







论文题目:Inference without Interference: Disaggregate LLM Inference for Mixed Downstream Workloads
原文地址:链接
翻译稿(来自谷歌翻译):
这篇论文主要讲的是大模型推理优化相关的内容。
题目
Inference without Interference: Disaggregate LLM Inference for Mixed Downstream Workloads
无干扰推理:混合下游工作负载的分解 LLM 推理
论文主要工作
这篇论文主要研究的是在大语言模型(LLM)的推理服务中,如何降低不同推理阶段之间的相互干扰,来提高推理服务的性能。
论文效果
论文的结果显示,TetriInfer 首个token生成时间(time-to-first-token,TTFT)、作业完成时间(job completion time,JCT)和推理成本效益(inference efficiency in terms of performance per dollar)方面都取得了大幅度的改进。具体来说,资源使用降低了38%,同时平均TTFT和平均JCT分别降低了97%和47%。
这篇论文的贡献是为LLM推理服务提供了一个优化的部署策略,旨在提高云服务中LLM的推理效率和成本效益。这对于部署和运行大型语言模型的公司和研究机构来说,其研究发现可能具有重要的实际应用价值。
背景知识
推理过程
LLM推理服务通常包括 prefill 阶段和 decode 阶段:
- prefill 阶段:接收外部的输入(prompt),转换成一系列的 token 。目的是准备好数据,为后续 decode 做准备。
- prefill 阶段会生成第一个 token 。
- decode 阶段:基于 prefill 阶段生成的信息,以自回归的方式逐步生成新的 token 。
prefill 阶段是计算密集型的,其计算量随输入 prompt 长度呈平方增长;decode 阶段是内存密集型的,其资源使用量随生成的 token 长度呈次线性增长。而现有的部署实践往往忽视了这些阶段的不同特性,导致了显著的性能干扰。
什么是干扰?不同阶段混合运行会引起性能下降,如推理速度下降。
论文实现方案
三个方向去优化:
- 为了避免同时运行 prefill 阶段时的干扰:限制在单次 prefill 迭代中处理的 token 数量,充分利用资源。
- 为什么这么做可以避免干扰?原因是:prefill 如果处理 token 数量太多,会增加 prefill 时延(处理时间)。
- 为了避免 prefill 和 decode 同时运行时的干扰:将 prefill 和 decode 分离,使得 prefill 和 decode 独立运行。
- 为什么这么做可以避免干扰?原因是:同时运行会增加 decode 阶段的时延(处理时间)。
- 为了避免同时运行 decode 阶段时的干扰:使用智能两级调度算法,通过预测资源使用情况进行增强。
- 为什么这么做可以避免干扰?原因是:同时运行 decode 会降低吞吐量(指的是系统处理推理请求和生成输出的速率),增加 decode 时延。
论文提出了 TetriInfer 系统解决了上述问题,TetriInfer 是一个利用精细的调度和分组策略来减少推理请求的干扰的大模型推理系统,包括三个主要特点:
- 固定大小块的划分:将提示(prompts)划分为固定大小的块,以便加速器始终在接近其计算饱和极限的状态下运行。
- prefill 和 decode 解耦:独立运行 prefill 和 decode ,使它们可以独立运行无干扰。
- 智能两级调度算法:结合预测的资源使用情况,使用一个智能的两级调度算法来避免解码调度热点,可平衡实例间的负载并避免干扰。它旨在根据推理请求的特征和解码阶段的资源使用情况,优化 prefill 和 decode 实例的调度。该算法运行在 prefill 的 scheduler 中。
推理架构
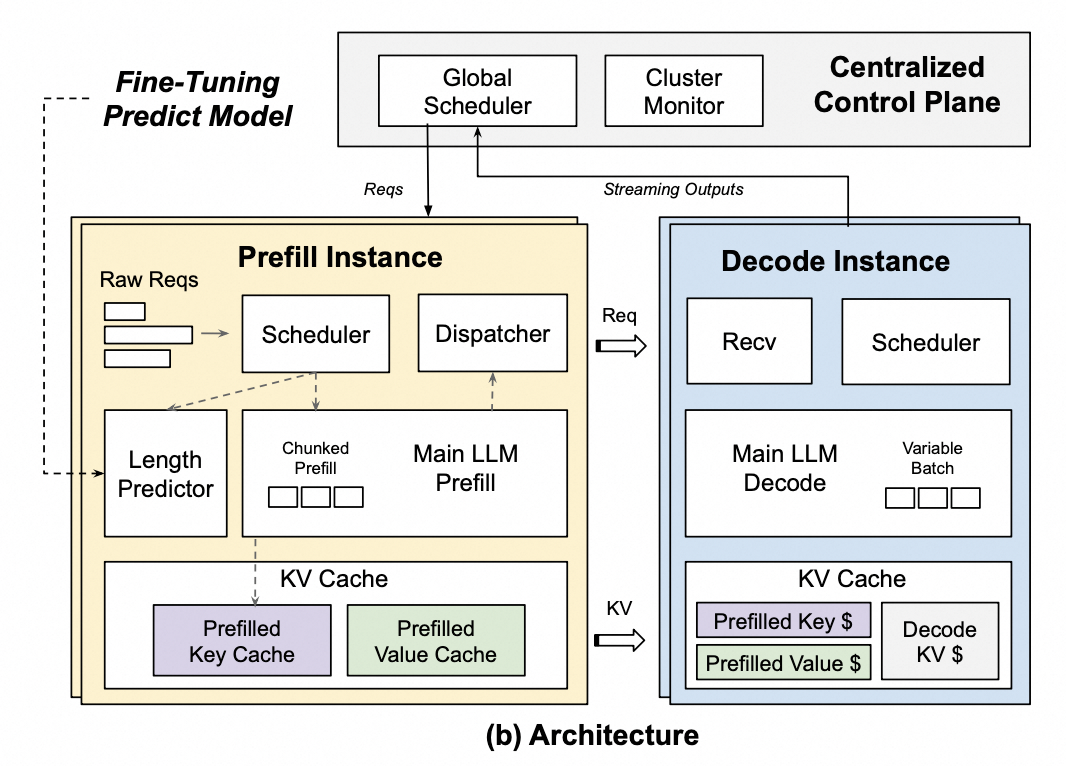
整体的流程是:
- 当外部推理请求过来时,集中控制平面的全局调度器会选择一个负载最小的 prefill 实例,然后将请求转发给它。
- 推理请求在 prefill 中会经过调度、长度预测、prefill 引擎和分发,每个推理请求都会经过这四个步骤。
- 调度:根据预定义的策略对推理请求进行排序。
- Main LLM prefill 引擎将所有请求划分为固定块。分块的目的是为了避免其他 prefill 请求带来的干扰。
- 长度预测:运行预测模型来推测请求生成的 token 长度范围,并根据长度范围来估计 decode 阶段的资源使用情况(资源使用的上下限)。
- 对于每个请求,结合长度预测的结果,分发器会运行解码间负载均衡算法来选择合适的 decode 实例,然后将生成的 KV 缓存转发给对应的 decode 实例。
- 在 decode 阶段,调度程序会根据长度预测的结果选择要在 decode 引擎中运行的解码请求,并将推理的结果转发给集中控制平面的全局调度器,全局调度器再将推理的结果转发给外部服务。
- 接收模块:接受 prefill 实例发送而来的请求,并等待接收 prefill 生成的 KV 缓存数据。然后将它们添加到调度程序的队列中
- 调度程序:使用连续批处理对动态大小的批次进行分组,并调用 decode 引擎以自回归的方式生成 token 。
- 在推理过程中,prefill 和 decode 会定期将其负载信息发送到集群监视器,集群监视器聚合所有 decode 实例的负载信息,并将其广播给所有的 prefill 实例让其用于调度分析。
包含三个主要模块:
- 集中控制平面:管理推理集群,是一个分布式系统
- 全局调度器:管理推理请求生命周期
- 输入:推理请求(外部)、解码阶段的流式输出结果(转发给外部)
- 输出:请求(转发到 prefill 实例)
- 集群监视器:管理 prefill 和 decode 的生命周期
- 输入:prefill 阶段和 decode 阶段的统计信息
- 输出:负载信息(给到 prefill 实例)
- 全局调度器:管理推理请求生命周期
- prefill 实例:加载必要的数据和设置计算资源,初始化模型并为推理做好准备
- 输入:集中控制平面输出的请求
- 输出:KV 缓存(给到 decode 实例)
- decode 实例:进行实际推理,模型处理输入数据并生成输出
- 输入:请求(来自 prefill 实例)、KV缓存(来自 prefill 实例)
- 输出:流式结果(给到集中控制平面)
数据链路
论文提到了在 prefill 和 decode 阶段之间数据的通信方式:
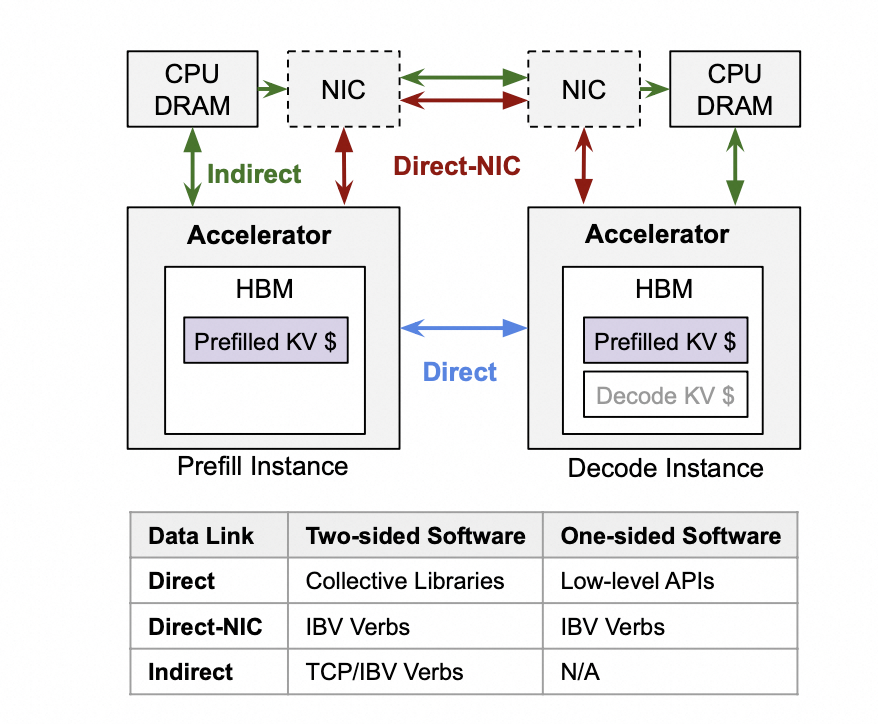
论文提供了三种数据通信方式的思路,用来将 prefill 生成的 KV 数据传输到 decode 的内存/显存上:
- Direct:如 NVLink
- Direct-NIC:如 RDMA 。实现高效的数据传输和通信,从而改善大模型推理任务的执行效率。
- Indirect:由于设备限制,论文采用的这种方式
论文还提到它们设计了一个统一的网络传输方案,来抽象上述三种不同的通信方式。该方案提供了统一的 send, receive, read, write 等接口。
如何接入 rdma
最主要的三个模块:
- 集中控制平面
- prefill 实例
- decode 实例
所以需要考虑在这三个主要模块之间接入 rdma 通信:
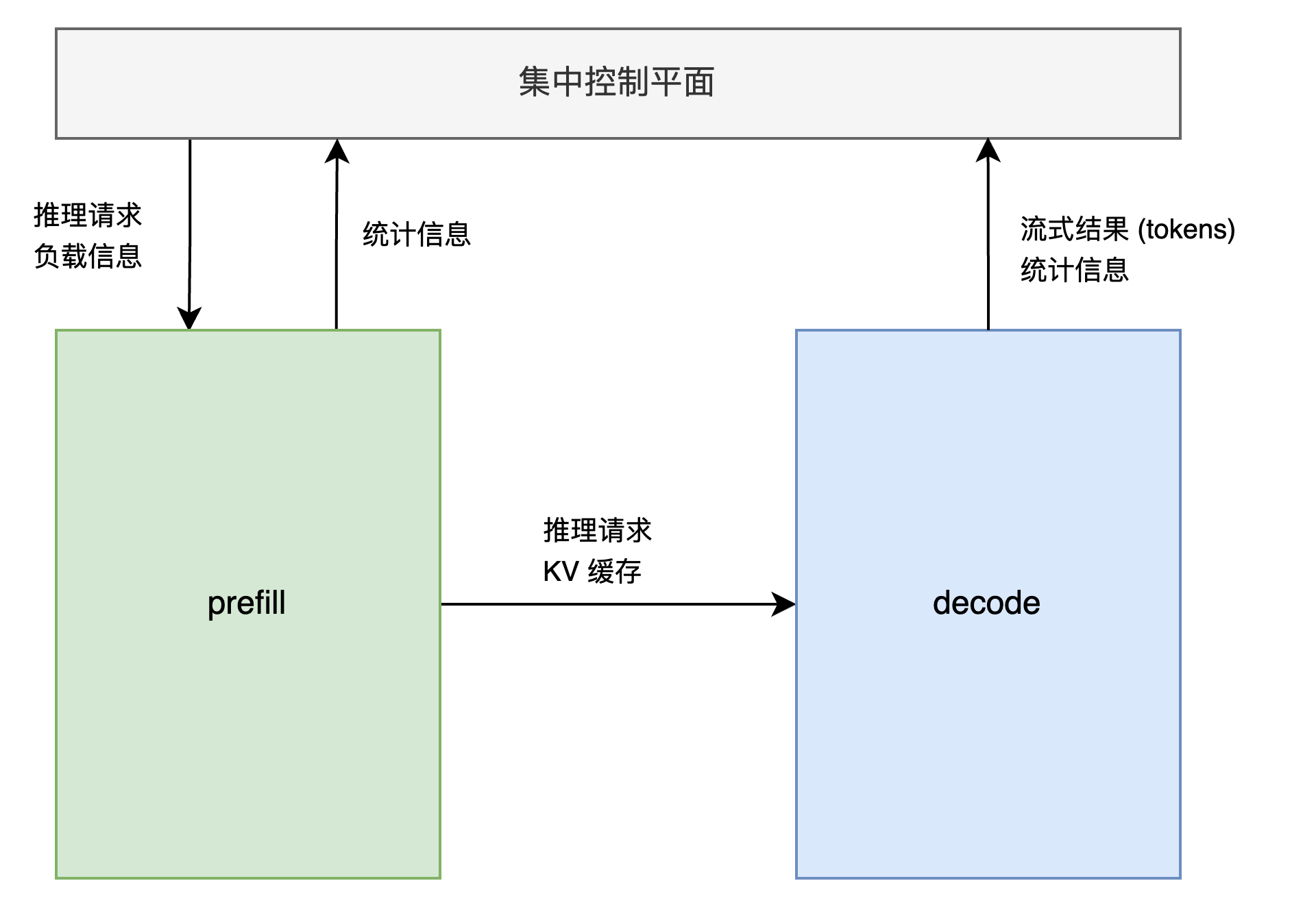
问题
问题:
- 干扰到底是什么?
- 不同阶段混合运行会引起性能下降,如推理速度下降
- KV Cache 是什么东西?
- 在 prefill 阶段会产生第一个 token ,中间的计算结果(每个 decode layer 开头的 k-gemm 和 v-gemm 的输出)会存入 kv cache 。
- prefill 阶段内部是否存在通信?decode 阶段内部是否存在通信?
- prefill 和 decode 应该都是不存在机内通信的。

















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









