







前言
关注到此文,有两个因素
- 之前在本博客中解读过HIL-SERL,而其一作Jianlan Luo参与了我个人认为比较有意思的一个工作:Yell At Your Robot 🗣️ Improving On-the-Fly from Language Corrections——即是本文
- 因为要在我司的具身机器人复现实战营中讲ACT「详见此文《一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)》」,所以我最近在梳理ACT在各个机器人模型中的应用,而本文的YAY Robot动作策略预测也是用的ACT
故,本文来了
第一部分 YAY-robot
1.1 YAY-robot的提出背景与相关工作
1.1.1 提出背景
复杂的机器人任务可能需要多个单独的基础动作的序列,比如将多个物品装入袋子中需要依次抓取每个物体,将其移动到袋口附近,然后插入
解决此类多阶段任务的一个常用框架是通过分层抽象,其中高级策略指挥具体行为,然后由低级策略执行这些行为 [36,68,69,18]
- 一种直观的方法是通过语言参数化这些策略,使用高级策略在每个阶段选择可能的语言指令 [8,1]。不幸的是,随着任务阶段数量的增加,故障点也随之增加
然而,一个稳健的高级策略可以弥补低级故障,根据需要进行纠正和调整
因此,成功完成此类多阶段任务关键在于以一种稳健的方式训练此类高级策略,使其能够意识到低级基础动作的局限性,并适应问题的动态变化 - 不幸的是,以可扩展的方式做到这一点很困难
比如,虽然完整的端到端机器人长视距任务演示提供了“黄金标准”的监督,因为它们使高层次能够完全了解低层次控制的复杂性,但由于任务太长,收集这些演示在大规模上既昂贵又耗时
而来自大型语言模型(如使用LLM或VLM进行规划的工作[1,24,23])提供了一种有吸引力的替代方案,但这种知识没有与机器人行为相结合,使得高层策略相对脆弱,因为它不知道哪些技能在此特定机器人和特定情况下更或更少有效
至于其他间接监督模式,如仅语言监督[17]或人类视频[44,5,58],同样提供间接监督。因此,训练稳健的高层策略的挑战可以被视为获得可扩展且高质量的高层训练数据的挑战 - 如果不需要对这种高级策略进行广泛的监督演示,而是可以通过人类的语言纠正形式的自然反馈来训练它们呢?这种反馈对人类来说是自然的,甚至可以在机器人日常工作中自然地收集到,因为它尝试完成所需任务并从人类用户那里获得反馈
毕竟当高级策略输出语言命令时,这种语言反馈可以很容易地纳入分层策略中,实际上这个过程可以被视为广泛使用的DAgger [52,28] 算法的高级类比——一种机器人迭代地从人类监督者那里获取反馈的技术,通常以低级别的运动动作形式——但在高级指令策略的动作空间中(即在语言指令上)
如此,通过纳入语言纠正,高级策略能够纠正低级策略和高级策略所犯的错误。这有助于从失败中稳健恢复,这对于在长时间任务中取得成功至关重要
基于第三点,24年3月份,来自1Stanford University、2UC Berkeley的研究者提出了“Yell At YourRobot (YAY Robot)”系统,通过自然语言反馈改善机器人训练后性能,如下图所示「使机器人能够利用口头纠正来提高在复杂的长时间任务上的表现,如打包自封袋和准备混合坚果。它可以实时(上)和持续改进(下)地结合口头纠正」
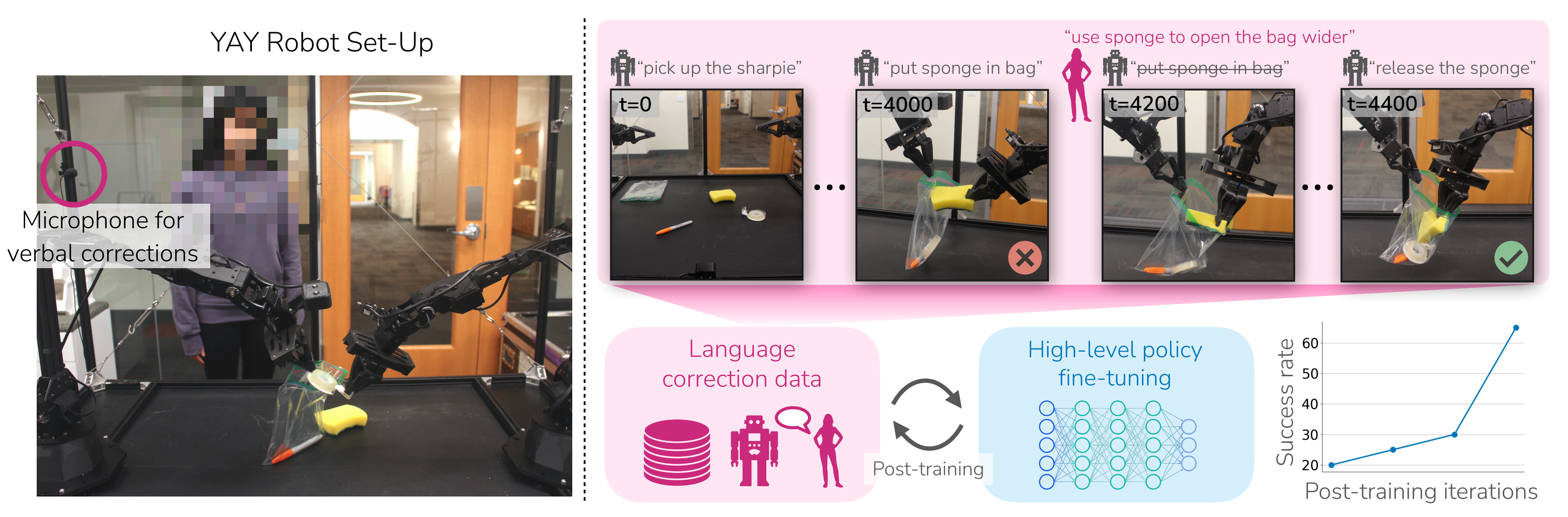
- 其对应的论文为:《Yell At Your Robot: Improving On-the-Fly from Language Corrections》
其对应的作者为:Lucy Xiaoyang Shi1、Zheyuan Hu2、Tony Z. Zhao1、Archit Sharma1
Karl Pertsch1,2、Jianlan Luo2、Sergey Levine2、Chelsea Finn1 - 其对应的项目地址为:yay-robot.github.io
其github地址:github.com/yay-robot/yay_robot
1.1.2 相关工作
使用自然语言表示低级行为在高级决策中具有多种理想特性
- 首先,自然语言提供了一种紧凑且可组合的表示形式,可以实现组合泛化[57, 3,27]。这使得它成为解决长周期任务的一个引人注目的抽象[27, 54, 19, 2],尤其是在大规模语言模型日益用于高级规划的情况下[1, 23, 32, 24,65]
- 其次,语言为人类提供了一种自然的界面,可以通过与机器人交谈来指导、纠正和改进机器人。人类参与的模仿学习技术通常需要人们通过远程操作或运动教学来干预和纠正机器人行为[52,28, 41, 22, 21, 34]。相比之下,自然语言更易于访问,最近的研究表明,它可以使人类实时与机器人互动和指导[39],在共享自主设置中为高级计划[7, 55]或低级行为[10, 12]提供即时纠正,修改代码[33],甚至通过将语言纠正转换为新的目标行动来事后更新低级行为[35]
YAY的工作结合了这两种特性的优势
具体而言,YAY Robot 学习了一个语言条件的低级策略并训练高级策略以输出自然语言指令来组合低级技能以完成长时间任务
此外,YAY机器人可以在部署后通过口头纠正微调高级策略,从而在困难的长时间任务中持续提高性能
- 与OLAF [35]相比,YAY机器人可以通过人类语言干预即时修改机器人行为,并且可以从原始像素观测中端到端学习,而无需任何显式的状态估计
与其他设计用于共享自治的工作[7,10,12,67]相比,这些工作要求人类持续提供纠正,YAY机器人被设计为能够自主操作,同时在提供口头纠正时仍能提高性 - 一项同时进行的工作RT-H [6]也有从语言纠正中学习的类似想法
然而,RT-H的纠正仅限于一组固定的空间移动,而YAY则允许灵活、多样的用户输入,例如“用海绵把袋子打开得更宽”,以解决长时间、双手灵巧操作任务
1.2 整体概览:YAY-robot系统的各个组件
预备知识:基础数据集与校正数据集
机器人操作任务表述为一个马尔可夫决策过程(MDP),记为,其中
表示状态空间,
表示动作空间,
表示转移概率,
表示初始状态分布。机器人无法访问真实状态
;相反,它接收到的是部分观测的
- 为了训练机器人的高级策略
和低级策略
,作者利用了一个基础数据集
,由序列
组成,其中
代表观测,包括RGB 图像和机器人本体感知信息,
是机器人的动作,
是时间
给出的语言指令
这个数据集被认为涵盖了完成任务所需的广泛视觉运动技能,以及各种错误和恢复行为 - 在初始训练阶段之后,作者微调机器人的高层策略以使其与人类的语言反馈对齐。这是通过使用一个校正数据集
来完成的,该数据集由在线用户交互数据组成,
−这些数据是在人与机器人交互过程中自然产生的
与基础数据集不同,校正数据集
1.2.1 第一步 低级行为克隆与高级策略
首先,对于语言条件下的低级行为克隆
当高层策略有自由度来编排纠正先前错误的技能后,低层策略则可以动态地适应这些纠正和调整。出于对这种灵活性的需求,低层策略被实现为一个深度神经网络,该网络在包含多样化视觉运动技能的数据集上进行端到端训练,涵盖从任务中心的指令(如“倒入袋子”)到与任务无关的纠正(如“将左臂向我移动”)等技能
低层策略将当前观测
和语言指令
映射为动作
。该策略使用标准行为克隆BC目标进行训练
其中LBC 是一个损失函数(例如, 或
),用于将预测的连续动作与真实动作进行比较
其次,对于自动指令生成的高级策略
分层设置可以让机器人重用基本技能。因此,学习一种高级策略来生成指导低级策略的语言指令。这策略还通过行为克隆训练,以预测基于当前观测的语言指令
- 类似于视觉-语言模型VLM,它处理图像观测并输出语言嵌入。由于相同的观测可以导致不同的命令(例如,当机器人靠近食物容器时,“将铲子向下倾斜”和“稍微抬高”都是合理的),通过基于短暂的观测历史来为指令提供上下文
高层策略表示为,其中
是时间
- 该模型也是端到端训练的,使用交叉熵损失将生成的语言指令与训练数据集中对齐。logits是通过余弦相似性获得的
训练目标可以表述为
其中 是交叉熵损失函数
1.2.2 第二步 整合低级策略与高级策略:且适应人类反馈
YAY机器人整合这些策略以创建一个能够适应实时语言反馈的统一系统。如下图图3所示
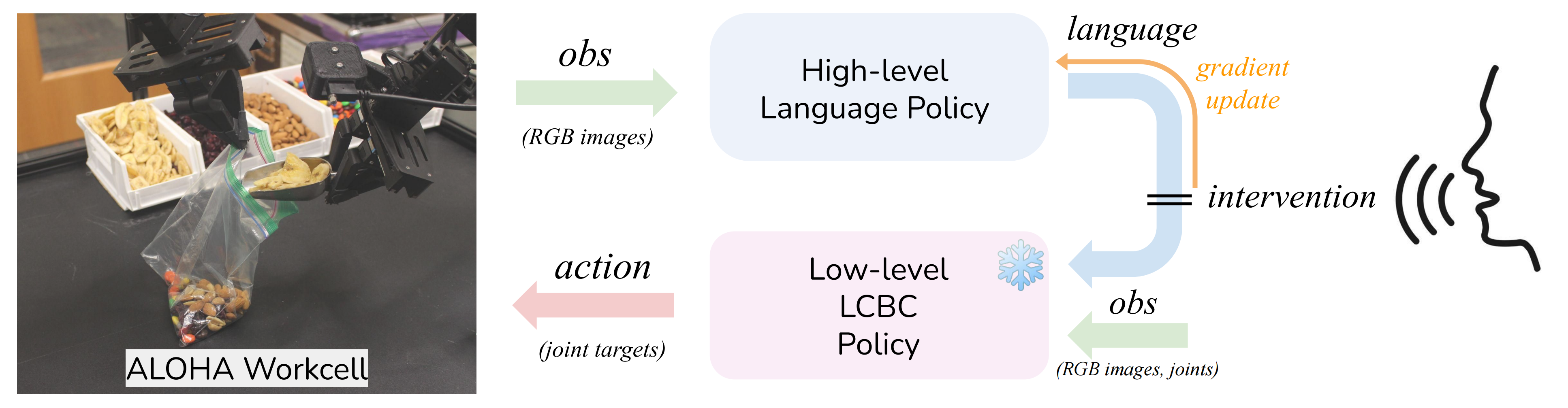
高级策略生成低级策略的语言指令,然后让低级策略执行相应的技能。在部署期间,人类可能通过提供纠正性语言命令来干预以纠正错误行为或表示偏好。用户的口头干预暂时覆盖高级策略的输出,直接影响低级策略以实现即时适应
其中
表示用户提供的语言命令,相当于人类干预,需要更新高级策略——此干预被记录为校正数据集
,随后用于微调
,相当于无人类干预
1.2.3 第三步 人类反馈的持续改进
基于实时适应能力,YAY机器人旨在不断学习,以减少对持续修正的需求,并随着时间的推移更好地符合用户偏好。YAY机器人的持续改进是通过将人类语言反馈纳入高层策略来驱动的。这个过程在概念上类似于在高层策略上执行人类门控DAgger「HG-DAgger [28]」,其动作是语言命令
关键的是,与DAgger和HG-DAgger的典型使用不同,干预仅以自然语言而不是低级机器人动作提供。在整个后训练过程中,低级策略保持冻结状态
- 通过组合数据集微调高层策略
作者在校正数据集增强了策略对由低层或高层策略错误导致的多样场景的暴露,这些都需要进行校正
这个过程使策略的预测与初始训练指令和人类校正反馈保持一致
优化目标与方程(2)中的相同
- 迭代改进
在第III-D节的用户交互和反馈收集的每次迭代之后,对策略进行微调以反映新的数据
这个迭代过程可以描述为
这里,和
分别表示微调第
次迭代前后的高层策略。
是第n 次迭代中获得的纠正反馈数据集
这个微调过程确保YAY 机器人能够逐步提高自主处理复杂任务的能力,而无需频繁干预
1.3 深入细节:实际实例化和实现
1.3.1 预训练数据收集和处理
1) 对于语言标注
需要带有语言标注的机器人数据来对基础策略进行预训练
- 传统方法涉及事后语言标注,操作员观看机器人视频并为每个技能片段标注开始和结束时间戳。然而,这个过程非常繁琐,特别是对于包含众多技能片段的长时任务
- 为了简化这一过程,作者采用了一种更高效的数据收集方法:实时解说
通过在机器人附近放置一个麦克风,操作员可以实时解说他们正在执行的技能。他们首先口述预期的技能,然后远程操作机器人执行该技能。录制的音频随后使用Whisper [51]模型转录为文本,并与机器人的轨迹同步
作者的代码自动化了这一过程,并开源以促进涉及语言标注数据收集的研究
2) 对于过滤错误
他们的数据包括成功执行和导致后续恢复的错误。如果在所有数据上进行训练,模型可能会学会故意犯错(见第V-D节)。一个直观的想法是过滤掉更正之前的片段,因为它们可能是错误的或次优的,应该从训练中排除
然而,传统上识别错误需要昂贵的事后标记。作者通过区分指令和更正来简化这一过程
为实现这一区分,我们在数据收集过程中使用脚踏板。当叙述一项新技能(指令)时,操作员踩下指令踏板。如果需要更正,他们踩下更正踏板。这种方法可以快速过滤掉导致更正的片段,确保它们不用于训练
3) 对于低级更正技能的收集
对于灵巧的、长视野的任务,操作员自然会犯错,他们的恢复行为有助于收集更正技能。然而,操作员犯错和机器人犯错的情况可能不同
- 因此,为了确保收集到对机器人相关且实用的更正技能,作者评估策略性能以确定收集哪些技能
- 即使用现有数据训练机器人,并在策略执行期间,每当操作员观察到,例如,“我希望我可以告诉机器人稍微调整它的夹具”——当机器人表现不佳时,这些更正被叙述并包含在未来的训练数据收集中
1.3.2 低级策略与高级策略
对于低级策略,其旨在基于视觉和语言输入执行精确和复杂的机器人动作。为此,作者使用动作分块transformer——ACT[70],如下图右侧所示
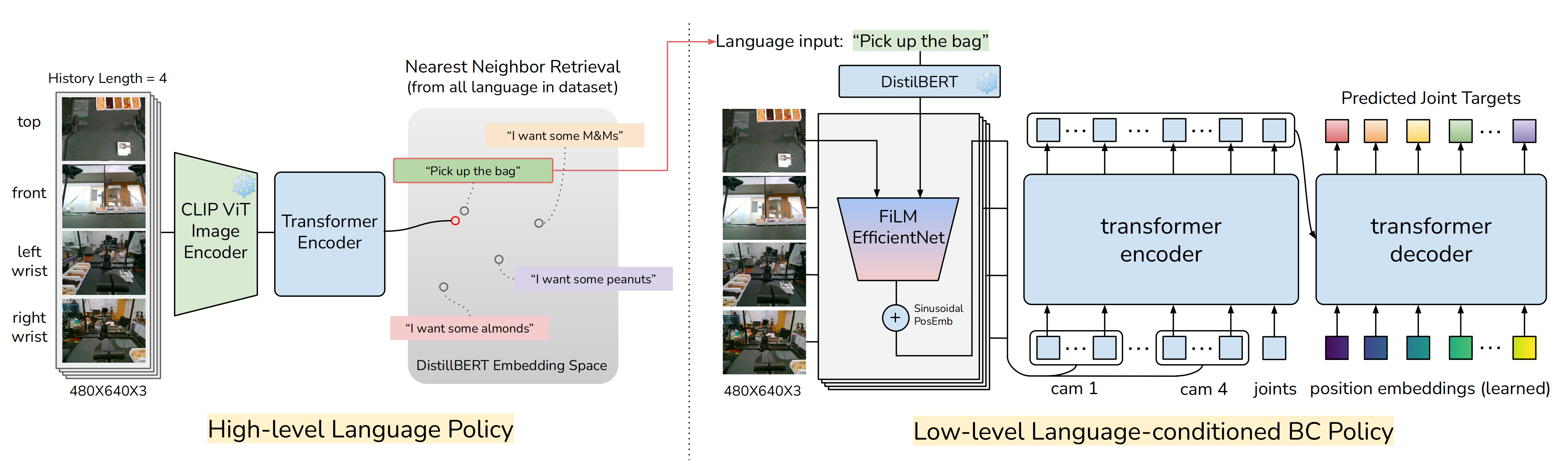
- 对于视觉处理,作者使用EfficientNet b3 [60-Efficientnet: Rethinkingmodel scaling for convolutional neural networks,hf地址:efficientnet-b3]作为视觉骨干网来编码从每个摄像头捕获的RGB图像
- 在原始的ACT模型中,图像特征与机器人的本体感知状态信息连接在一起,作为策略的输入
为了额外基于语言进行条件化,作者通过引入FiLM [49-Film: Visual reasoningwith a general conditioning layer]层来修改ACT,以融合视觉和语言输入,类似于RT-1 [8] - 且使用DistilBERT [53-DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter]对数据集中的语言指令进行编码
对于高级策略,如上图左侧所示,其自主生成语言命令。该策略基于视觉骨干网络,使用视觉Transformer(ViT)[16],并以预训练的CLIP [50]权重初始化。这些权重在整个训练过程中保持冻结状态
- 视觉特征随后通过额外的Transformer [64]和MLP层进行处理,以生成语言编码。对于真实编码,作者利用DistilBERT [53]来处理数据集中的语言指令
- 为了考虑时间上下文,模型采用正弦位置嵌入。这些嵌入应用于每个时间步每个摄像机的历史观测序列。在选择历史观测时,如果控制频率很高,前一个图像与当前帧的相似度很高。作者选择每隔一秒的多达四张图像,而不是紧接前的图像,以提供更广泛的时间上下文
- 在训练过程中,输出语言嵌入与数据集中现有的语言命令进行余弦相似度比较。此比较产生对数几率,然后使用带有学习温度参数的交叉熵损失进行评估[47]
为了鼓励模型预测即将到来的指令而不是当前指令,我们将目标预测偏移一个小幅度,以增加模型在接近当前技能段结束时预测下一个指令的可能性。在推理时,选择最可能的语言命令作为高层策略输出
1.3.3 后训练阶段
在后训练阶段,高级策略会在固定的间隔下被查询,具体来说是每4秒作为平均技能长度,以生成机器人语言指令
- 为了便于实时的人类反馈,在机器人附近放置了一个麦克风,用于捕捉用户的口头指令。如果用户希望干预,可以通过简单的命令如“停止”(或更礼貌的选项如“请稍等”)来口头指示机器人停止
- 在此中断之后,用户可以提供口头纠正来引导机器人。为了持续改进高级策略,我们记录了用户提供的口头纠正以及相应的观察
此外,考虑到人类的反应时间,系统还会保存干预前2秒的数据以获取更多上下文。这些数据随后用于微调高级策略,具体细节在第III-E节中详细说明。数据的详细信息,包括基础数据集和后训练数据集,见原论文的附录VI-A
// 待更
第二部分 EfficientNet与FiLM
2.1 EfficientNet:CNN在网络宽度、深度、分辨率三个维度上的扩展
在不同资源限制下有很多方法可以扩展卷积神经网络(ConvNet):
- 通过调整网络深度(层数),ResNet(He等人,2016)可以缩小(例如,ResNet-18)或放大(例如,ResNet-200);
- 而WideResNet(Zagoruyko & Komodakis,2016)和MobileNets(Howard等人,2017)可以通过网络宽度(通道数)进行扩展
- 众所周知,较大的输入图像尺寸会提高准确性,但需要更多的浮点运算。尽管先前的研究(Raghu等人,2017;Lin & Jegelka,2018;Sharir & Shashua,2018;Lu等人,2018)表明网络深度和宽度对卷积神经网络的表现力都很重要,但如何有效地扩展卷积神经网络以实现更好的效率和准确性仍然是一个未解决的问题
Google Research的EfficientNet则系统地和实证地研究了卷积神经网络在网络宽度、深度和分辨率这三个维度上的扩展
// 待更
2.2 FiLM:针对任意输入自适应地控制神经网络的输出
FiLMl层对神经网络的中间特征进行简单的、基于特征的仿射变换——以任意输入为条件「换言之,通过对网络的中间特征进行仿射变换:FiLM,从而根据某些输入自适应地影响神经网络的输出」
- 在视觉推理的情况下,FiLM层使得循环神经网络(RNN)可以通过输入问题来影响卷积神经网络(CNN)对图像的计算。这个过程根据输入问题自适应地、根本性地改变了CNN的行为,使得整个模型能够执行各种推理任务,例如从计数到比较
- FiLM可以被视为条件归一化的推广,后者在图像风格化(Dumoulin, Shlens, 和 Kudlur 2017; Ghiasi 等2017; Huang 和 Belongie 2017)、语音识别(Kim, Song, 和 Bengio 2017)和视觉问答(deVries 等 2017)方面已被证明非常成功,展示了FiLM的广泛适用性
2.2.1 特征线性调制(Feature-wise Linear Modulation)
更正式地说,FiLM学习函数和
——
和
可以是任意函数 如神经网络,它们基于输入
,输出
和
其中,和
通过特征逐点仿射变换调节神经网络的激活
,下标指的是第
个输入的第
个特征或特征图「where γi,c and βi,c modulate a neural network’s activations Fi,c, whose subscripts refer to the ith input’s cth feature or feature map, via a feature-wise affine transformation」
目标神经网络处理的调制可以基于该神经网络的相同输入或其他输入,如在多模态或条件任务中一样
- 对于CNN,
和
可以基于
对每个per-feature-map的激活分布进行调节,而不考虑空间位置
For CNNs, f and h thus modulate the per-feature-map distribution of activations based on xi, agnostic to spatial location. - 在实践中,将
向量的单一函数更为简单,因为例如,通常在
由此,称这个单一函数为FiLM生成器,且还可以称应用FiLM层的网络为特征线性调制网络,即FiLM-ed网络
- FiLM层使得FiLM生成器能够通过放大或缩小、取反、关闭、选择性阈值化(当后接ReLU时)等方式来操控目标FiLM-ed网络的特征图
- 且每个特征图都是独立调整的,这使得FiLM生成器能够在每个FiLM层上对激活进行中等细粒度的控制。由于FiLM每个调制特征图仅需要两个参数,它是一种可扩展且计算高效的调节方法。特别是,FiLM的计算成本与图像分辨率无关
// 待更
2.2.2 模型
FiLM 模型由一个FiLM 生成语言管道和一个FiLM 视觉管道组成,其中,FiLM 生成器使用门控循环单元GRU网络(Chung 等,2014)处理问题,该网络具有4096 个隐藏单元,输入为学习到的200 维词嵌入。最终的GRU 隐藏状态是一个问题嵌入,模型从中通过仿射投影预测每个第
个残差块的
具体而言,如下图图3 所示
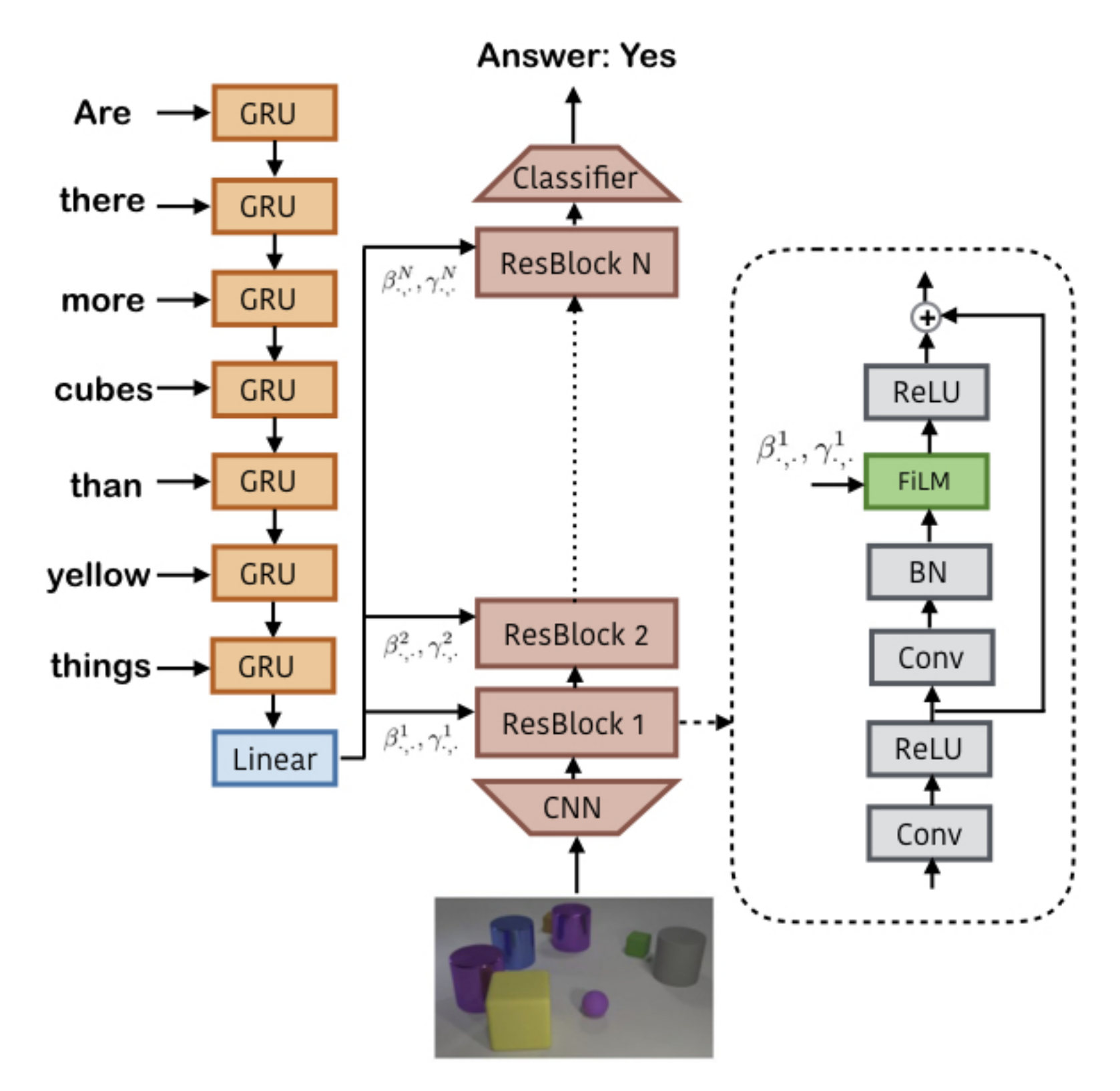
- 视觉管道从一个调整大小为224 × 224 的图像输入中提取12814 × 14 图像特征图,这可以通过从头开始训练的CNN 或固定的、预训练的特征提取器与一个学习的3 × 3 卷积层来实现。从头开始训练的CNN 由4 层组成,每层有128 个4 × 4 卷积核,ReLU 激活和批量归一化,类似于之前在CLEVR 上的工作(Santoro 等,2017)
- 固定特征提取器输出在ImageNet 上预训练的ResNet-101(He 等,2016)的conv4 层,以匹配之前在CLEVR 上的工作(Johnson 等,2017a; 2017b)。图像特征通过多个(在我们的模型中为4 个)——FiLM-ed残差块(ResBlocks)与128 个特征图和一个最终分类器进行处理
- 分类器由1 × 1卷积到512个特征映射、全局最大池和一个具有1024个隐藏单元的两层MLP组成,最后输出答案的softmax 分布
此外,对于每个FiLM-ed ResBlock以一个1×1卷积开始,接着是一个3×3卷积,其架构如下图所示
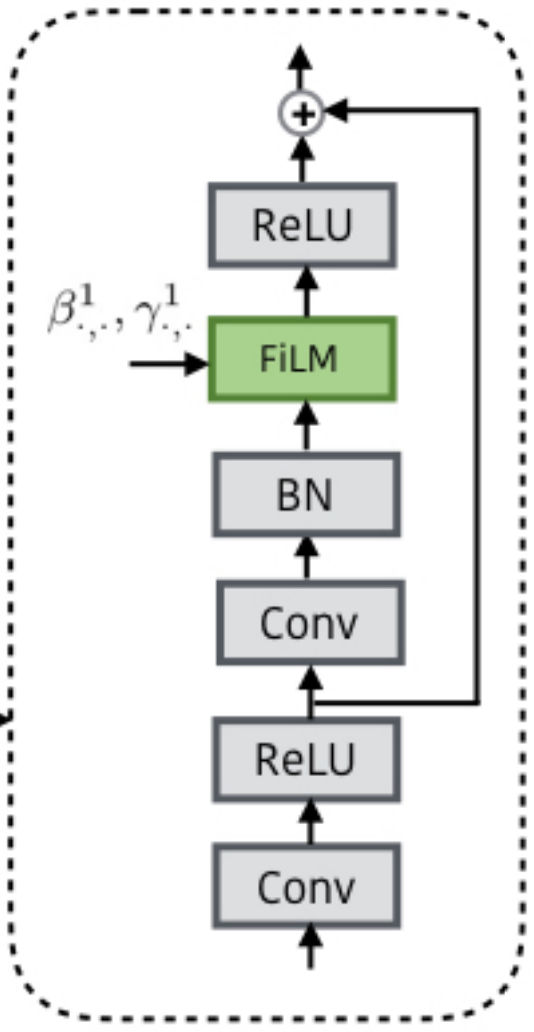
作者关闭了在FiLM层之前的批量归一化层的参数。借鉴之前在CLEVR(Hu et al. 2017; Santoro et al. 2017)和视觉推理(Watters et al. 2017)上的工作,作者将两个表示相对和
空间位置(从-1到1缩放)的坐标特征图与图像特征、每个ResBlock的输入和分类器的输入连接在一起,以促进空间推理
作者从头开始端到端训练模型
// 待更


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











