



摘要
This week, I learned the concept of CNN and its common applications, and studied what CNN is and the general process of CNN from two angles. In addition, I also studied the reasons why there will be overfitting when using validation set and why deep learning goes deep rather than horizontally. Finally, the concept and common practices of Spatial Transformer are understood.
本周学习了CNN的概念及其常见应用,从两个角度来研究什么是CNN以及CNN的大致过程,此外还研究了使用validation set还会出现overfitting以及深度学习之所以往深的方向而不往横向发展的原因。最后了解了Spatial Transformer的概念和常见做法。
卷积神经网络-CNN(常用于影像)
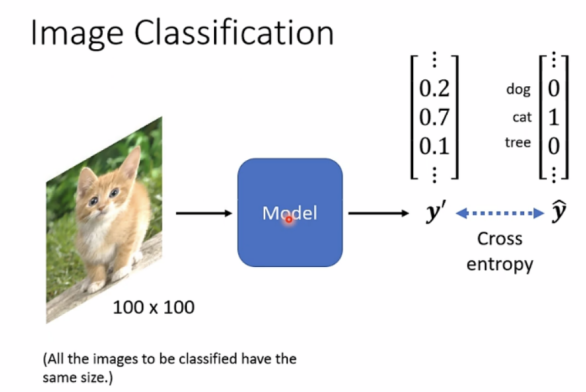
Image classification
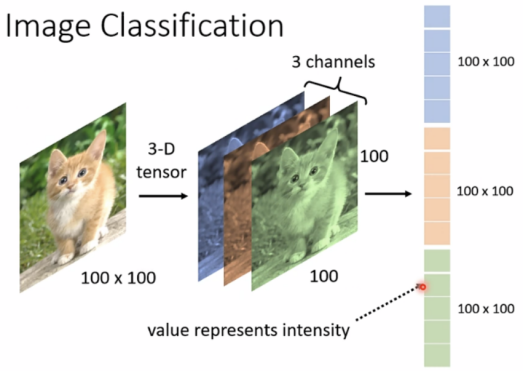
注:tensor理解为维度大于2的矩阵
图片在计算机解析为3-D tensor(三维向量),包括长宽和3 channels(rgb格式)
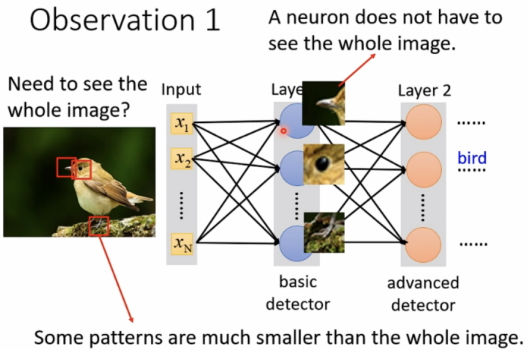
影像识别不需要使用fully connected
Observation 1
identifying some critical patterns(不必看整张图片)
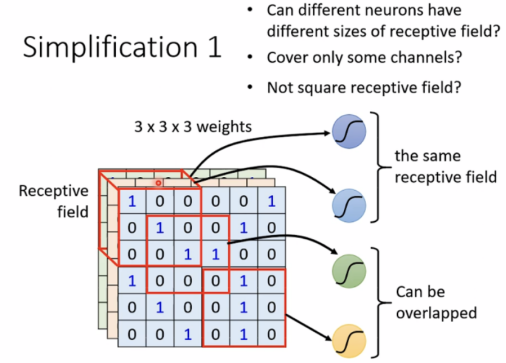
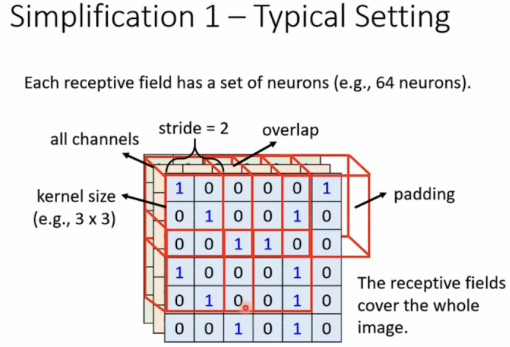
Simplification 1
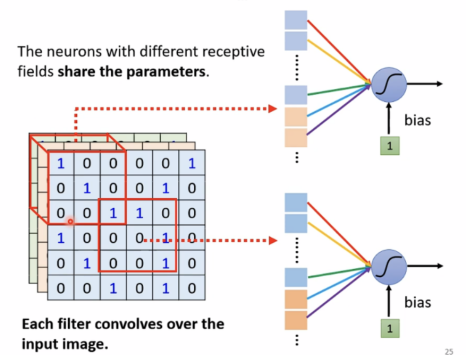
使用receptive field,can be overlapped,and different neurals can have the same field
(可任意设计field形状)
Typical Setting
交界处neural侦测不到,故stride一般较小,多个receptive field需要有重叠(overlap),移动时超过image部分进行padding(补值),padding有多种方法,例如全补0或是补最后一列。
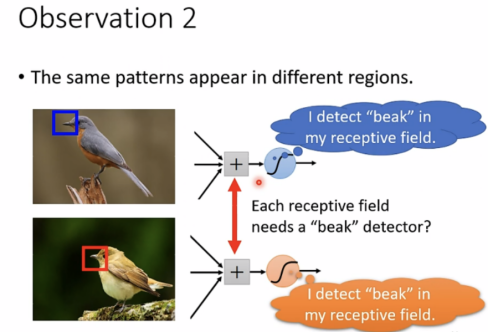
Observation 2
相同特征出现在不同区域
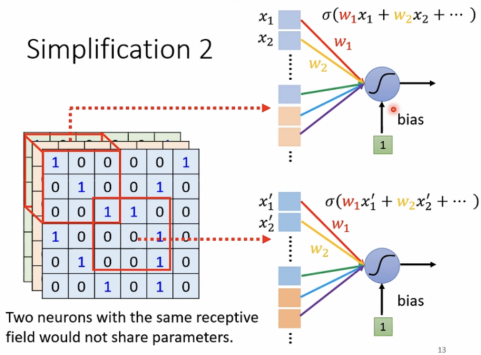
Simplification 2
共享参数 parameter sharing
有相同receptive field的neural不可以共享参数。
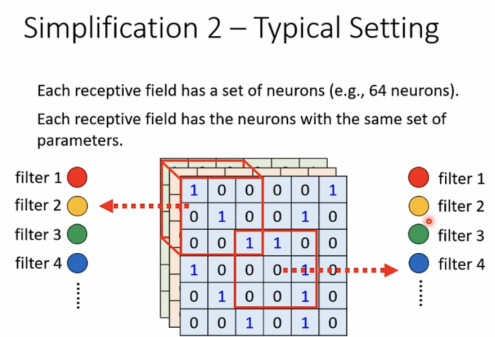
Typical setting
使用filter来共享参数。
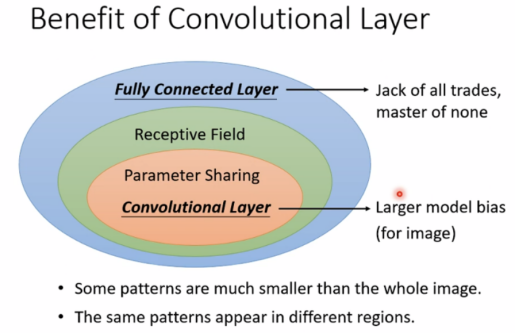
Benefit of Convolutional Layer
Convolutional Layer = Receptive + Parameter Sharing,具有较大的model bias。
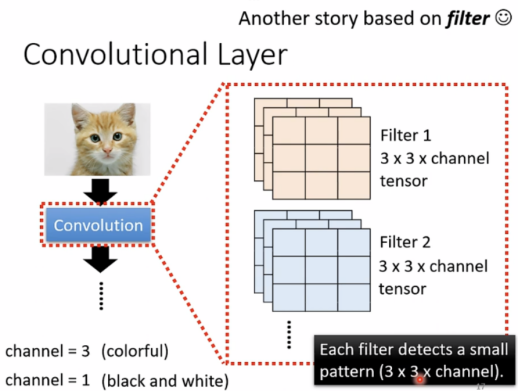
如果从filter角度出发来理解何为Convolution,通过filter形成feature map,像是一张有64个channels的新“image”(忽略了filter的bias)。
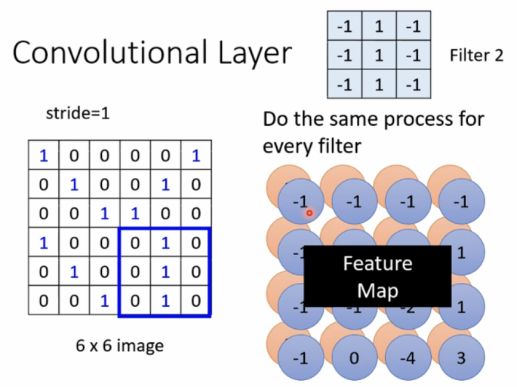
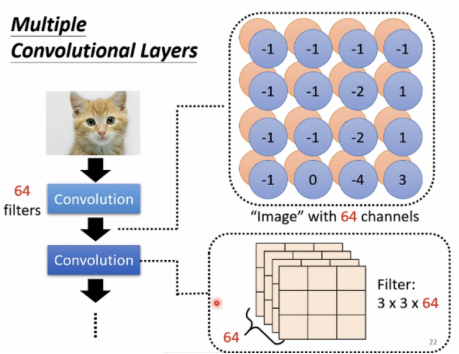
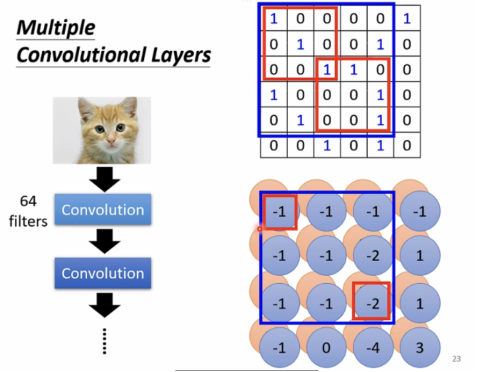
对比两个版本的解释,可以看出,Receptive field中的共享参数就是filters。

Observation 3
缩小图片不会改变object
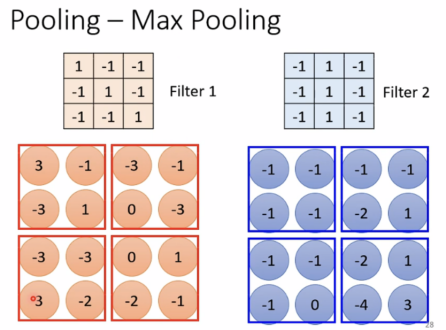
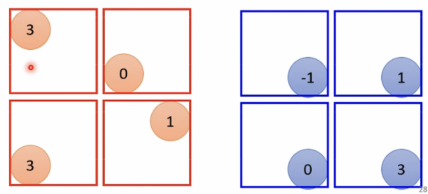
Pooling-Max Pooling(减少运算量)
The whole CNN(如今运算能力越来越强,有时可以不用pooling)
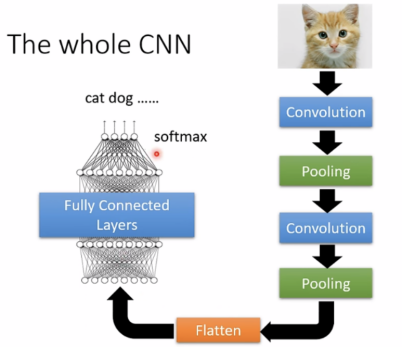
CNN application: Playing GO
将围棋棋盘当成1919的matrix(image),这是个1919的classes问题,在AlphaGo中,有48个channels。CNN表现比fully-connected network要好很多。
围棋与影像的共同之处:

阿尔法狗并未使用pooling。
CNN新应用包括:语音、文字处理等等。
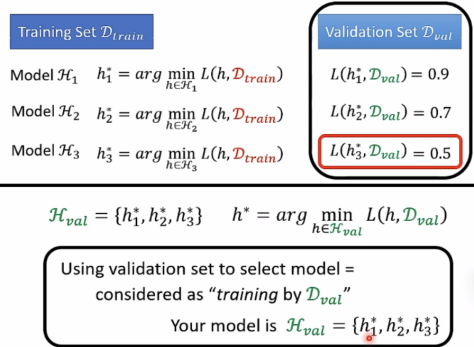
为什么用validation set还是会有overfitting
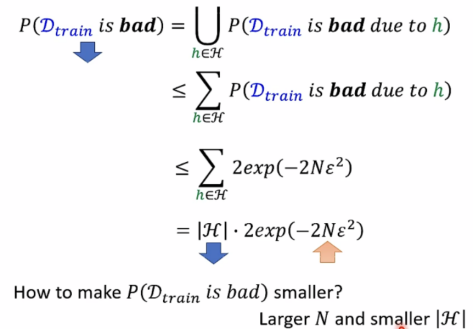
D test近似D all,validation也可当成“training”当validation过程中可选择的H过多时,就会出现overfitting。

注:Probability of D train is bad
为什么选择深度学习
Review: why hidden layers
使用piecewise linear (sigmoid或relu)
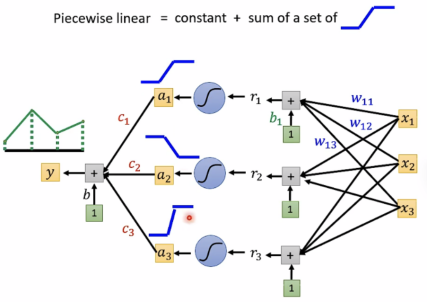
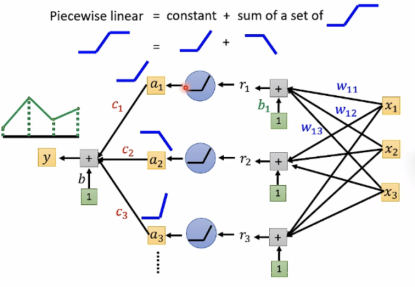
深度学习好的一个原因: 大模型+大量训练资料
对比Fat+short 和 Thin+Tall:
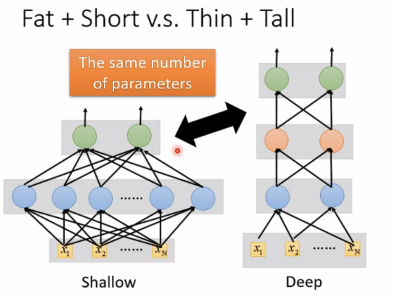
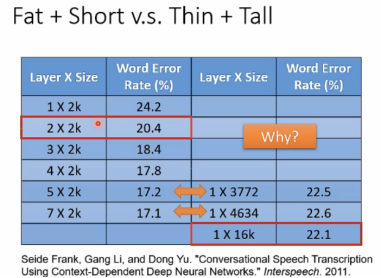
由实验结果可知,deep更好。同样的function使用deep需要的参数更少,不容易出现overfitting。
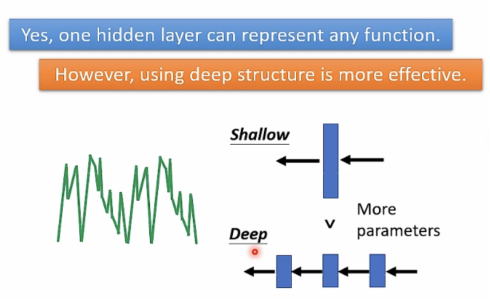
以下是一个剪纸的例子来类比一下deep的好处:
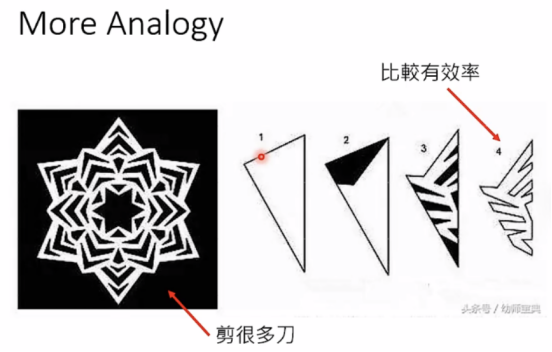
使用relu:
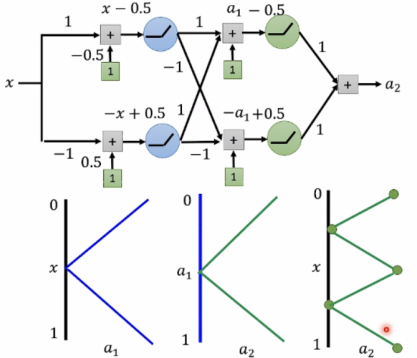
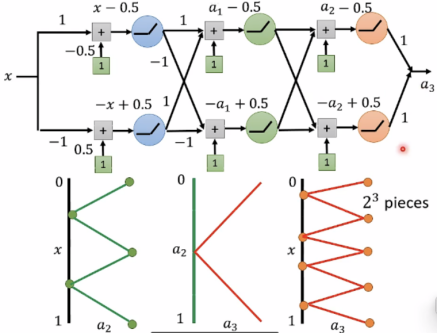
由以上可知,
Deep如果需2^k pieces,只需要k layers(2k neurons),具有small |H|.
Shallow 如果需2^k pieces,则需要2^k个neurons,具有large |H|.
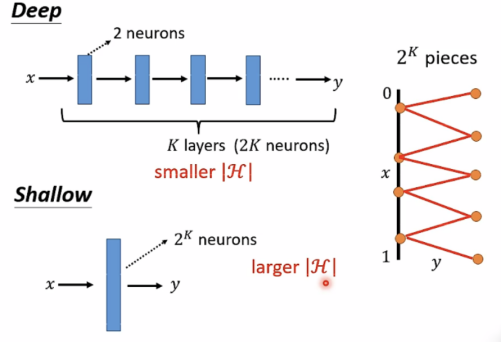
Conclusion:
Deep networks比shallow ones表现更好,当函数是复杂的、有规律的。例如:image、speech等等。
Deep performs better than shallow even when y=x²。

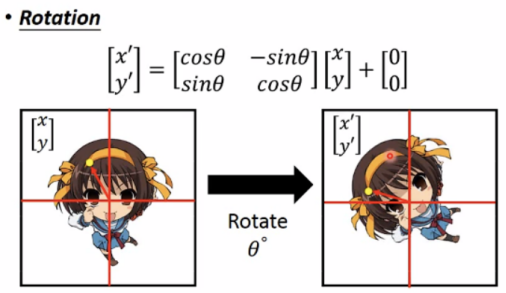
Spatial Transformer(空间转换器)
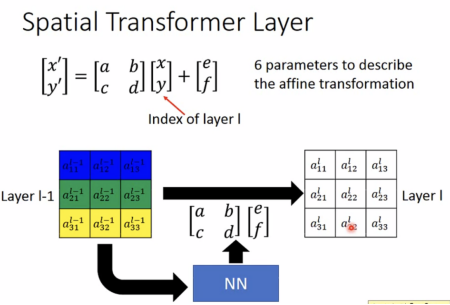
Spatial transformer layer(也是NN layer)
CNN is not invariant to scaling(改变大小)和rotation(旋转)
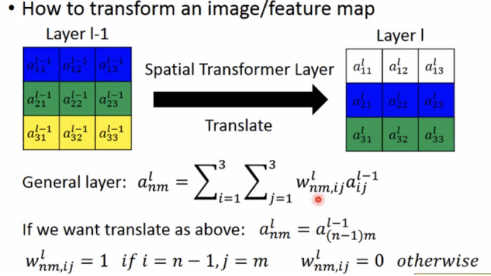
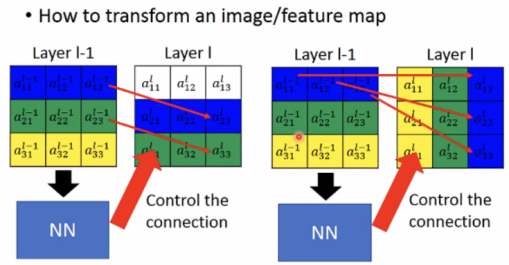
transform an image/feature map
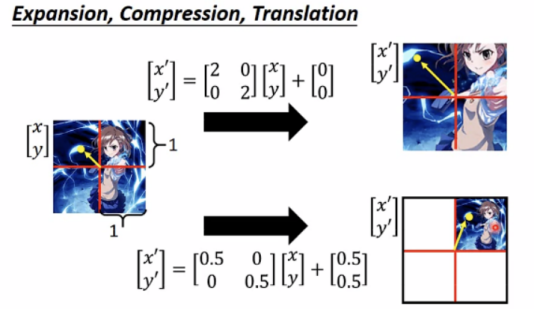
Expansion、Compression、Translation:
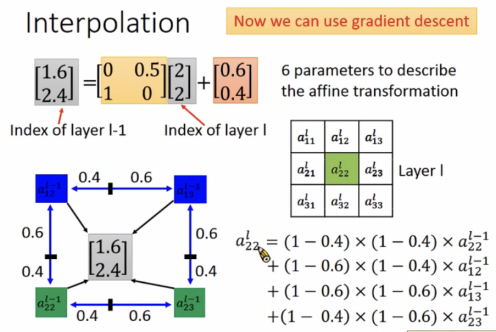
Interpolation(插值)
总结
本周主要学习了CNN卷积神经网络的概念,并了解了CNN的一些应用,使用了许多线性代数矩阵等方面的知识,下周将继续学习自注意力机制,了解RNN、GNN等概念。

















 857
857




 到【灌水乐园】发言
到【灌水乐园】发言







