




 有限马尔科夫决策过程(Finite Markov Decision Process, FMDP)是一种决策理论模型,用于描述智能体在环境中如何通过观察状态、选择行动、获取奖励来学习最优策略。该过程涉及贝尔曼方程,用以计算不同策略下的价值函数。然而,实际中可能面临环境动态未知、状态过多无法穷举等问题。最优策略是指在长期中最大化总奖励的策略,满足特定的贝尔曼等式。寻找并实现这样的最优策略是强化学习的核心挑战。
有限马尔科夫决策过程(Finite Markov Decision Process, FMDP)是一种决策理论模型,用于描述智能体在环境中如何通过观察状态、选择行动、获取奖励来学习最优策略。该过程涉及贝尔曼方程,用以计算不同策略下的价值函数。然而,实际中可能面临环境动态未知、状态过多无法穷举等问题。最优策略是指在长期中最大化总奖励的策略,满足特定的贝尔曼等式。寻找并实现这样的最优策略是强化学习的核心挑战。
目录
Finite Markov Decision Process
RL an introduction link:
Sutton & Barto Book: Reinforcement Learning: AnIntroduction
Finite Markov Decision Process
Definition
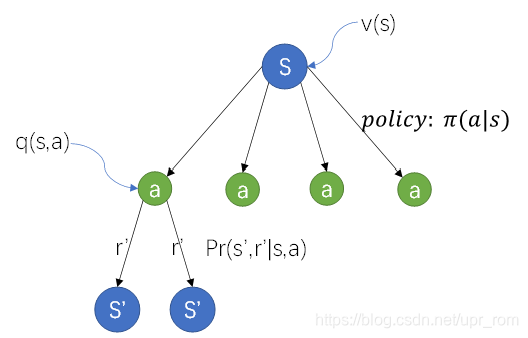
The ego (agent) monitors the situations from the environment, such as by data flow or sensors (cameras, lidars or others), which is called state in the view of term. We have to highlight that we presume the agent clearly know enough information of the situations all the time, by which the agent could make their decisions. So we have at the time step of t.
After the agent knows the current state, it could have finite actions to choose ( ). And after taking an action, the agent will obtain the reward in this step (
) and run into the next state (
), in which process, the agent could know the environment's dynamics (
).Then the agent will continue deal with this state until this scenario ends.
The environment's dynamics are not decided by people, but the policy of taking which action depends on the agent's jugement. In every state ,we could choose actions, which gives us more rewards totally not just in the short run, but also in the long run. Therefore, the policy of choosing actions in state is the core of reinforcement learning. we use
to describe the probability of each action taken in the current state.
Therefore, the Finite Markov Decision Process is the process,in which the agent know the current state ,actions that is about to choose, even the probability of and
for each action (
) and obtain the expected return in different policy.
Formula( Bellman equation )
Mathematically, we could calculate the value function .
Consideration
For every scenario, we know the dynamics of the environment , the state set
and coresponding action set
. For evey policy we set, we know
. So we could obtain N equations for
.
Limitation
- Many times, we could not know the dynamics of the environment.
- Many times, such as gammon, there are too many states. So we have no capacity to compute this probelm in this way ( solve equations )
- problems have Markov property, which means
and
only depend on r and a. In other words, r and a could get all possible
Optimal policies
Definition
For policy and policy
, if for each state s, the ineuqation can be fulfilled:
then we can say is better than
.
Therefore, there must be more than one policy, that is the optimal policy .
At the meantime, every state in policy also will meet Bellman equation.
Optimal Bellman equation
for in the total policy set:
For a specific case, the environment's dynamic is constant. We can only change the apportionment of .
For a maximum v(s), we should apportion 1 to the max q(s,a).
Therefore, the optimal policy is actually a greedy policy without any exploration.

















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









