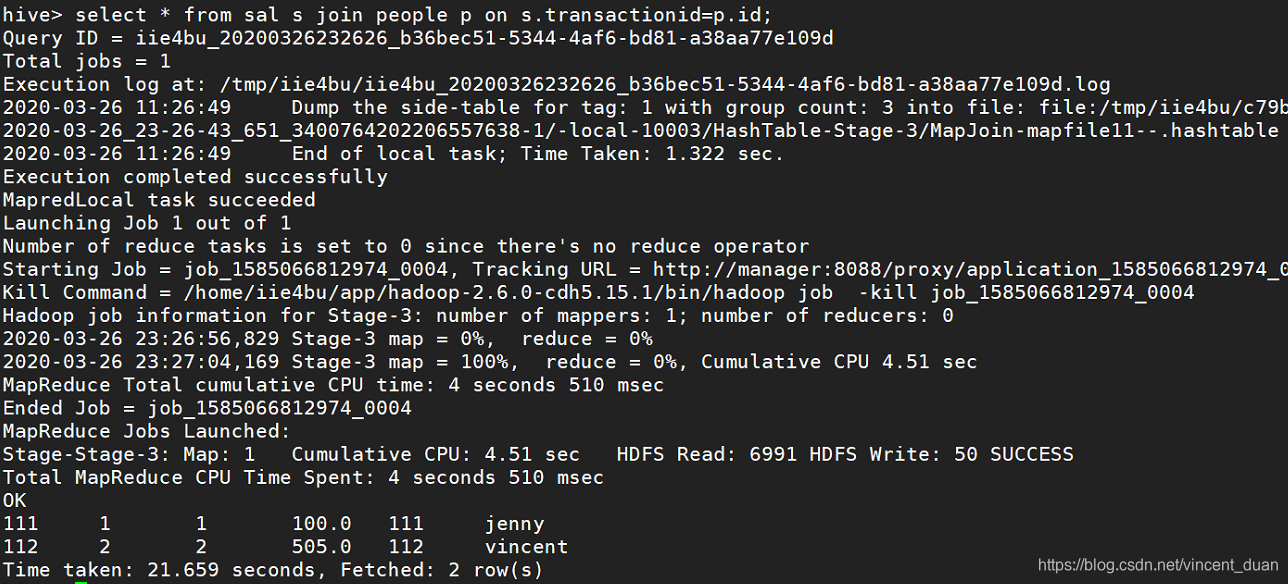
可以看到使用Hive操作时,花费20s。
在Spark-shell中执行相同个操作:
scala> spark.sql("select * from sal s join people p on s.transactionid=p.id").show

在使用spark时,几乎是瞬间出来。高下立判。
升级spark-shell
上面我们可以通过spark-shell来使用sql,当然我们可以使用另一个命令,更加方便的使用sql。那就是spark-sql.
使用命令:./spark-sql --master local[2] --jars /home/iie4bu/software/mysql-connector-java-5.1.35.jar --driver-class-path /home/iie4bu/software/mysql-connector-java-5.1.35.jar
当我们执行:spark-sql> select * from sal;
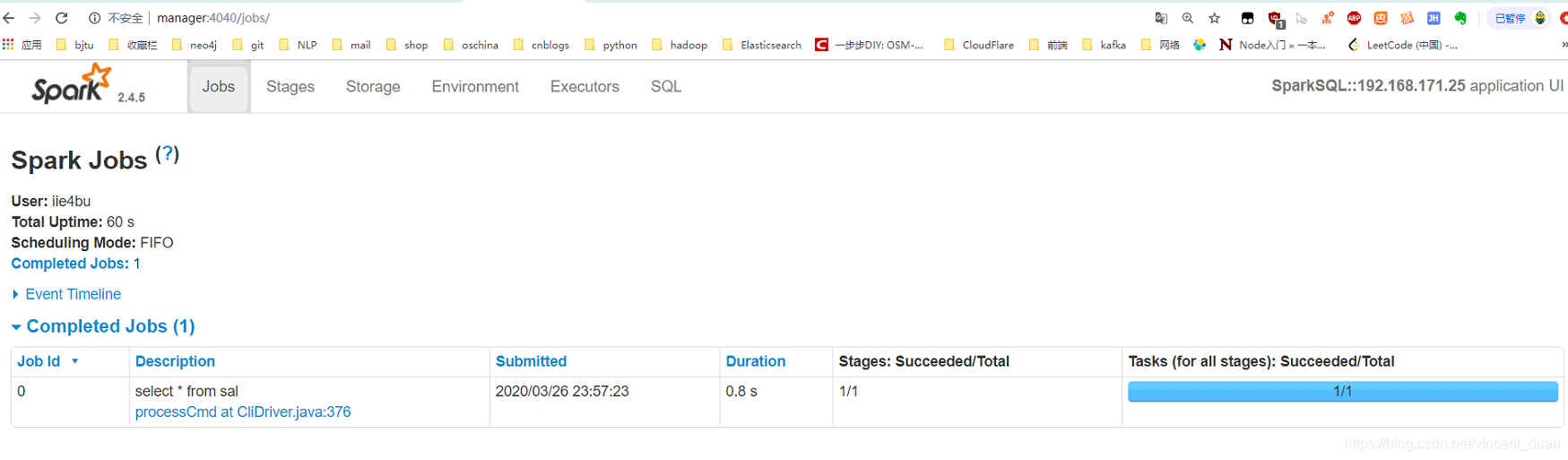
在页面中也可以看到相应的执行计划。
使用spark-sql创建表
使用命令spark-sql> create table t (key string, value string);
然后查看这张表:
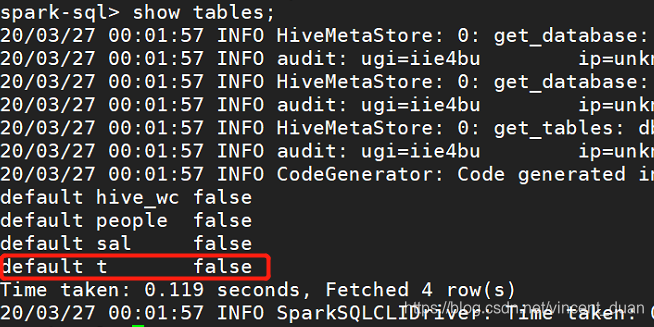
可以看到刚创建的t表。
spark-sql执行计划
我们使用上面创建的t表,运行执行计划:
spark-sql> explain select a.key*(2+3), b.value from t a join t b on a.key = b.key and a.key > 3;
可以看到物理执行计划:
spark-sql> explain select a.key*(2+3), b.value from t a join t b on a.key = b.key and a.key > 3;
20/03/27 00:04:55 INFO HiveMetaStore: 0: get_table : db=default tbl=t
20/03/27 00:04:55 INFO audit: ugi=iie4bu ip=unknown-ip-addr cmd=get_table : db=default tbl=t
20/03/27 00:04:55 INFO HiveMetaStore: 0: get_table : db=default tbl=t
20/03/27 00:04:55 INFO audit: ugi=iie4bu ip=unknown-ip-addr cmd=get_table : db=default tbl=t
20/03/27 00:04:55 INFO CodeGenerator: Code generated in 16.512742 ms
== Physical Plan ==
*(5) Project [(cast(key#28 as double) * 5.0) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#32, value#31]
+- *(5) SortMergeJoin [key#28], [key#30], Inner
:- *(2) Sort [key#28 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#28, 200)
: +- *(1) Filter (isnotnull(key#28) && (cast(key#28 as int) > 3))
: +- Scan hive default.t [key#28], HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#28, value#29]
+- *(4) Sort [key#30 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(key#30, 200)
+- *(3) Filter ((cast(key#30 as int) > 3) && isnotnull(key#30))
+- Scan hive default.t [key#30, value#31], HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#30, value#31]
Time taken: 0.362 seconds, Fetched 1 row(s)
20/03/27 00:04:55 INFO SparkSQLCLIDriver: Time taken: 0.362 seconds, Fetched 1 row(s)
如果要查看逻辑执行计划,添加extended。
spark-sql> explain extended select a.key*(2+3), b.value from t a join t b on a.key = b.key and a.key > 3;
运行结果如下:
spark-sql> explain extended select a.key*(2+3), b.value from t a join t b on a.key = b.key and a.key > 3;
20/03/27 00:07:10 INFO HiveMetaStore: 0: get_table : db=default tbl=t
20/03/27 00:07:10 INFO audit: ugi=iie4bu ip=unknown-ip-addr cmd=get_table : db=default tbl=t
20/03/27 00:07:10 INFO HiveMetaStore: 0: get_table : db=default tbl=t
20/03/27 00:07:10 INFO audit: ugi=iie4bu ip=unknown-ip-addr cmd=get_table : db=default tbl=t
== Parsed Logical Plan ==
'Project [unresolvedalias(('a.key * (2 + 3)), None), 'b.value]
+- 'Join Inner, (('a.key = 'b.key) && ('a.key > 3))
:- 'SubqueryAlias `a`
: +- 'UnresolvedRelation `t`
+- 'SubqueryAlias `b`
+- 'UnresolvedRelation `t`
== Analyzed Logical Plan ==
(CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE)): double, value: string
Project [(cast(key#35 as double) * cast((2 + 3) as double)) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#39, value#38]
+- Join Inner, ((key#35 = key#37) && (cast(key#35 as int) > 3))
:- SubqueryAlias `a`
: +- SubqueryAlias `default`.`t`
: +- HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#35, value#36]
+- SubqueryAlias `b`
+- SubqueryAlias `default`.`t`
+- HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
== Optimized Logical Plan ==
Project [(cast(key#35 as double) * 5.0) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#39, value#38]
+- Join Inner, (key#35 = key#37)
:- Project [key#35]
: +- Filter (isnotnull(key#35) && (cast(key#35 as int) > 3))
: +- HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#35, value#36]
+- Filter ((cast(key#37 as int) > 3) && isnotnull(key#37))
+- HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
== Physical Plan ==
*(5) Project [(cast(key#35 as double) * 5.0) AS (CAST(key AS DOUBLE) * CAST((2 + 3) AS DOUBLE))#39, value#38]
+- *(5) SortMergeJoin [key#35], [key#37], Inner
:- *(2) Sort [key#35 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(key#35, 200)
: +- *(1) Filter (isnotnull(key#35) && (cast(key#35 as int) > 3))
: +- Scan hive default.t [key#35], HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#35, value#36]
+- *(4) Sort [key#37 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(key#37, 200)
+- *(3) Filter ((cast(key#37 as int) > 3) && isnotnull(key#37))
+- Scan hive default.t [key#37, value#38], HiveTableRelation `default`.`t`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [key#37, value#38]
Time taken: 0.19 seconds, Fetched 1 row(s)
20/03/27 00:07:10 INFO SparkSQLCLIDriver: Time taken: 0.19 seconds, Fetched 1 row(s)
可以看到,第一步先使用抽象语法树解析成unresolved逻辑执行计划。第二步基于Metastore生成逻辑执行计划,然后优化逻辑执行计划,最后生成物理执行计划。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









