




1、adam优化器公式
包括动量项和过去梯度平方的指数衰减平均
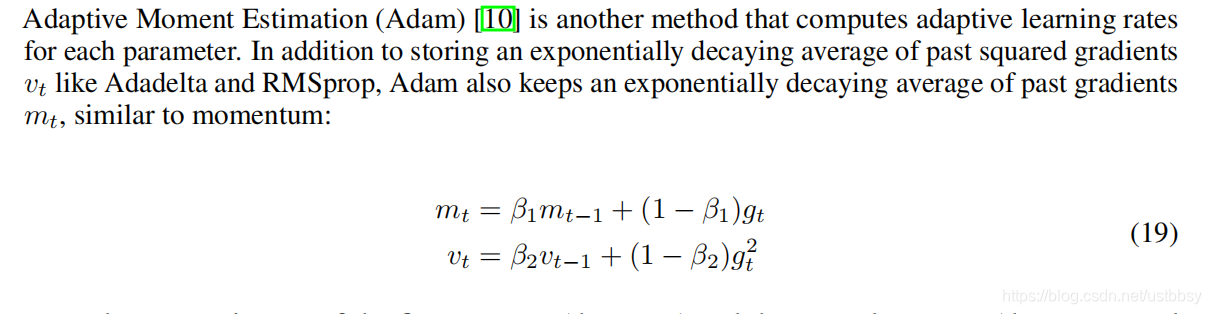
2、偏差校正后的,
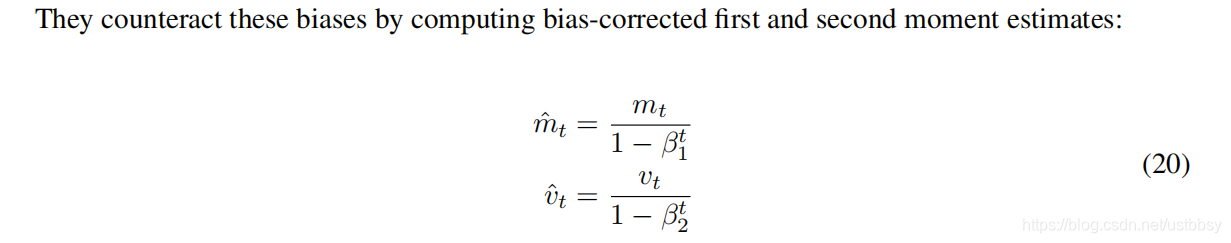
3、Adam的参数更新公式
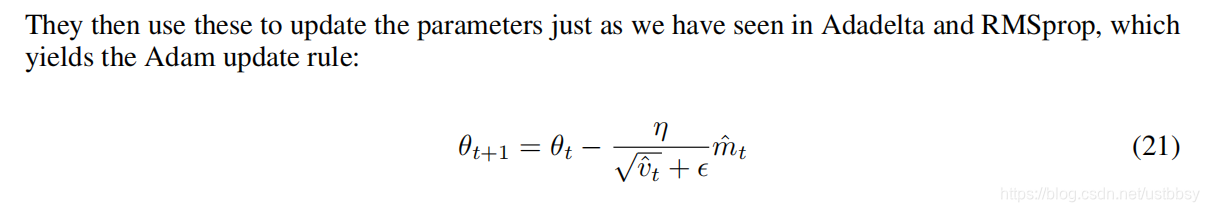
重点来了
第二部偏差矫正的公式是怎么等到的???
论文中的推导


但是不知道是怎么变化来的,下面是我的理解
第一次迭代
初始化为0,则
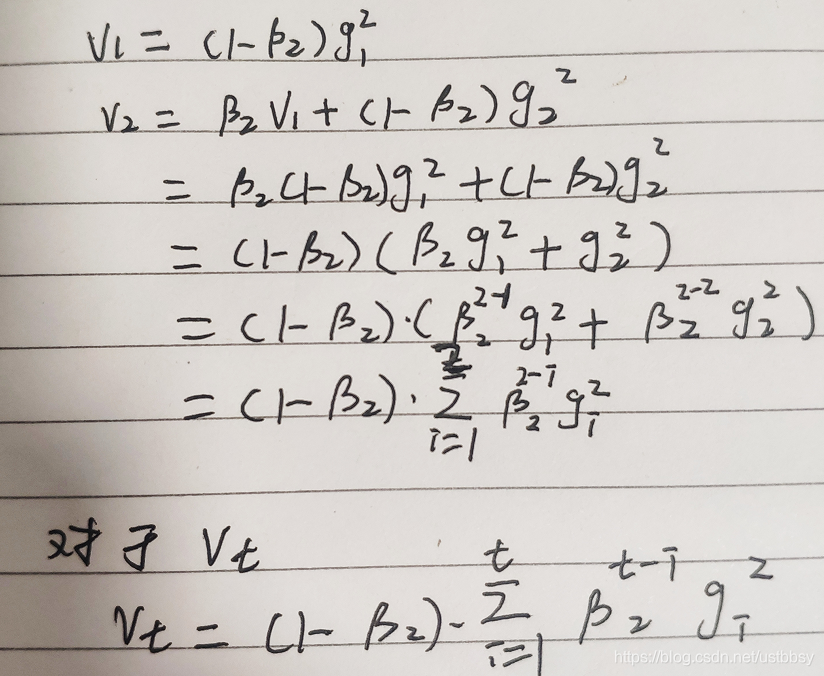
对上式左右求期望
这里对vt展开了,直接套用期望的性质,那个没有搞懂。。。
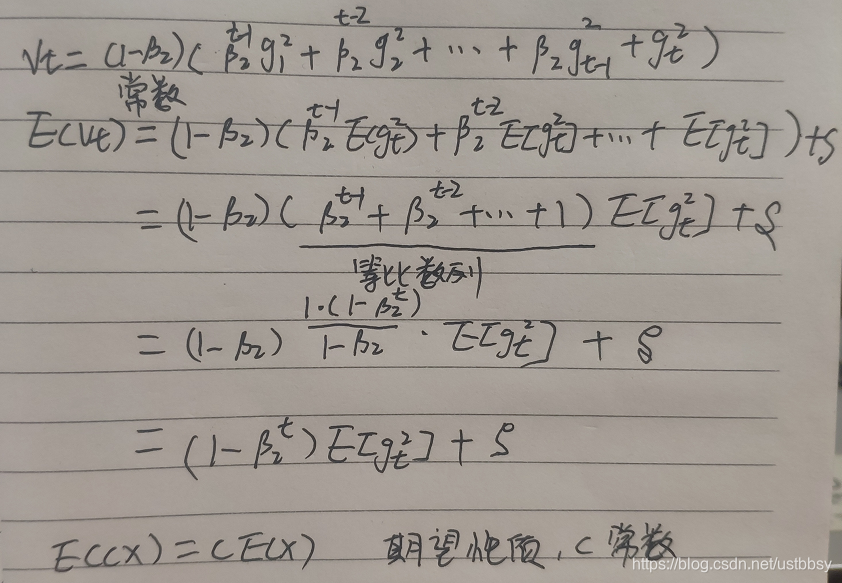
这样就推出来那个公式了
 本文探讨了Adam优化器的偏差矫正原理,详细解析了优化器的公式,特别是偏差校正部分。通过分析论文中的推导过程,解释了在第一次迭代时如何从初始状态推导出偏差矫正的公式,并对相关数学操作进行了说明。
本文探讨了Adam优化器的偏差矫正原理,详细解析了优化器的公式,特别是偏差校正部分。通过分析论文中的推导过程,解释了在第一次迭代时如何从初始状态推导出偏差矫正的公式,并对相关数学操作进行了说明。
1、adam优化器公式
包括动量项和过去梯度平方的指数衰减平均
2、偏差校正后的,
3、Adam的参数更新公式
第二部偏差矫正的公式是怎么等到的???
论文中的推导
但是不知道是怎么变化来的,下面是我的理解
第一次迭代
初始化为0,则
对上式左右求期望
这里对vt展开了,直接套用期望的性质,那个没有搞懂。。。
这样就推出来那个公式了
 3785
717
3785
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























