




这个项目的开发工作其实在于理解全部的YOLO代码,其实还是很苦逼的,人家一个大团队的代码我来看就比较累
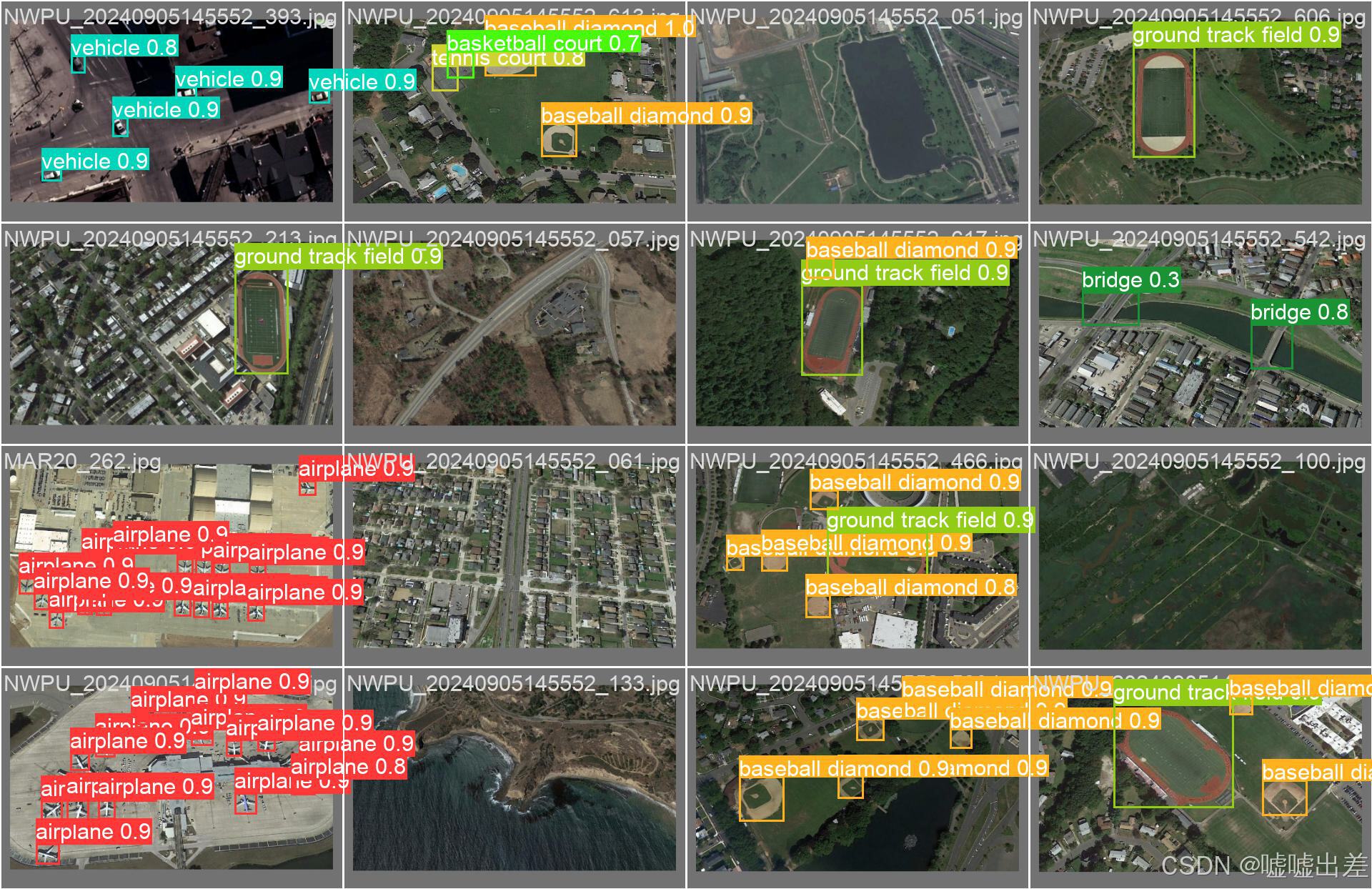
结果图如下

就是加了点别人的开源的军用飞机图像作为数据集进行训练,也就是加了些飞机样本
结果就是样本不均衡而已
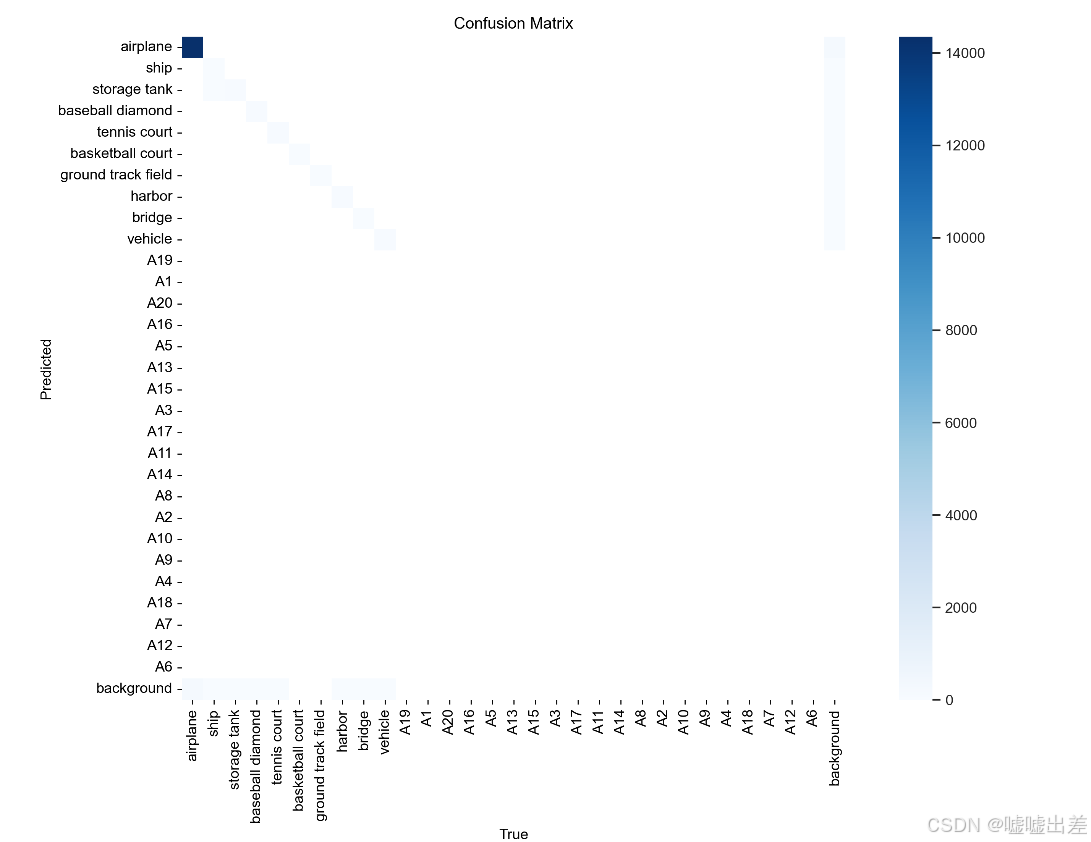
然后训练是废了
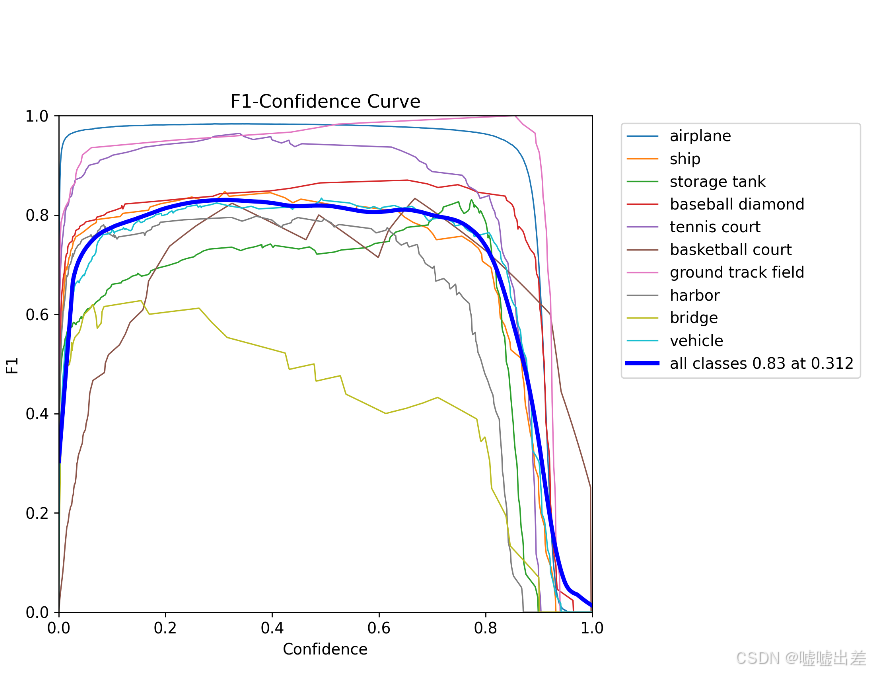
准确率
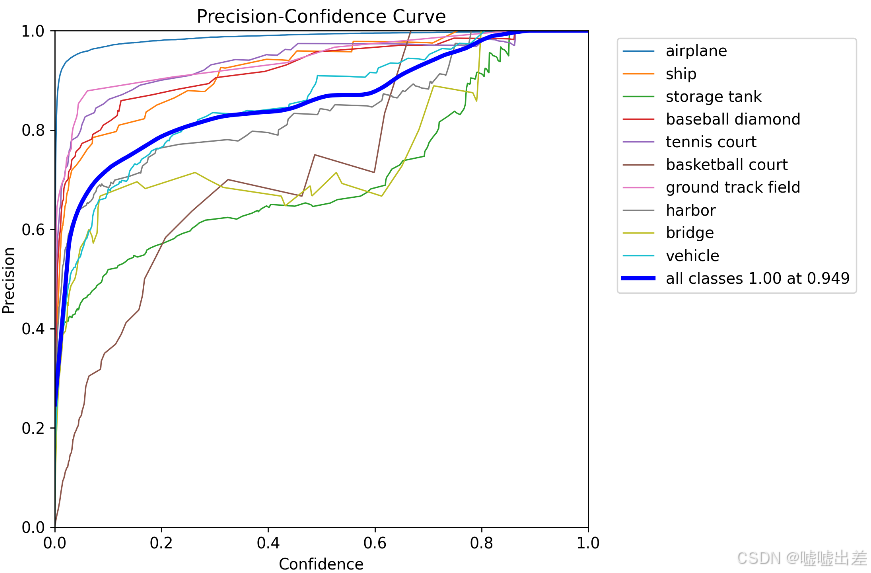
很明显不太行
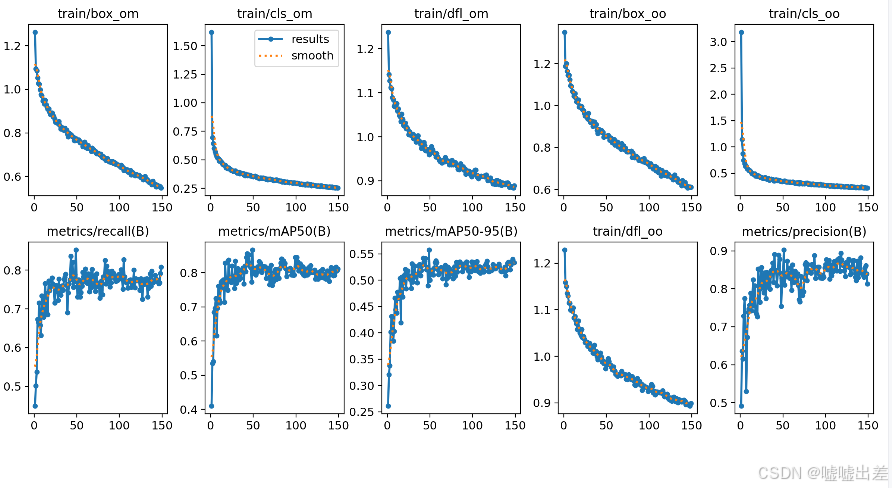
全是飞机什么的
然后
部署这个api的代码
import os
import numpy as np
import torch
from PIL.Image import Image
from PIL.ImageWin import Window
from rasterio import MemoryFile
from ultralytics import YOLOv10
from fastapi import FastAPI, File, UploadFile
from pydantic import BaseModel
import numpy as np
import torch
import rasterio
from ultralytics import YOLOv10
import requests
import json
from typing import List, Dict
app = FastAPI()
class DetectionModelPlaneService:
def __init__(self):
self.names = {
0: "airplane",
1: "ship",
2: "storage tank",
3: "baseball diamond",
4: "tennis court",
5: "basketball court",
6: "ground track field",
7: "harbor",
8: "bridge",
9: "vehicle"
}
self.model_config = 'project/v10/yolov10m.yaml'
weights_path = r'E:\System_settings\Project\yolov10-main\project\model_plane\model\runs\train\plane4\weights\best.pt'
data_config = r"E:\System_settings\Project\yolov10-main\project\model_plane\dataset\plane.yaml"
self.model = YOLOv10(data_config).load(weights_path)
def model_plane_predict(self,img,conf=0.5):
# 配置文件和权重路径
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
results = self.model.predict(
source=img,
conf=conf,
data=self.data_config,
imgsz = 512,
device=device
)
results = results[0]
# results.show()
return results.tojson()
def convert_to_geo_coordinates(self, prediction, transform, offset):
return {
"bbox": {
"left": transform[2] + offset[1] * transform[0],
"top": transform[5] + offset[0] * transform[4],
"right": transform[2] + (offset[1] + 512) * transform[0],
"bottom": transform[5] + (offset[0] + 512) * transform[4]
},
"prediction": prediction
}
def GetPostandStorage(self,tif_file: UploadFile, cache_path: str, tile_size: int = 512,
stride: int = 512):
try:
# Ensure cache path exists
if not os.path.exists(cache_path):
os.makedirs(cache_path)
# Open the TIFF file
with rasterio.open(tif_file.file) as src:
profile = src.profile
image = src.read()
transform = src.transform
if image.shape[0] == 4:
image = image[:3] # Discard alpha band if present
elif image.shape[0] != 3:
return {"id": tif_file.filename, "error_code": "Unsupported number of bands"}
# Variables to store information about slices
slice_info = []
# Calculate the number of slices required
width = src.width
height = src.height
# Handle image edges
num_x_slices = (width - tile_size) // stride + 1
num_y_slices = (height - tile_size) // stride + 1
# Loop through each slice
for x in range(num_x_slices):
for y in range(num_y_slices):
# Calculate slice bounds
col_off = x * stride
row_off = y * stride
window = Window(col_off, row_off, tile_size, tile_size)
# Check if the slice is within image bounds
if col_off + tile_size > width:
window = Window(width - tile_size, row_off, tile_size, tile_size)
if row_off + tile_size > height:
window = Window(col_off, height - tile_size, tile_size, tile_size)
transform_slice = transform * transform.scale(
width / window.width,
height / window.height
)
# Read and process the slice
slice_image = src.read(window=window)
# Convert slice image to 8-bit per channel (JPEG format)
slice_image = np.moveaxis(slice_image, 0, -1) # Move channels to last dimension
slice_image = np.clip(slice_image, 0, 255).astype(np.uint8) # Clip values to 0-255 range
# Convert to PIL Image and save as JPEG
slice_pil_image = Image.fromarray(slice_image)
slice_filename = f"{tif_file.filename}_slice_{x}_{y}.jpg"
slice_path = os.path.join(cache_path, slice_filename)
slice_pil_image.save(slice_path)
# Record slice information including geo-transform
slice_info.append({
"filename": slice_path,
"bounds": {
"left": window.col_off,
"top": window.row_off,
"right": window.col_off + window.width,
"bottom": window.row_off + window.height
},
"transform": {
"scale_x": transform_slice[0],
"scale_y": transform_slice[4],
"translation_x": transform_slice[2],
"translation_y": transform_slice[5],
"rotation_x": transform_slice[1],
"rotation_y": transform_slice[3]
}
})
for slice in slice_info:
# Load the image and run detection
img_path = os.path.join(cache_path, slice['filename'])
img = Image.open(img_path)
detections = self.model_plane_predict(img, conf=0.5)
# Process detections to geographic coordinates
slice_detections = self.process_detections(detections, slice['transform'], (tile_size, tile_size))
slice['detections'] = slice_detections
# Save updated slice info
info_file = os.path.join(cache_path, "slice_info.json")
with open(info_file, 'w') as f:
json.dump(slice_info, f, indent=4)
return {"id": tif_file.filename, "status": "success", "slice_info": slice_info}
except Exception as e:
return {"id": tif_file.filename, "error_code": str(e)}
model_service = DetectionModelPlaneService()
@app.post("/process_tif")
async def process_tif(tif_file: UploadFile = File(...), cache_path: str = "cache/"):
result = model_service.GetPostandStorage(tif_file, cache_path)
return result
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)


















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











