




项目链接: microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system (github.com)
官网简介: GraphRAG: Unlocking LLM discovery on narrative private data - Microsoft Research
原文地址: 微软开源的GraphRAG爆火,Github Star量破万,生成式AI进入知识图谱时代? (qq.com)
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
LLM 很强大,但也存在一些明显缺点,比如幻觉问题、可解释性差、抓不住问题重点、隐私和安全问题等。检索增强式生成(RAG)可大幅提升 LLM 的生成质量和结果有用性。
本月初,微软发布最强 RAG 知识库开源方案 GraphRAG,项目上线即爆火,现在星标量已经达到 10.5 k。
有人表示,它比普通的 RAG 更强大:
GraphRAG 使用 LLM 生成知识图谱,在对复杂信息进行文档分析时可显著提高问答性能,尤其是在处理私有数据时。
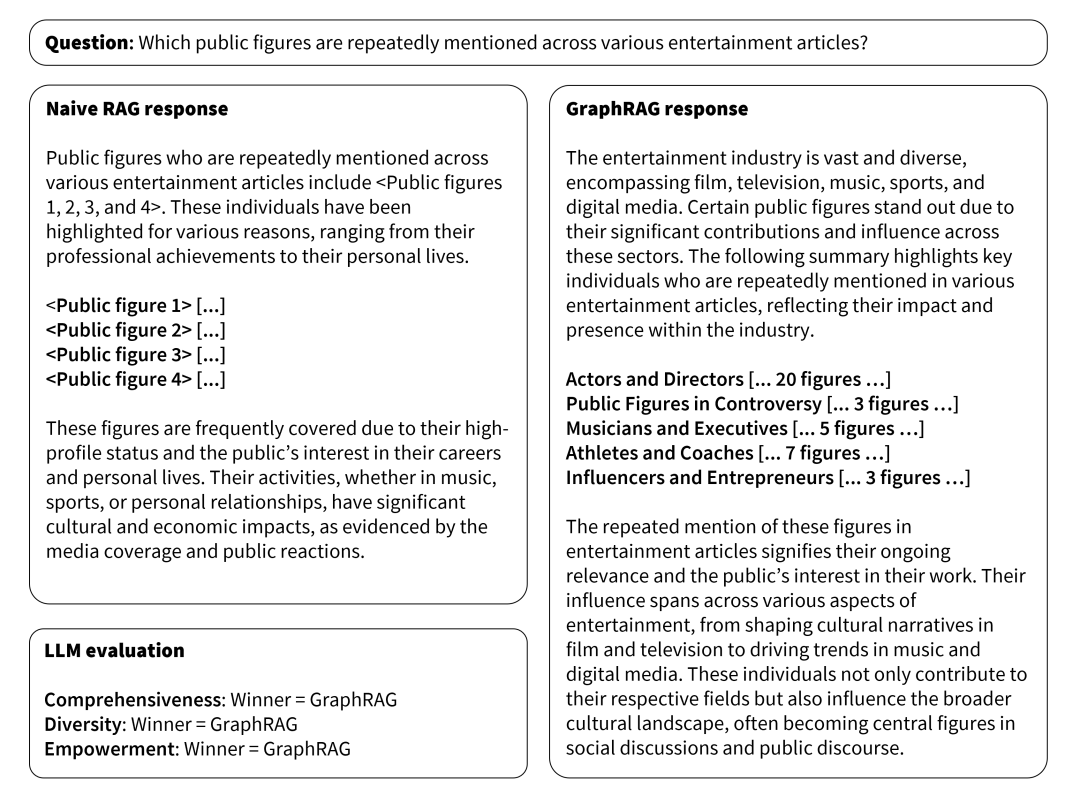
GraphRAG 和传统 RAG 对比结果
现如今,RAG 是一种使用真实世界信息改进 LLM 输出的技术,是大多数基于 LLM 的工具的重要组成部分,一般而言,RAG 使用向量相似性作为搜索,称之为 Baseline RAG(基准RAG)。但 Baseline RAG 在某些情况下表现并不完美。例如:
- Baseline RAG 难以将各个点连接起来。当回答问题需要通过共享属性遍历不同的信息片段以提供新的综合见解时,就会发生这种情况;
- 当被要求全面理解大型数据集甚至单个大型文档中的总结语义概念时,Baseline RAG 表现不佳。
微软提出的 GraphRAG 利用 LLM 根据输入的文本库创建一个知识图谱。这个图谱结合社区摘要和图机器学习的输出,在查询时增强提示。GraphRAG 在回答上述两类问题时显示出显著的改进,展现了在处理私有数据集上超越以往方法的性能。
不过,随着大家对 GraphRAG 的深入了解,他们发现其原理和内容真的让人很难理解。

近日,Neo4j 公司 CTO Philip Rathle 发布了一篇标题为《GraphRAG 宣言:将知识加入到生成式 AI 中》的博客文章,Rathle 用通俗易懂的语言详细介绍了 GraphRAG 的原理、与传统 RAG 的区别、GraphRAG 的优势等。
他表示:「你的下一个生成式 AI 应用很可能就会用上知识图谱。」

Neo4j CTO Philip Rathle
下面来看这篇文章。
我们正在逐渐认识到这一点:要使用生成式 AI 做一些真正有意义的事情,你就不能只依靠自回归 LLM 来帮你做决定。
我知道你在想什么:「用 RAG 呀。」或者微调,又或者等待 GPT-5。
是的。基于向量的检索增强式生成(RAG)和微调等技术能帮到你。而且它们也确实能足够好地解决某些用例。但有一类用例却会让所有这些技术折戟沉沙。
针对很多问题,基于向量的 RAG(以及微调)的解决方法本质上就是增大正确答案的概率。但是这两种技术都无法提供正确答案的确定程度。它们通常缺乏背景信息,难以与你已经知道的东西建立联系。此外,这些工具也不会提供线索让你了解特定决策的原因。
让我们把视线转回 2012 年,那时候谷歌推出了自己的第二代搜索引擎,并发布了一篇标志性的博客文章《Introducing the Knowledge Graph: things, not strings》。他们发现,如果在执行各种字符串处理之外再使用知识图谱来组织所有网页中用字符串表示的事物,那么有可能为搜索带来飞跃式的提升。
现在,生成式 AI 领域也出现了类似
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











