



深度学习在自动驾驶汽车中的应用:机遇与挑战扩展摘要
1 引言
近年来,多个自动驾驶汽车试点项目[2, 4, 6, 15]得以展示。这些试点项目的共同特点是,部分驾驶任务(如环境感知、路径规划甚至方向盘控制)由基于深度学习的方法来完成。随着深度学习驱动的自动驾驶原型成功演示,汽车行业的工作重点正逐渐从研发和展示原型车辆转向量产。如今,主要挑战在于如何以符合安全规范的方式将神经网络应用于量产汽车中。
2011年,国际标准化组织(ISO)提出了一项标准ISO 26262[10],该标准规定了功能道路车辆的功能安全。它涵盖了汽车制造整个生命周期的需求和建议,从概念阶段到运行与服务。ISO 26262 的主要目的是帮助汽车行业以更系统化的方式应对功能安全问题。然而,由于 ISO 26262 的第一个版本发布于人工智能兴起之前,因此在制定时并未考虑深度学习技术。这最终导致如今汽车制造商和供应商在致力于将深度学习应用于自动驾驶汽车时面临一项重大挑战。
在本文中,我们介绍了在开发用于自动驾驶汽车的深度学习解决方案过程中遇到的安全相关问题。我们指出了三个具体问题,并从原始设备制造商(OEM)的角度分享了如何应对这些问题的想法。我们的目标是基于此与行业同行展开讨论。
本文旨在与我们的合作伙伴共同为深度学习方法制定一个通用的功能安全概念。我们预计该通用解决方案将对未来ISO 26262标准产生影响。
本文的其余部分结构如下。第2节介绍了有关深度学习和功能安全的更多背景信息。第3节提出了我们在开发深度神经网络过程中遇到的三个具体的安全相关问题,包括训练集完整性、网络实现和迁移学习。第4节对本文进行了总结。
2 背景
通常,自动驾驶汽车的深度学习方法开发包含三大主要组成部分:数据准备、模型生成和模型部署。数据准备侧重于为训练和测试神经网络准备数据,涵盖数据记录、真实值标注、大数据存储等内容。模型生成包括开发网络架构、训练网络以及评估训练模型。当模型输出与其对应的真实值标注(即期望输出)之间的差异低于某个阈值时,该模型被视为“已训练”。通常,在部署阶段,训练好的模型会针对特定目标硬件进行剪枝和优化,并在测试场地或公共道路上进行实地测试。
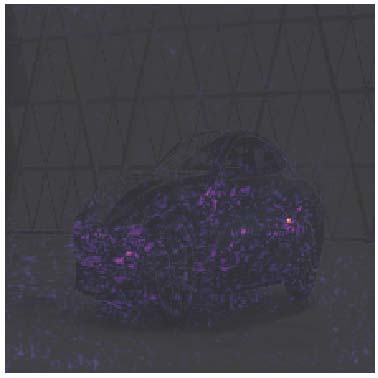
正如Salay等人在[12]中指出的,深度学习开发的整个流程可能通过其不透明性、概率误差率、基于训练的特性以及不稳定性,影响ISO 26262的安全评估。首先,不透明性指的是深度神经网络所学习到的知识很难被人类解释(图1)。如何使深度学习更具透明性仍然是一个正在进行的研究课题[8]。其次,误差率和基于训练的特性是两个在为基于深度学习的自动驾驶系统开发安全概念时必须考虑的神经网络特征。即使训练数据集被100%学习,也无法保证系统在现实世界中可以无错误地运行。已有出版物更详细地讨论了这些问题,例如[14]。
最后但同样重要的是,不稳定性指的是相同的训练过程由于权重的随机初始化而产生不同的训练结果。这是由于代价函数具有极高的维度和复杂性,其中包含大量局部最优。也有研究[5, 9, 11]专门针对机器学习的功能安全问题展开探讨,但距离达成通用的工业解决方案还很遥远,更不用说对ISO 26262产生影响了。
 输入神经网络的输入图像。图像来源:BMW Group .
输入神经网络的输入图像。图像来源:BMW Group .
 VGG16[13] 的卷积层的层激活。一些滤波器对图像中的边缘作出响应,另一些则对车辆部件(如车轮或后视镜)作出响应。通过编程无法预先确定哪种滤波器会被哪种特征激活。建议彩色查看。
VGG16[13] 的卷积层的层激活。一些滤波器对图像中的边缘作出响应,另一些则对车辆部件(如车轮或后视镜)作出响应。通过编程无法预先确定哪种滤波器会被哪种特征激活。建议彩色查看。
3 挑战
我们目前正在研究自动驾驶汽车开发过程中深度学习方法的功能安全概念。在此,我们提出三个尚未解决的具体问题,包括数据集完整性、神经网络实现和迁移学习。通过提出这些问题并发起讨论,我们希望与行业同行共同探讨,携手为汽车行业寻求统一的解决方案。
3.1 数据集完整性
如今,监督学习仍是环境感知任务的主要方法。监督模型通常只能完成其被训练过的内容。换句话说,如果一个训练数据集(实际上是需求的集合)仅包含汽车,那么基于该数据集训练的深度神经网络将无法识别行人。由于真实世界场景中交通场景的多样性近乎无限,因此无论数据集规模多大,都不可能通过单个数据集确保对真实世界场景的100%覆盖。因此,问题在于如何验证数据集是“完整”的,从而使得训练好的模型能够达到其最大可能的泛化能力。
评判标准当然既不是数据集的大小,也不是数据采集车队所行驶的里程。例如,在加利福尼亚的5号州际公路上录制八小时显然无助于提升深度神经网络在城市区域中的检测性能。
事实上,大多数录制的数据只是“正常”的交通场景,对于已经预训练过的模型而言,在微调过程中对权重更新的贡献非常有限。真正重要但难以获取的是数据集中的异常情况,例如交通事故、损坏的基础设施等。需要多少异常情况才足够?如何验证网络确实学会了这些异常情况?如何在训练过程中平衡正常场景与异常情况?这些问题对我们来说仍然悬而未决。
使用合成数据和仿真是解决数据集完整性问题的可能方法之一。那些对训练至关重要但在现实世界录制过程中很少发生的场景可以通过合成数据来弥补。这些场景包括但不限于危险天气条件(例如雾、大雪)、交通规则违规(例如逆行、闯红灯)、动物危险(例如鹿)等。目前已有正在进行的项目[1]专注于为自动驾驶生成合成训练集。
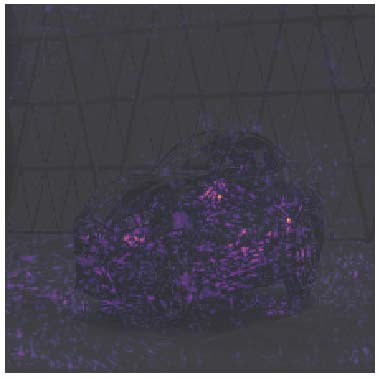
 跑车:43.2% (b) 旅行车:14.5% (c) 赛车:13.4%
跑车:43.2% (b) 旅行车:14.5% (c) 赛车:13.4%
图2:通过Picasso[7]可视化显著性图。神经网络将图1中的输入图像最可能分类为跑车,其次是旅行车和赛车。网络做出决策所依据的最显著区域已被高亮显示。建议彩色查看。
3.2 神经网络实现
传统上,ISO 26262 的功能安全要求被分解到传统基于规则的算法和软件的代码层面。必须明确识别出某个具体的功能安全要求是由特定代码实现的。
在评估深度学习方法的实现时,这几乎难以实现,因为在代码中构建神经网络不过是将若干层组合在一起,如下述伪代码示例所示。
def build_net_pseudo():
net = None
net += 卷积(inputs, kernel_size, strides, ...)
net += max_pool(inputs, kernel_size, strides, ...)
net += ...
net += fully_connected(inputs, number_outputs, ...)
return net
构建网络本身通常对从安全目标(例如“应避免与车辆碰撞”或“应避免与行人碰撞”)导出的要求几乎没有影响。大多数评估安全风险所需的信息存在于训练好的模型中,而非代码中。
然而,正如第2节中已经提到的,模型的权重以及输入层和输出层之间各层的输出无法被人类解释。深度神经网络的这种“黑箱”特性使得几乎无法验证其是否按照预期方式工作。这是深度学习迈向量产汽车道路上必须克服的巨大障碍。
 旧金山市中心的四向停车。图像来源:谷歌街景。
旧金山市中心的四向停车。图像来源:谷歌街景。
 Keep Clear香港的道路标记。图像来源:谷歌街景。
Keep Clear香港的道路标记。图像来源:谷歌街景。
图3:美国和东亚的典型交通场景。
卷积神经网络的可视化理解[16]可能是弥合上述差距的第一步。最近,一个名为Picasso[7]的开源框架被发布,该框架有助于监控和理解神经网络的学习过程。它不仅支持可视化每一层的特征图,还支持评估部分遮挡情况,即当图像的部分区域被遮挡时分类结果如何变化,并可计算显著性图(图2),即哪些输入区域对分类最为重要。开发者还可以根据自己的使用场景实现自定义的可视化工具。
另一种有助于解释神经网络行为的方法是使用部分规范。例如,假设一项需求规定行人的高度必须低于2.7m,则可利用该高度约束来验证网络输出的合理性,并过滤掉误报。这类基于目标物理特性的约束可在训练过程中用于监控和影响训练好的模型的行为。
3.3 迁移学习
迁移学习指的是在一个任务上训练神经网络,并将部分预训练权重用于另一个相关任务。例如,我们可以训练一个神经网络来检测汽车,然后重新训练它以识别卡车,甚至可能是火车。
事实上,当今大多数深度学习论文中的模型只是基于一个知名的预训练模型[3]进行微调,而不是从头开始训练。
迁移学习的思想可用于减少自动驾驶汽车所需的训练数据量。由于不同的本地政治限制,数据采集车队无法在全球范围内运行。为了仍然能够拥有一个可在不同国家运行的深度神经网络,我们可以在世界某一区域收集数据,并将知识迁移到其他区域,例如从欧洲到亚洲或美洲(图3)。这里的问题是,微调时还需要多少额外数据?我们是否只需要一个小数据集并对网络最后几层进行重新训练,还是需要大量额外数据并对整个网络进行重新训练?在已有已验证的预训练模型的情况下,应如何验证微调后的网络?这些都是我们目前正在分析的一些正在进行的研究课题。我们的主要重点是在深入了解训练好的深度神经网络行为之后,学习领域不变的表示。
4 结论与展望
本文中,我们探讨了在开发自动驾驶汽车深度学习方法时与功能安全相关的三个具体挑战。这些挑战包括验证训练和测试数据集的完整性、在软件开发过程中将安全需求追溯到源代码级别,以及为世界不同地区引入迁移学习。我们期望本文能激发行业同行对深度学习开发中功能安全的兴趣。在不久的将来,我们期待与合作伙伴共同努力,为汽车行业开发出一种通用的解决方案。

















 1799
1799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









