




论文题目:《HPCC: High Precision Congestion Control》高精度拥塞控制。
这篇论文是阿里巴巴提出的一种针对 RDMA 网络的新的拥塞控协议,论文在 2019 年发表在会议 ACM SIGCOMM 上。
论文主要讲的是:首先分析了现有高性能网络中拥塞算法的不足,然后提出一种高性能网络下的高精度拥塞控制算法,详细介绍了算法的设计和实现,并通过实验验证该算法的效果比其他算法效果好。
背景
RDMA 网络中的 CC 机制,如 DCQCN 和 TIMELY ,有一些局限性:
- 收敛慢。对于粗粒度反馈信号(如 ECN 或 RTT ),当前的 CC 方案不知道增加或减少多少发送速率,因此它们使用启发式来猜测速率更新,并尝试迭代收敛到稳定的速率分布。这种迭代方法处理大规模拥塞事件的速度很慢,比如在 PFC Storm 的时候。
- 不可避免的数据包排队。网络流量过大时,数据包会被迫在交换机或路由器的缓冲区中排队,等待处理,这种排队会导致延迟,影响网络性能。DCQCN 和 TIMELY 都是在队列建立后,发送方才开始降低流量。此时数据包已经在网络中排队,这些队列会显著增加网络延迟。比如网卡带宽非常高的时候。
- DCQCN 发送方利用一个 bit 的 ECN 标记来判断拥塞风险,接收方接收到 CNP 后会给发送方返回 CNP 。发送方只有在队列已经建立后才做出反应。
- TIMELY 是通过监测往返时延 RTT 的增加来检测拥塞。同样,发送方也是在队列已经建立后才做出反应。
- 复杂的参数调整。当前 CC 算法有许多参数需要针对特定网络环境进行调整。例如,DCQCN 需要设置 15 个参数。复杂而耗时的参数调整阶段,大大增加了设置错误的风险。
这三个限制的根本原因是传统网络中缺少细粒度的网络负载信息(ECN是终端主机可以从交换机获得的唯一反馈,RTT 是一种纯端到端的测量,没有交换机的参与)。
需要一种新的 CC 策略,新的 CC 策略应同时具备以下特性:
- 快速收敛。网络可以快速收敛到高利用率或避免拥塞。
- 接近空队列。网络内缓冲区的队列大小保持稳定的低,接近于零。
- 参数很少。CC 不应该依赖于需要操作员调整大量参数,相反,它应该适应网络和流量模式本身,以便降低操作复杂性。
- 公平。CC 应该保证流之间的公平性。
- 易于在硬件上部署。CC 算法应该非常简单,易于在 NIC 上或交换机硬件上实现。
INT:In-Network Telemetry ,是一种网络内遥测技术,主要用于收集和传输网络中各个节点(如交换机)上的实时性能数据。INT 可以被视为一种硬件功能,因为它通常依赖于现代交换机的ASIC(应用特定集成电路)来实现。INT 是一种硬件特性,通常与现代网络设备的设计和实现紧密相关,旨在提高网络性能和拥塞控制的精确性。
INT 的主要作用是允许网络设备在数据包传输过程中插入元数据,这些元数据可以包括链路负载、队列长度、传输字节和带宽容量等信息。这些信息随后可以被发送方在接收到 ACK 消息时使用,以便进行流量控制和拥塞管理。
基于 INT 功能,论文提出了一种新的 CC 机制,HPCC(高精度拥塞控制)。HPCC 能够解决上面提到的三个限制,并且具备以上几种特性。
HPCC 为什么能解决上述问题,是如何解决的,效果如何
HPCC 背后的关键思想是利用来自 INT 的精确链路负载信息来计算准确的流量更新。
使用 INT 提供的精确信息使 HPCC 能够解决上面提到的三个限制:
- 解决收敛慢的问题:现有 CC 通常需要多次速率更新才能找到合适的流速,但是 HPCC 大多数情况下只需要进行一次流速更新。HPCC 发送端可以快速提高流量以实现高利用率,或降低流量以避免拥塞。
- 解决数据包排队的问题:HPCC 发送方可以快速调整流量,使每条链路的输入速率略低于链路的容量,从而防止队列的建立,并保持较高的链路利用率。
- 解决参数调整复杂的问题:由于发送速率是根据交换机上的直接测量值精确计算的,因此 HPCC 只需要 3 个独立的参数来调整公平性和效率。
HPCC 满足了在大规模网络中同时实现超低延迟,高带宽和高稳定性的目标。HPCC 还具有:
- 部署容易。它只需要交换机中的标准 INT 功能,并且易于在 NIC 硬件中实现。
- 公平。HPCC 能够在保持高效利用网络资源的同时,确保不同流之间的公平性。
- HPCC 使用乘法增加/减少的策略来快速收敛每个链路的速率,当网络条件变化时,流量能迅速适应,保持高效和稳定的网络性能。
- 对于长流(持续时间较长的数据传输),HPCC 采用加法增加的策略来逐步提高流速,使得带宽增加的更加平滑,避免了因过快增加速率而导致网络拥塞。
与 DCQCN、TIMELY 相比,HPCC 对可用带宽和拥塞的反应更快,并保持接近零的队列。与 DCQCN 相比,p99 延迟减少了 95% 。在 incast 测试中,使用 DCQCN 和 TIMELY 会频繁发生 PFC Storm ,但是 HPCC 也不会触发 PFC pause 。
HPCC 设计
基于 INT 设计 HPCC 有两个挑战:
- 延迟反馈容忍。链路拥塞会延迟数据包上承载的 INT 信息到达,从而延迟流量降低,延迟解决拥塞。HPCC 旨在限制和控制链路中的 total inflight bytes(已发送但尚未被确认的数据),防止发送方发送过多流量。当网络发生拥塞时,ACK 可能会因为拥塞而延迟到达发送方。如果发送方在等待 ACK 的同时继续发送数据,可能会引发更严重的拥塞问题。HPCC 通过限制 inflight bytes 的数量,确保发送方在网络繁忙时不会发送过多的数据,即使 ACK 尚未接收到。
- 过度反应。尽管所有 ACK 数据包中都包含 INT 信息,但如果发送方盲目地对所有信息做出快速反应,则可能会出现破坏性的过度反应。HPCC 通过综合考虑 ACK 和 RTT 来选择性的使用 INT 信息,实现快速反应而不至于过度反应。
HPCC 框架
HPCC 框架如下:
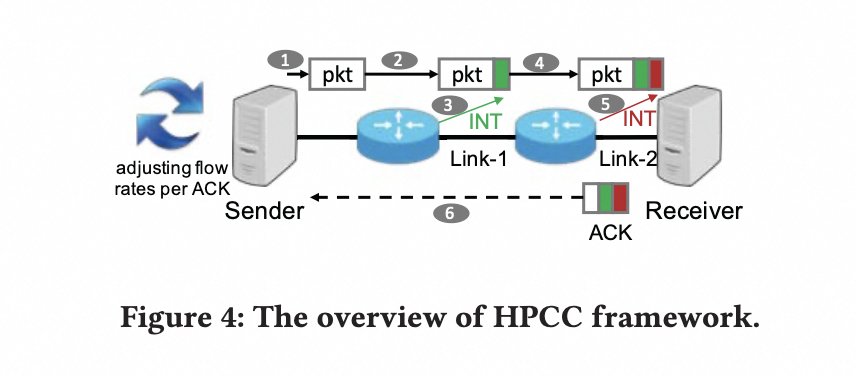
HPCC 是一个发送方驱动的 CC 框架,如上图所示,Sender 的每个数据包都会得到 Receiver 的确认。
整体流程是:
- 发送方向接受方发送数据包时,沿途的每个交换机利用其 ASIC 的 INT 特性来插入一些元数据,这些元数据是包的出口端口的当前负载,包括时间戳(ts)、队列长度(qLen)、传输字节(txBytes)和链路带宽容量(B)。
- 接收方收到数据包时,将交换机记录的所有元数据复制到 ACK 包中并发送给发送端。
- 发送方收到带有网络负载信息的 ACK 后,基于这些元数据决定何时调整发送速率。
HPCC CC 算法
基于 inflight 的 CC
HPCC 是一种基于窗口的 CC 方案,使用窗口控制 inflight 字节数(已发送但尚未确认的数据量)。
为什么用 inflight bytes 控制而不用 rate 控制?
inflight 字节数对应于链路利用率。当拥塞未发生时,inflight 字节数和速率的关系是:inflight = rate * T(其中 T 是 base RTT ),控制 inflight 与控制 rate 等价。但是当拥塞发生时,基于 rate 调整的话,在反馈(ACK)返回前发送方仍然以原速率发送,可能会导致拥塞加剧,网络不稳定。但基于 inflight 的话,对 inflight 字节数的控制可以确保 inflight 字节数在限制范围内,使得发送方在达到限制时立即停止发送,无论 ACK 延迟了多长时间。因此,整个网络非常稳定。
发送方通过发送窗口限制 inflight 字节数。每个发送方都维护一个发送窗口,该窗口限制其可以发送的 inflight 字节数。初始发送窗口大小:Winit = Binc * T,其中 Binc是 NIC 带宽。
带宽时延积 BDP(Bandwidth-Delay Product),是一个网络性能参数,表示在网络路径中以最大速率传输的同时,处于传输状态的数据量。BDP 是用来衡量网络链路上在没有拥塞的情况下能够容纳的数据量。
BDP = 带宽(bps) * 时延(s)。
对于一个链路,inflight 字节是所有通过它的流的总 inflight 字节,用 I表示:
当 I < B * T时,说明当前链路中的数据没有填满链路带宽,此时链路未被充分利用,即还没有发生拥塞。
当 I >= B * T时,总吞吐量将超过链路带宽,即发生拥塞。
因此,目标就是控制每个链路的 I略小于 B * T,这样就不会出现拥塞和队列。
如何计算每个链路的 I?
inflight 字节由队列和链路中的数据包组成:

因此,对于每个链路 j,其 inflight 字节为:
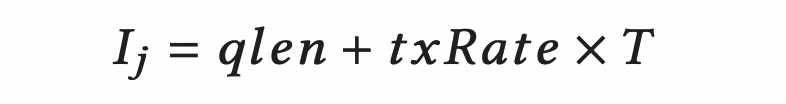
其中 qlen是队列长度,txRate是输出速率,T表示 base RTT( T 是已知的,在数据中心网路中,大多数服务器之间的 RTT 非常接近)。
qlen可以从 INT 中获得,txRate由 txBytes和 ts计算(这两个值也是从 INT 获得的):
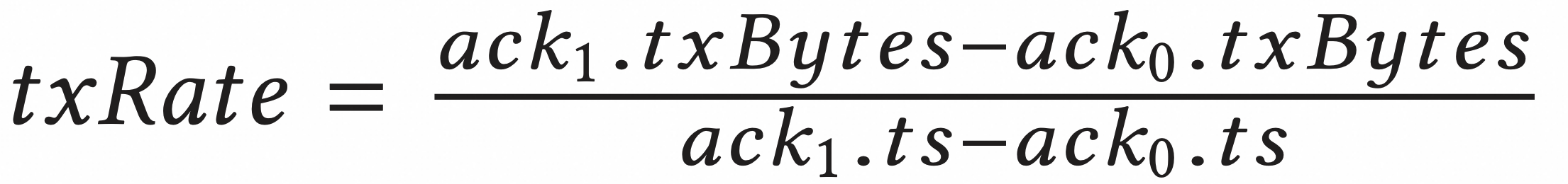
其中 ack0和 ack1是两个 ACK 。
每个发送端应调整窗口,使得其流路径上每个链路的 Ij略低于 Bj * T,实际上为 η * Bj * T(η 是接近 1 的常数,一般是 95% )。
因此对于每一个链路 j ,发送方都会通过参数 Kj 来对发送窗口进行调整:
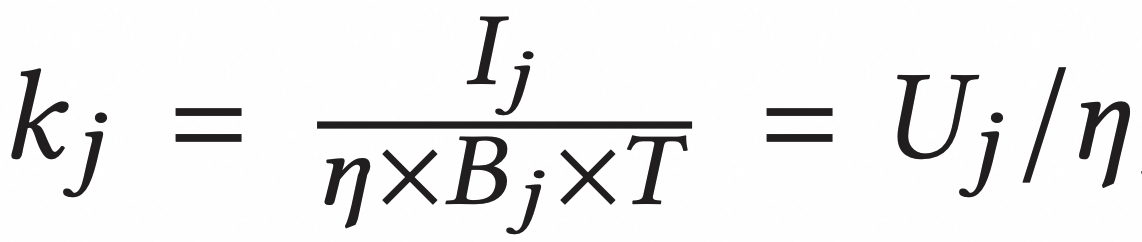
目标就是使 上述分子几乎等于分母(即
k = 1),这样带宽利用率最高,网络也没有拥塞。如果分子小于分母(即k < 1),说明网络尚未出现拥塞,发送端可以继续增加发送窗口;否则说明网络已经出现拥塞, 需要调小发送窗口。
其中 Uj 是链路 j 归一化的 inflight 字节:
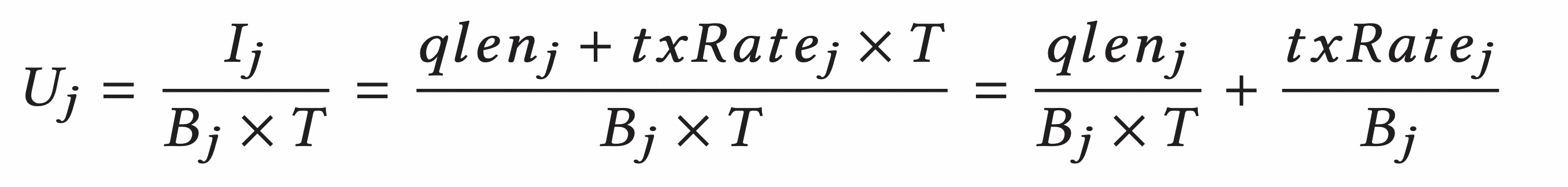
发送端需要对网络中最拥挤的链路做出反应:
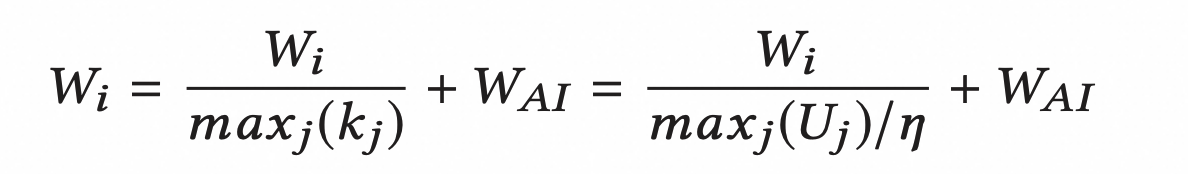
其中 Wi是发送窗口,Wai是一个为了确定公平性而存在的一个很小的值,Wai越大,总的吞吐量越大,这个公平性也会越少,但是整体队列长度也会增加。
通过其算法可以看到,HPCC 其实就是通过
qlen和txRate来调节发送窗口W的。
qlen越大,说明队列有堆积,发送窗口会调小。
txRate越大,说明带宽占用越高,可能即将发生拥塞,发送窗口需要调小。
这样最终达到调整发送窗口 W,使得 I略小于 B * T的最终目的。
在数据中心最常见的拥塞案例 incast 中,只有一个瓶颈,因此 HPCC 只需进行一轮调整即可解决拥塞问题。如果存在多个瓶颈,HPCC 需要多轮调整来解决拥塞问题。
HPCC 参数
HPCC 只有三个易于设置的参数:
η:η 控制带宽利用率和队列长度之间的简单权衡(由于数据包随机到达造成的临时冲突所引起的队列长度),因此默认将其设置为 95% ,仅损失 5% 的带宽,但实现了几乎零排队。有助于减少延迟和提高网络的响应速度。maxState:控制稳态稳定性和重新利用空闲带宽的速度之间的权衡。较高的 maxStage 值可以提高系统的稳定性,但可能会降低带宽的回收速度。默认是 5 ,能够在保持稳定性的同时,仍然比传统的加法增加方法更快地回收空闲带宽,尤其是在高带宽网络中。Wai:控制链路上可以维持近零队列的最大并发流数量与收敛到公平性速度之间的权衡,较小的 Wai 值可以支持链路上更多的并发流。
HPCC 实现
交换机 INT 填充
交换机将 INT 信息填充到 UDP 数据包中:

HPCC 的 INT 填充开销很低。在数据中心内部,路径长度通常不超过 5 跳,因此总填充最多为 42 字节,在 1KB 数据包中仅占 4.2% 。
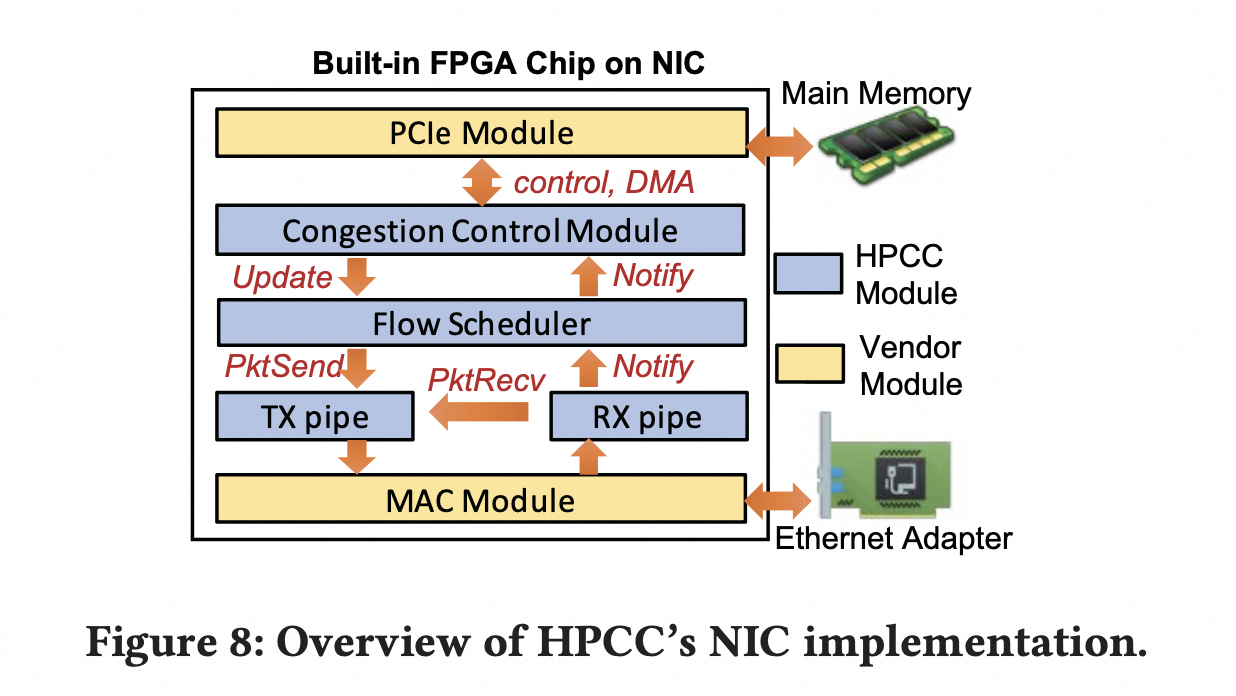
NIC 的拥塞控制
网卡上的 HPCC 实现如下图所示。其中蓝色为 HPCC 模块,黄色为供应商模块。HPCC 介于网卡和主存之间。
实验
HPCC vs DCQCN
benchmark 指标性能
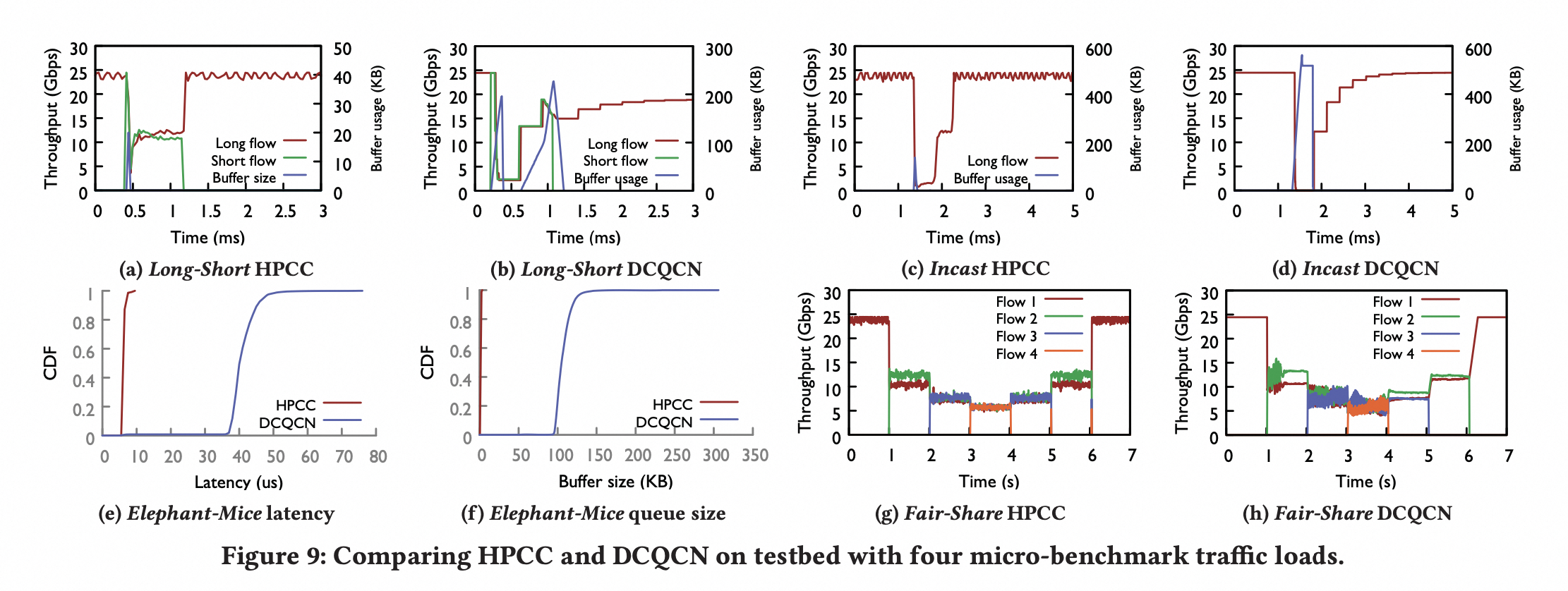
端到端性能
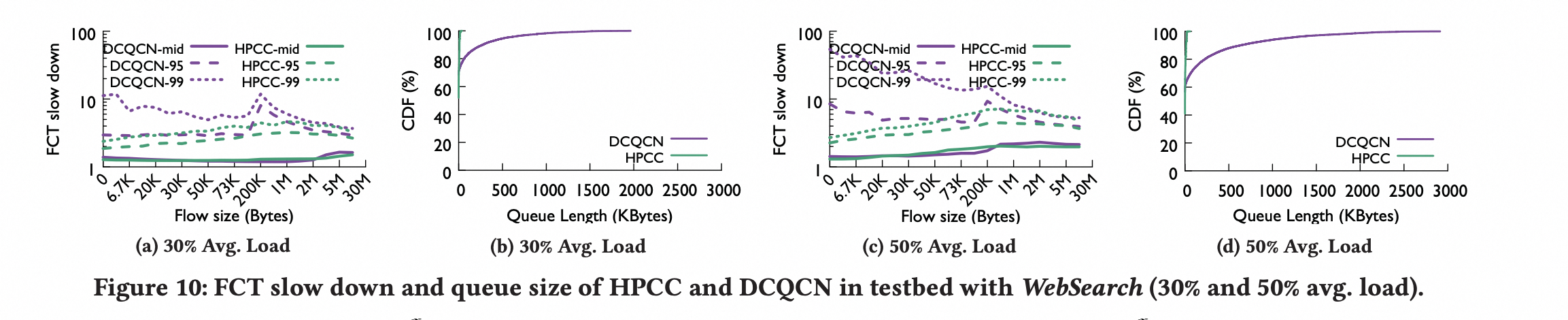
incast 性能
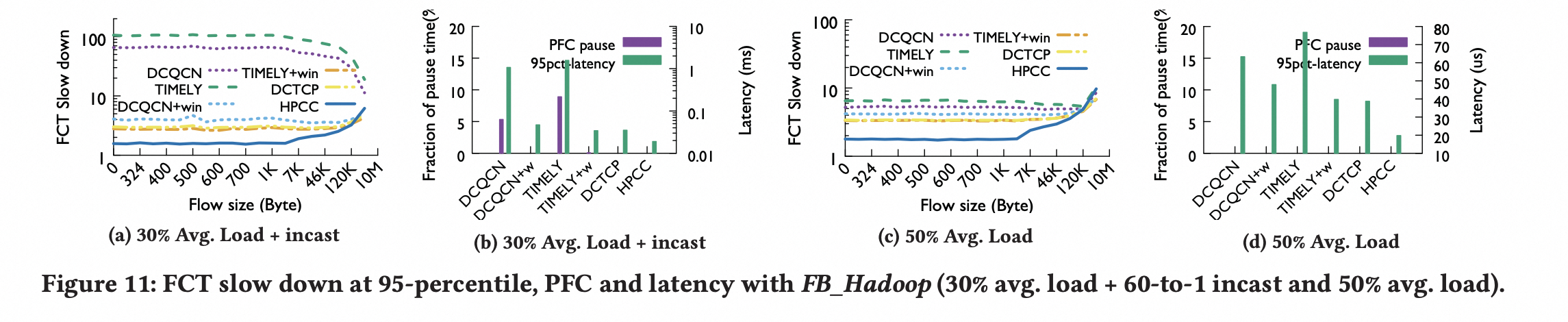
通过图a和图c可以看出:HPCC 适合短流 。
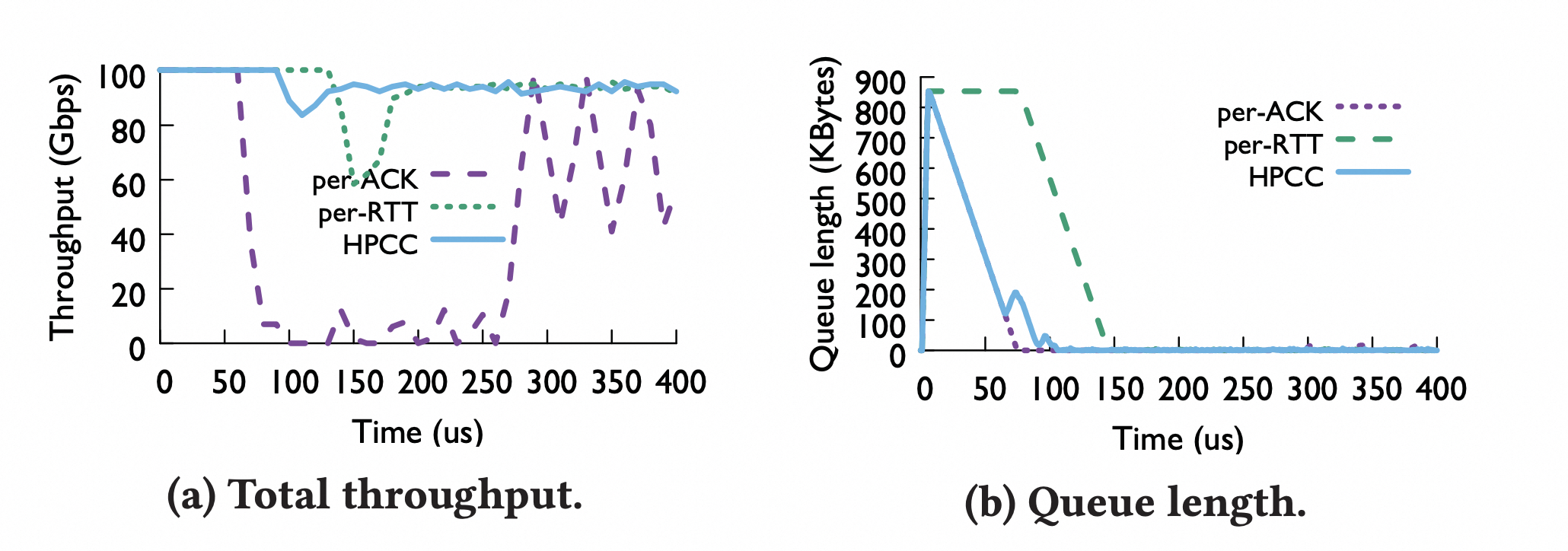
对 ACK 不同的反应
HPCC 通过综合考虑 ACK 和 RTT 来选择性的使用 INT 信息,实现快速反应而不至于过度反应。
总结
论文针对现有高性能网络中 CC 算法的局限性,提出一种新的 CC 算法:HPCC 。
HPCC 的核心理念是利用精确链路负载信息(INT)直接计算合适的发送速率。与其他 CC 算法相比,HPCC 实现了快速收敛、低队列堆积、公平以及易于在硬件中部署,满足了大规模网络中同时实现超低延迟、高带宽和高稳定性的目标。

















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









