




前言
如此文《KungfuBot——基于物理约束和自适应运动追踪的人形全身控制PBHC,用于学习打拳或跳舞(即RL下的动作模仿和运控)》的开头所说
如此,便关注到最新出来的三个工作
- 第一个是GMT: General Motion Tracking for Humanoid Whole-Body Control
- 第二个是R2S2和OpenWBT
- 第三个则是本文要解读的KungfuBot
相当于今25年6月下旬便关注到了GMT这个工作,但当时忙于搞几个客户的项目,一直没来得及解读,而如今新的两个客户项目刚刚开搞,故有时间来解读下这个GMT
毕竟我司七月在线
- 3分科研,故一直研究 复现 改进前沿
- 7分落地,为场景落地服务 实用第一
科研中兼顾落地,可以更好科研;落地中兼顾科研,可以更好落地,这也是我司的独特优势之一
第一部分 GMT
1.1 引言、相关工作
1.1.1 引言
如原GMT论文所说,人形机器人实现的主要目标之一,是能够在日常环境中执行广泛的任务。赋予人形机器人产生多样化类人动作的能力,是实现这一目标的有力途径
- 为了生成这类类人动作,需要一个通用的全身控制器——它能够利用丰富的运动技能库,既能完成自然行走等基础任务,也能实现踢球、奔跑等更为动态和灵活的动作
- 有了这样强大的全身控制器,就可以集成高层规划器,实现技能的自主选择与编排,从而为通用型人形机器人铺平道路
由于人形系统具有高度自由度(DoF)以及现实世界动力学的复杂性,人工设计此类控制器既具有挑战性,又极为耗时。由于人形机器人旨在高度仿真人体结构,因此人体运动数据为机器人赋予丰富技能提供了理想资源
在计算机图形学领域,研究人员利用人体运动数据和基于学习的方法,开发出能够为模拟角色提供统一控制的控制器,使其能够以极具人类特征的行为,重现多种运动并执行多样化技能
- Deepmimic
事实上,GMT的方法便是基于Jason Peng在 2018 年提出的这个DeepMimic,本质上还是在用强化学习,定义一些 reward,让它去完成 tracking
————
DeepMimic的简介详见此文《从RoboMimic、DeepMimic到带物理约束的MaskMimic——人形全身运控的通用控制器:自此打通人类-动画-人形的训练路径》的第二部分 - Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
- Perpetual humanoid control for real-time simulated avatars
- Pdp: Physics-based character animation via diffusion policy
- Maskedmimic
尽管在模拟领域取得了巨大进展,但为人形机器人开发这样一种通用的统一控制器仍然具有挑战性,原因包括:
- 部分可观测性
对于现实世界中的机器人,完整的状态信息(如线速度和全局根部位置)无法获取,而这些信息在学习运动跟踪策略时非常重要
缺乏这些信息使得训练过程更加具有挑战性 - 硬件限制
现有的人体动作数据集通常包含诸如后空翻和翻滚等动作,但由于硬件限制,仿人机器人难以执行这些动作
此外,即使是行走和奔跑等较为基础的技能,机器人也可能难以产生足够的扭矩,从而无法准确匹配人体动作的速度和动态表现
这些不匹配问题在为机器人训练动作跟踪控制器时,需要额外的特殊处理 - 数据分布不均衡
大型动作捕捉数据集「如 AMASS [6-AMASS: Archive of motion capture as surface shapes]」通常表现出高度不均衡的分布,如图2所示,其中大部分动作涉及行走或原地活动
更为复杂或动态的动作较为稀缺,这可能导致机器人在掌握这些不常见但至关重要的技能时遇到困难
- 模型表达能力
虽然基于简单MLP的网络在跟踪少量动作剪辑时可能足以开发出令人满意的控制策略,但在应用于大规模Mocap数据集时往往表现不佳
这类架构通常缺乏捕捉复杂时序依赖和区分多样动作类别的能力。表达能力的不足会导致跟踪性能不理想,并且在广泛技能范围内的泛化能力较差
尽管已有研究尝试解决上述某些单独的问题,例如
- 采用师生训练框架应对部分可观测性[7-Exbody2,8-Omnih2o]
- 利用多类小型数据集对不同的专家策略进行微调[7-Exbody2]
- 以及采用transformer模型提升模型的表达能力[9-Humanplus]
但开发一个统一的通用运动跟踪控制器仍然是一个未解难题
对此,来自1 UC San Diego、2 Simon Fraser University的研究者于25年6月份通过联合解决这些问题,并结合其他精心的设计决策,构建一个高效的系统GMT,且能够从大型动作捕捉数据集为现实世界的人形机器人训练单一统一且高质量的运动跟踪策略
- 其对应的paper为:GMT: General Motion Tracking for Humanoid Whole-Body Control
其对应的作者为
Zixuan Chen∗1,2、Mazeyu Ji∗1、Xuxin Cheng1、Xuanbin Peng1
Xue Bin Peng†2、Xiaolong Wang†1
————
值得一提的是,这个队伍的不少人,则之前参与了Exbody 2的开发 - 其对应的项目地址为:gmt-humanoid.github.io
其对应的GitHub地址为:github.com/zixuan417/humanoid-general-motion-tracking
截止到25年9月中旬,GitHub上面说,Data processing and retargeter code will be released soon.
GMT 的核心有两项关键创新:
- 一种新颖的自适应采样策略,旨在缓解由于动作类别分布不均导致学习罕见动作困难的问题
- 以及一种运动专家混合(MoE)架构,以增强模型的表达能力和泛化能力
图1 展示了GMT策略在现实世界中的部署,表明其能够通过策略在执行广泛的上半身和下半身技能(包括不同的步态、下蹲、踢腿及其他富有表现力的全身动作)方面的能力,并通过单一统一策略实现了业界领先的性能

表1简要对比了GMT与高度相关的现有研究

1.1.2 相关工作
开发一种通用的全身控制器,使人形机器人能够执行广泛的技能,一直是一个基础但极具挑战性的问题,主要原因在于系统的高维度和固有的不稳定性
- 传统的基于模型的方法通过步态规划和动力学建模,已经实现了对双足和人形机器人具有鲁棒性的全身运动控制器
12-Dynamic walk of a biped
13-A compliant hybrid zero dynamics controller for stable, efficient and fast bipedal walking on mabel
14-Positive force feedback in bouncing gaits? Proceedings of the Royal Society of London
然而,设计此类控制器通常需要大量的人工投入,并且需要对复杂动力学进行细致处理 - 近年来,基于学习的方法在构建全身控制器方面取得了显著进展
这些方法
要么通过精心设计的任务奖励来开发控制器
15-Humanoid locomotion as next token prediction
16-Learning humanoid locomotion over challenging terrain
17-Real-world humanoid locomotion with reinforcement learning,详见此文:伯克利Digit——基于下一个token预测技术预测机器人动作token:从带RL到不带RL的自回归预测
18-Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
19-Learning smooth humanoid locomotion through lipschitz-constrained policies
20-Homie
21-Whole-body humanoid robot locomotion with human reference,其首次将人类运动数据用于全尺寸人形机器人的模仿学习
要么以人类动作为参考
11-ASAP
8-Omnih2o
9-Humanplus
7-Exbody2
10-Exbody,Expressive whole-body control for humanoid robots
22-Hover
23-H2O
首先,对于基于学习的人形机器人全身控制
本研究聚焦于人形机器人的全身控制
- 以往的研究表明,通过手动设计奖励函数训练的全身控制策略,能够使人形机器人实现如行走[15,16,17,18,19]
跳跃
24-Wococo: Learning whole-body humanoid control with sequential contacts
25-Humanoid parkour learning
26-A unified and general humanoid whole-body controller for fine-grained locomotion
以及跌倒恢复
27- Learning getting-up policies for real-world humanoid robots
28- Learning humanoid standing-up control across diverse postures
等运动技能 - 然而,这些控制器通常是针对特定任务设计的,需要为每个任务分别训练带有定制奖励函数的策略。例如,为行走开发的策略难以直接迁移到跳跃或操作等其他任务中
相比之下,人类运动数据为开发通用控制器提供了一种有前景的方法,无需为每一项技能单独设计任务特定的奖励函数
其次,对于人形动作模仿
利用人体运动数据为机器人开发类人的全身行为在角色动画领域得到了广泛研究
- 以往的工作已经在仿真角色上实现了高质量且通用的动作追踪
1-Deepmimic
3-Perpetual humanoid control for real-time simulated avatars
5-Maskedmimic
4-Pdp: Physics-based character animation via diffusion policy
并为各种下游任务提供了多样化的动作技能任务
29-Amp: Adversarial motion priors for stylized physics-based character control
2-Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
30-Calm: Conditional adversarial latent models for directable virtual characters
31- Synthesizing physical character-scene interactions
32-Learning physically simulated tennis skills from broadcast videos
然而,由于现实世界中的部分可观测性,为真实机器人开发此类全身控制器
10-Exbody
33-Mobiletelevision
9-Humanplus
8-Omnih2o
7-Exbody2
11-ASAP
34-Vmp: Versatile motion priors for robustly tracking motion on physical characters
35-Learning from massive human videos for universal humanoid pose control
36-Opt2skill: Imitating dynamically-feasible whole-body trajectories for versatile humanoid locomanipulation
具有挑战性 - 为开发统一的通用全身运动跟踪控制器,一些工作将上半身与下半身控制解耦,以在表现力与平衡性之间做出权衡
10-Exbody
33-Mobiletelevision
HumanPlus [9] 和 OmniH2O [8] 随后在全尺寸机器人上成功实现了全身动作模仿,但下半身动作不自然
1.2 通用运动跟踪控制器的学习
GMT采用了与先前研究[7-Exbody2,8-Omnih2o]类似的两阶段师生训练框架:
- 首先使用PPO[37]训练具有特权信息的教师策略
即,继先前的研究[7,8],在第一阶段,训练一个具有特权的教师策略,该策略能够同时观察本体感知信息和特权信息,并输出关节目标动作,使用PPO [37]进行优化
- 然后通过DAgger[38]模仿教师策略的输出来训练一个可部署的学生策略
该策略以一系列本体感知观测历史作为输入,并通过DAgger [38]由教师策略进行监督。学生策略通过最小化其输出与教师输出
之间的ℓ2损失,即
,实现优化
- 对于仿真到现实迁移
为了实现成功的仿真到现实迁移,作者在教师策略和学生策略的训练过程中应用了域随机化方法
41- Sim-to-real transfer of robotic control with dynamics randomization
42- Learning to walk in minutes using massively parallel deep reinforcement learning
为了进一步对齐仿真与现实世界的物理动力学,且显式建模了减速器转动惯量的影响
具体而言,给定减速比k和减速器转动惯量I,作者在仿真器中将armature参数配置为:
以近似由减速驱动器引入的有效惯量- 作者使用 IsaacGym [43] 作为物理仿真器,并设置了4096个并行环境。在一块 RTX4090GPU 上,特权策略训练大约持续3天,随后学生策略训练约1天。仿真频率为500Hz,控制频率为50Hz
训练完成的策略会先在 Mujoco [46] 中进行验证,然后再部署到真实机器人上
在原GMT论文中,是首先介绍的方法核心组成部分,即自适应采样策略和运动MoE架构。随后,再介绍的对策略学习同样至关重要的一些关键设计,包括运动输入设计和数据集整理流程
但我个人认为,先介绍数据集和采样策略,再介绍模型结构,最后再介绍模型结构基础上的运动输入设计,更符合工程流程,和人们循序渐进的认知流程,故我调整了 解读顺序
1.2.1 数据集整理:去除噪音 比如机器人没法完成的超高难度动作
作者使用AMASS [6] 和LAFAN1 [39] 的组合来训练动作追踪策略。由于原始数据集包含由于硬件限制而出现的不可行动作,如爬行、倒地状态以及极端动态动作
由于不可行动作代表噪声并可能阻碍学习,作者采用了与以往工作[5] 类似的两阶段数据筛选流程
- 在第一阶段,应用基于规则的过滤,去除不可行的动作——例如,根部的横滚或俯仰角度超过指定阈值,或根部高度异常高或低的动作
- 在第二阶段,在经过前述过滤的数据集上训练一个初步策略,样本量约为50 亿
根据该策略的完成率,进一步过滤掉失败的动作,最终得到的训练数据集为经过筛选的AMASS 和LAFAN1 子集,共计8925 段,总时长33.12 小时
1.2.2 自适应采样:复杂的动作多 sample ,简单的动作少 sample
如图2所示
- 大型动作数据集(如AMASS [6])存在显著的类别不平衡。这种不平衡会极大阻碍对较少出现且更为复杂动作的学习
- 此外,这类数据集中的较长序列通常是复合动作,由一系列技能组成,既包含基础片段,也包含具有挑战性的片段
采用以往的采样策略[5-Maskedmimic,3- Perpetual humanoid control for real-time simulated
avatars] 时,当策略在较难片段上失败,仍会在整个动作序列上进行训练——而序列大多被简单部分主导——这导致困难片段的有效采样率很低
说白了,如作者所说
- 动作数据里面有的比较简单,比如走路,有的则比较复杂,比如跳舞、跳跃这些非周期性的运动
像在 AMASS 或 LAFAN 这样的数据集里,60-70% 都是走路,剩下的 30% 才是比较有挑战性的动作- 但作者希望 policy 既能学到简单的动作,也能学到复杂的动作,所以需要做 adaptive sampling
具体来说,就是给不同的动作分配一个概率,复杂的动作多 sample 一些,简单的动作少 sample 一些,这样能在训练中达到平衡
为了解决这些问题,作者引入了自适应采样方法,该方法包含两个关键组成部分
- 随机剪辑
时长超过10秒的动作会被剪切成多个子片段,每个子片段的最长时长为10秒
且为了防止片段衔接处出现伪影,作者通过引入最多2秒的随机偏移,实现了随机化剪辑
此外,所有动作在训练过程中都会定期重新裁剪,以进一步丰富采样的子片段; - 基于跟踪性能的概率
在训练过程中,作者会记录每个动作的完成度,并在跟踪误差超过
时终止该回合
当某一动作成功完成时,
因此,每个动作的采样概率定义为:
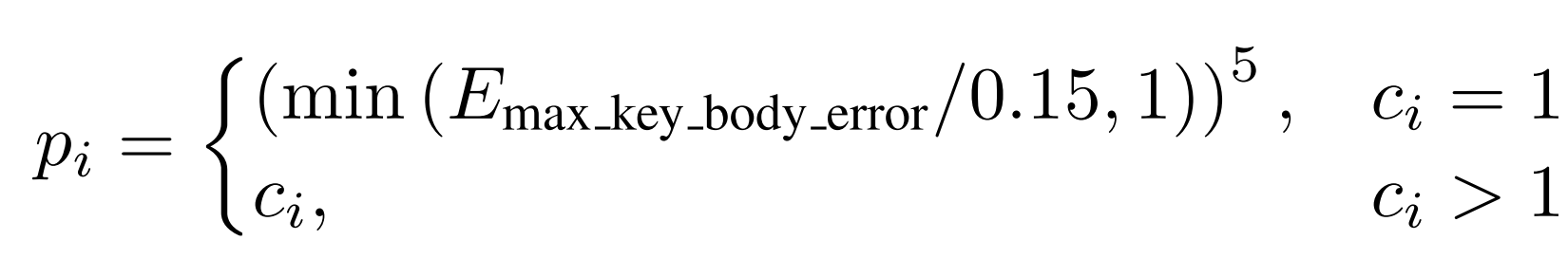
通过应用自适应采样,作者避免了对长动作中简单片段的重复采样,从而将训练重点放在跟踪误差较高的难动作上,以提升模型表现
1.2.3 动作混合专家模型
如作者所说
- 之前很多工作,尤其在 locomotion 上,都是用很简单的 MLP 网络。但现在需要一个 policy 去 handle 各种各样的 motion,而且这些 motion 时间跨度很长,MLP 很多时候就不够用了
- 故为了增强模型的表达能力,作者在教师策略的训练过程中引入了一个软MoE 模块——有很多个 expert,这个设计是借鉴了大语言模型里的思路
具体模型如图3 所示「其中, 表示运动目标帧,
表示本体感知观测,
表示特权信息」

策略网络由一组专家网络和一个门控网络组成「The policy network consists of a group of expert networks and a gating network」
- 专家网络expert networks以机器人状态观测和运动目标为输入,输出最终动作
- 门控网络gating network 同样以相同的观测输入,并输出对所有专家的概率分布
最终的动作输出是从每个专家的动作分布中采样的动作的加权组合:,其中
为门控网络输出的每个专家的概率,
为每个专家策略的输出
对于观测与动作
- 对于教师策略,观测由本体感知
、特权信息
和运动目标
组成
- 对于学生策略,观测包括本体感知
,以及运动目标
1.2.4 动作输入:运动跟踪——让机器人在每一帧运动中跟踪特定的目标
运动跟踪的目标是让机器人在每一帧运动中跟踪特定的目标
作者将每一帧的运动跟踪目标表示为
其中
表示关节位置
表示基座的线速度和角速度
表示基座的横滚角和俯仰角
表示根部高度
对应于局部关键部位的位置
与以往采用全局关键部位位置的方法不同[8, 11],作者采用类似ExBody2[7] 的局部关键部位位置,并进一步改进为使局部关键部位相对于机器人的朝向对齐
- 此外,为了提高跟踪性能,作者不仅仅使用紧接着的下一个运动帧作为输入[7, 10, 8]。相反,作者堆叠了多个连续帧
,覆盖大约两秒的未来运动
- 这些堆叠的帧随后通过卷积[40] 编码器压缩为一个潜在向量
,然后与紧接着的下一帧
结合,并输入到策略网络中
该设计使得策略能够捕捉到运动序列的长期趋势,并能够明确识别当前的跟踪目标
作者在实验中表明,这一设计对于实现高质量的跟踪至关重要
在本研究中,运动追踪问题被定义为一个以目标为条件的强化学习问题,其中在给定目标的情况下,智能体根据策略π 与环境交互,以最大化目标函数[47]
- 在每一个时间步
,智能体的策略以状态
和目标
作为输入,输出动作
- 当动作
,会导致下一个状态
。在每一个时间步,都会获得奖励
智能体的目标是最大化期望回报:
其中
表示轨迹
的概率,
表示时间范围,
是折扣因子
下表表3是第一阶段训练的奖励函数。这里
表示关节位置,
表示关节速度,
表示关节加速度,r表示根部旋转,v 表示根部速度,h 表示根部高度,p 表示关键身体位置

1.3 实验
1.3.1 实验设置
在仿真和真实环境中评估GMT
- 对于仿真实验,每个策略使用大约68 亿个样本进行训练,采用领域随机化[41] 和动作延迟[42],训练数据来自经过筛选的AMASS 和LAFAN1[39] 数据集子集;并在AMASS 测试集[3] 和LAFAN1 上进行评估
且使用IsaacGym[43] 作为仿真器,并行环境数量为4096 - 对于消融实验和基线对比,作者主要关注特权策略的性能评估,因为可部署的学生策略仅通过模仿特权教师进行训练
- 对于真实环境实验,作者将他们的策略部署在Unitree G1 [44] 上,这是一款具有23 自由度、身高1.32 米的中型人形机器人
策略的跟踪性能通过以下指标进行定量评估:
- Empkpe,每个关键身体位置的平均误差,单位为mm
- Empjpe,每个关节位置的平均误差,单位为rad
- Evel,线速度误差,单位为m/s
- Evaw,偏航速度误差,单位为rad/s
1.3.2 基线方法
在仿真中将GMT 的性能与ExBody2 [7] 进行了对比
作者重新实现了ExBody2,并在他们筛选后的数据集上对其进行了训练
从表2 可以看出
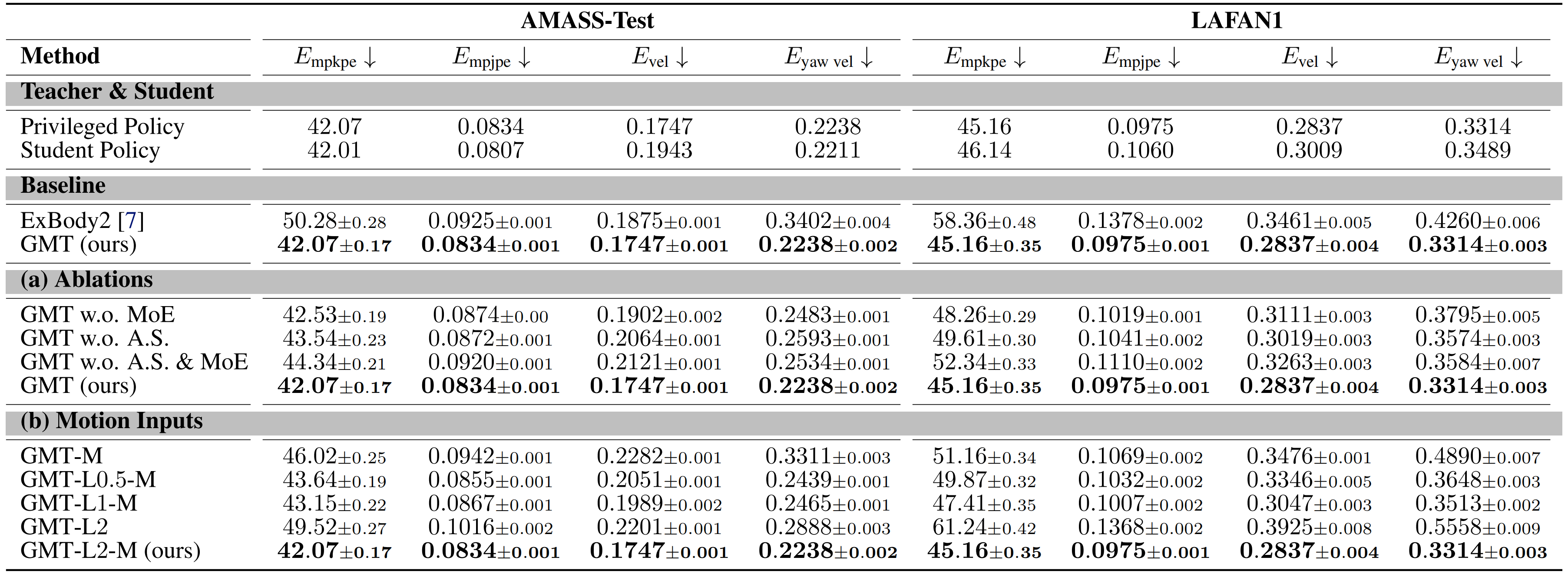
GMT 在局部跟踪性能(Empkpe 和Empjpe )以及全局跟踪性能(Evel 和Eyaw vel ) )上均优于ExBody2
1.3.3 消融研究
在本部分,作者进行了消融实验,以探究各个组件的贡献
具体而言,为了评估Motion MoE架构和自适应采样策略的效果,设计了如下消融方案:
- GMT w.o. A.S. & MoE:将MoE模型替换为参数量相等的MLP,并移除自适应采样
- GMT w.o. MoE:仅将MoE模型替换为相同规模的MLP
相当于有自适应采样,但无MoE结构 - GMTw.o. A.S.:训练过程中仅移除自适应采样
相当于无自适应采样,但有MoE结构
此外,作者还通过消融实验研究了运动输入配置的影响:
- GMT-M:仅将运动的下一个即时帧作为输入提供给策略网络
- GMT-Lx-M:将下一个即时帧以及未来x秒的运动帧窗口一同输入到策略网络中
- GMT-Lx:仅输入未来x秒的运动帧窗口,不包括下一个即时帧
1.3.3.1 动作混合专家(Motion MoE)
如表2(a) 所示,GMT 在AMASS 测试集和整个LAFAN1 数据集上的跟踪性能均优于基线方法

- 此外,如下图图5 所示,记录了AMASS 上的顶端百分位跟踪误差。统计数据和图表均表明,MoE 在更具挑战性的动作上有更大的提升

- 对于定性评估,图4 可视化了在一个包含站立、踢腿、向后走几步以及再次站立的复合动作序列上的专家选择

各专家随时间的门控权重显示出在动作不同阶段专家激活的明显转换。这表明各专家在不同类型的动作上具有专长,验证了MoE 结构在捕捉动作多样性方面的预期作用
1.3.3.2 自适应采样
如表2(a)所示
自适应采样在两个数据集上均有效提升了跟踪性能
与MotionMoE类似,如图5所示
自适应采样在更具挑战性的动作上提升更为显著
- 为了定性评估该策略的影响,作者从一个长达240秒且复合的动作序列中提取了一个短片段,并在图6(a)中对比了采用和未采用自适应采样训练的策略的表现

- 此外,作者在图6(b)中绘制了关键关节(包括膝关节和髋关节滚转)的力矩
结果显示,如果没有自适应采样,策略无法高质量地学习该片段,并且难以保持平衡。这些问题使得实际部署变得不可能
1.3.3.3 运动输入
表2(b)中的实验结果显示,增加运动输入窗口的长度可以提升跟踪精度。然而,GMT-L2的性能却出现了显著下降,这表明将紧接着的下一帧输入到策略网络同样至关重要

这可以解释为,虽然一系列未来帧能够捕捉即将发生运动的整体趋势,但可能会丢失一些细节信息。因此,输入紧接着的下一帧纳入策略中,可以通过提供最近的相关信息显著提升跟踪性能
1.3.4 真实世界部署与应用
如图1所示,作者宣称,他们已成功将他们的策略部署在真实的人形机器人上,能够高保真地再现多种人类动作——包括风格化行走、高抬腿踢、跳舞、旋转、蹲姿行走、足球踢球等,并实现了业界领先的性能
且在 MuJoCo [46] 的仿真到仿真(sim-to-sim)环境中,使用动作扩散模型MDM『45,详见此文《可跳简单舞蹈的Exbody 2——从MDM、RobotMDM到全身运动控制策略Exbody:人体运动扩散模型赋能机器人的训练》的1.1节 动态扩散模型MDM』生成的动作对他们的策略进行了测试
图 7 的结果显示

GMT 能够很好地执行通过文本提示由 MDM生成的动作,这证明了 GMT 应用于其他下游任务的潜力
总之,本文提出了GMT,一种通用且可扩展的运动跟踪框架,可以通过训练单一统一策略,使人形机器人在现实世界中模仿多样化的动作
且作者进行了大量实验,评估了各个组件对整体跟踪性能的贡献,并证明GMT能够跟踪来自其他资源(如MDM)的动作
当然,尽管GMT作为一个统一的通用运动跟踪控制器实现了业界领先的性能,但它仍然存在一些局限性:
- 缺乏丰富接触的技能
由于模拟接触丰富行为所需的额外复杂性显著增加 [27],再加上硬件的限制,他们的框架目前尚不支持诸如从倒地状态起身或在地面翻滚等技能 - 对复杂地形的局限性
他们当前的策略是在没有任何地形观测的情况下训练的,因此并未针对斜坡和楼梯等复杂地形进行模仿设计
未来的工作中,作者宣称,计划扩展他们的框架,开发一个能够在平坦和复杂地形上均可运行的通用且鲁棒的控制器


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











