



#前言
诶,额,好热,我已经再也离不开空调房了。
本文将结合C#在Unity中的应用讲解,代码编辑器使用Visual Studio。讲解内容来自《C#高级编程 第10版》和我的理解,如果有错希望大佬指出(骂我,不要客气!)。
下面是《C#高级编程 第10版》的pdf文件分享
#正文
#预防针
集合,听到名字最先想到的就是List<T>和字典,但我刚刚看了下,《C#高级编程》中介绍的非常详细,但感觉每一个讲的都很有必要。每一点都讲会很枯燥(好麻烦),但我还是打算把里面提到的所有内容写出来,如果大家看得没劲,就重点看看List<T>和字典吧。
#集合的接口和类型
下图来自《C#高级编程》p285:
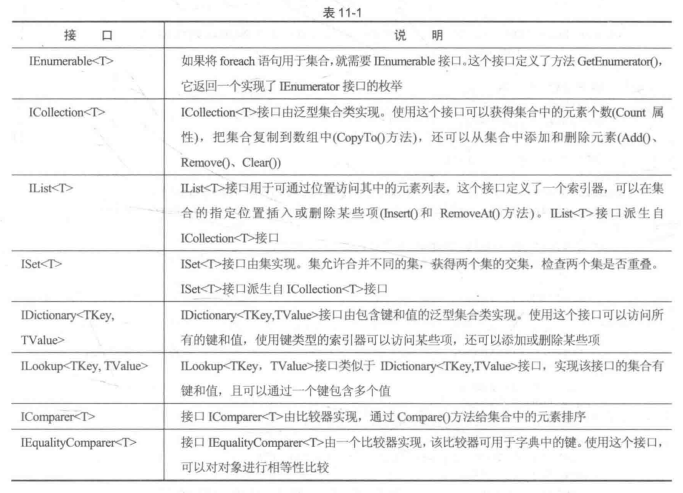
以上为集合类型中可能用到的接口(一个集合类会实现上面的部分接口,并具有上述接口效果)。
#列表
-
介绍
List<T>类实现了IList<T>、ICollection<T>、IEnumerable<T>(IList、ICollection、IEnumerable)这些接口。也就是说List<T>可以使用foreach进行遍历,可以添加删除(add(),Remove())和插入和删除特定位置的元素。
List<T>的T是泛型(泛型之后的文章会讲),T应该写成你需要存放在列表中的类型。
-
创建数组
List<T>可以简单的理解成可扩展的数组,当你创建一个列表之后你可以通过添加和删除来控制其中的元素,之后可以通过索引来获取其中的元素。
使用默认构造函数(new List<T>())可以创建一个空的列表。当一个元素加入列表后,列表的容量会扩充到可以接纳4个元素(一个长度为4的数组),在列表中加入第五个元素时,列表的容量会再次扩充,会变成可以容纳8个元素(长度为8的数组),这时,原来的数组中的四个元素会被复制到这个新的容纳8个元素的数组中,再加上新加入的元素。之后每当容量超过就会增加四个元素,4,8,12,16……
我刚刚试了下,在容量自动扩充后,将元素数量减到四个以下,集合容量并不会变动,使用Clear()去清除也是一样。如果想要减小容量需要调用TrimExcess()方法,该方法可以去除多余的容量,但如果元素个数超过了容量的90%,这个函数就不会执行任何操作。列表的容量是可以获取,也可以直接修改,如果想要直接修改到合适大小也是没问题的。(容量问题平时也没有管过。)
可以创建列表的时候加入数字参数,这样可以设置初始的容量大小,之后当容量不足时,会增加数字参数大小的容量。
List
<
int
>
myList1
=
new
List
<
int
>
(
)
;
//正常创建列表
List
<
int
>
myList2
=
new
List
<
int
>
(
10
)
;
//将初始容量设置为10,之后是20,30……
List
<
int
>
myList3
=
new
List
<
int
>
(
)
{
1
,
2
,
3
}
;
//在创建时加入三个元素
-
添加元素
myList1
.
Add
(
1
)
;
//添加一个元素
myList1
.
AddRange
(
2
,
3
)
;
//添加多个元素
-
插入元素
myList1
.
Insert
(
1
,
2
)
;
//第一个数代表需要插入的位置(从0开始),在插入后,位于这个位置之后的元素全部后移一位。第二个数是插入元素。(如果插入索引大于元素个数(超范围了),会报错。)
InsertRange()可以插入多个元素,但方法的第二个参数实现了IEnumerable<T>接口(可以被foreach的),使用起来比Insert更加麻烦。
-
访问元素
int
a
=
myList1
[
0
]
;
//可以直接像使用数组一样,使用索引来获取元素。
-
删除元素
myList1
.
RemoveAt
(
1
)
;
//删除索引值为1的元素
myList1
.
Remove
(
2
)
;
//删除元素等于2的元素。如果List中存放的是类,会先检查这个类型是否实现了IEquatable<T>接口,也就是调用类中的Equals()方法,如果类中没有实现该接口,就直接使用Object中的Equals方法进行比较。方法返回一个bool类型,用于表示是否找到并删除元素。
myList1
.
RemoveRange
(
1
,
2
)
;
//表示从索引为1的位置开始,删除2个元素。通过这个方法可以删除多个元素。
-
搜索
通过不同的方法,可以获得要查找的元素的索引,或者搜素元素本身。可以使用的方法有IndexOf(),LastIndexOf(),FindIndex(),FindLastIndex(),Find()和FindLast()。如果只检查元素是否存在,List<T>类提供了Exists()。
int
a
=
myList1
.
IndexOf
(
2
)
;
//通过查找元素,返回列表中元素的索引,如果没找到就返回-1。如果list中存放的是类,就采用Equals方法进行比较。IndexOf()还可以指定查找范围。
int
b
=
myList1
.
FindIndex
(
Predictate
<
T
>
match
)
;
//这个参数是一个委托,在使用时需要传入一个方法,这个方法有一个传入参数并且返回值是一个bool类型。这里不详述了(其实差不多讲完了)。
int
c
=
myList1
.
Find
(
Predictate
<
T
>
match
)
;
//与FindIndex相似,但返回的是一个元素,而不是索引值。
List
<
int
>
myList2
=
myList1
.
Find
(
Predictate
<
T
>
match
)
;
//这个方法返回所有满足条件的元素。
-
排序
public
void
List
<
T
>
.
Sort
(
)
;
public
void
List
<
T
>
.
Sort
(
Comparison
<
T
>
)
;
public
void
List
<
T
>
.
Sort
(
IComparer
<
T
>
)
;
public
void
List
<
T
>
.
Sort
(
Int32
,
Int32
,
IComparer
<
T
>
)
;
Comprison<T>是一个委托,IComparer<T>是实现该接口的类。排序的内容和数组那里很像,这里就不在详诉了。至于委托的内容,之后的文章会讲,讲到是大家自然就明白了(就是传入一个方法)。
#队列
-
介绍
那个,排队知道吧。越是先来的人,就越先被处理。队列就是这种思想,采用先放入队列的元素会被更先处理。除了根据顺序处理的队列,还有根据优先级来处理元素的队列。
队列的类是Queue<T>,它实现了ICollection和IEnumerable<T>接口,但没有实现ICollection<T>接口,因此没有Add和Remove的方法。(我觉得这个接口的讲法让人头大,一般来说我们只关心这些集合中的常用方法,并不关心哪些接口被实现。)
我当初第一次接触队列是在学数据结构的时候,只能说《C#高级编程》讲的太详细了。
-
常用方法
下图来自《C#高级编程》P295:

-
用法讲解
在《C#高级编程》里详细描述了如何使用队列来处理文档(例子的意图是描述处理Web端发来的文档数据)。大家可以去看看,我就不复制过来了。
应用场合:
-
异步线程:可用于线程间的通讯,同步线程间的任务处理。
-
通讯:接收指定长度的通讯信息,在取出队列后,再读取接收。
-
报警提示:逐条处理队列内的内容。
就是那种,会在某种地方被填满,然后被顺序的逐条处理的时候(处理时最好是带有先进先出顺序的时候),就可以考虑使用队列。(好难说。)
#栈
-
介绍
这个栈,和之前在值类型和引用类型中提到的堆栈(简称:栈)不同,堆栈是存储数据的位置,而这里的栈是一种和队列类似的元素的容器。不过居然叫做堆栈了,使用的存储方式自然是栈的思想,先进后出。
队列的思想是先进先出,而栈的思想是先进后出,下面是《C#高级编程》中的截图:
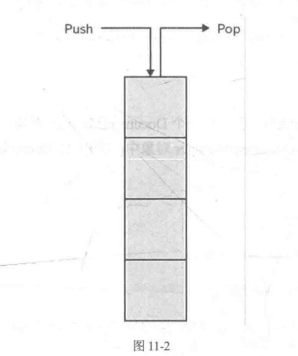
push()和Pop()是放入和取出的方法。从图上可知,越是先进的元素,就处于越下面的位置,相对的出栈时间就越晚,这就是先进后出。
栈的类是Stack<T>,和队列一样,实现了IEnumerable<T>和ICollection接口。
-
常用方法
下图来自《C#高级编程》P299:
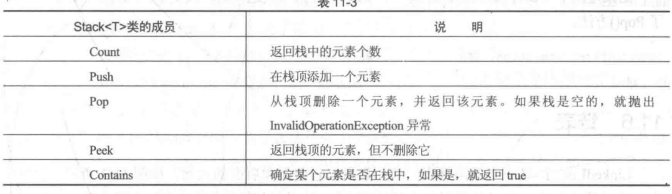
-
使用场景
前面几个讲完,基础使用应该不用我再说了。感觉刻意使用栈的场景不多,计算器计算(高级点的计算器,可以一次输入完整,然后根据计算优先级计算的)算是一个。
#链表
-
介绍
链表算是和前面的内容有明显区别了,主要是在存储方式上有明显区别,之前的列表,栈,队列,全都是基于数组(其实也可以做成基于链表的)。数组是一段连续的存储内容,而链表则可以是不连续的。

这是基本的链表结构,每个元素中含有一个头指针和一个指向下一个元素地址的指针。
链表比起数组的优点是插入一个元素的速度很快,只需要修改前后位置的指针(这是数据结构的必考点哦,有兴趣的可以自己写一下,怎么才能把两端的节点和新加入的节点连起来),而数组需要将元素插入,然后其他元素全部后移。但也有缺点,数组可以依靠连续的地址快速定位索引的元素,而链表却需要一个个的向后移动去寻找,更加耗时。因为前后各有一个指针,所以链表显然更加消耗内存。
我就不详诉了,链表的玩法很多的,等以后有机会讲数据结构的知识的时候,我在详细讲讲链表的各种花样。
#字典
-
介绍
字典的主要特性是根据键快速查找值。可以自由添加和删除元素,这点与List<T>类似。
字典使用的类是Dictionary<TKey, TValue>,键与值是一一对应的关系。
-
结构
下图截取自《C#高级编程》P307,是简化版的字典结构:
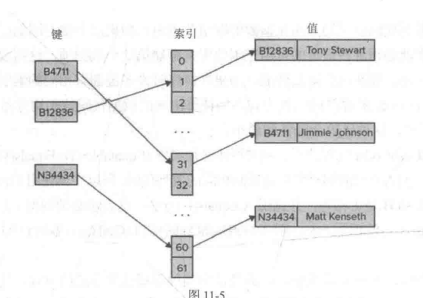
-
创建
Dictionary
<
int
,
string
>
myDic
=
new
Dictionary
<
int
,
string
>
(
)
{
[
3
]
=
"three"
}
;
这里的3是键值,而不是索引。
-
键的类型
用作字典中的键的类型必须实现重写Object类中的GetHashCode()方法(int和string类型可以直接使用,两者皆重载了GetHashCode()方法)。字典类需要确认元素位置时,就会调用键类型的GetHashCode()方法。GetHashCode()方法返回一个int类型,在字典自己的计算下转换成存放值的索引。
GetHashCode()方法的实现代码必须满足以下要求:
-
相同的对象应总是返回相同的值。
-
不同的对象可以返回相同的值。
-
它不能抛出异常。
-
它应至少使用一个实例。
-
散列代码最好在对象的生存期中不发生变化。
还应该尽量满足以下要求:
-
它应执行得比较快,计算的开销不大。
-
散列的代码值应该平均分布在int可以存储的整个数字范围上。
字典的性能取决于GetHashCode()方法实现代码。
#集
集是不可重复的集合,和List<T>很像,除了不能有重复元素,有两个类型一个是SortedSet<T>,一个是HashSet<T>,一个是排序的,一个是不排序的。
因为和List<T>很像,这里就不讲了。小心使用时添加元素的时候是否添加上就可以了。
#结束语
-
建议
数组在未来的编程中是非常常用的,了解多一些可以更好的使用。
其实我讲的内容是简化的,很多地方可能还没有讲清楚。如果大家哪里没有看懂,可以去翻看一下《C#高级编程 第10版》,如果还是没有搞懂,欢迎在评论区询问,我会尽力回答的。以上提到的内容都是基础中的基础,是绝对不允许出现不理解的情况的。
如果害羞不好意思在评论区询问,欢迎大家加我QQ来讨论哦。QQ:2243211562
-
杂谈
中午做了个梦,梦到我牙齿掉了,再去医院的路上,突然惊醒,用舌头确认了牙齿还在,看看时间还在午休时间,然后我选择了继续睡。(虽然梦里掉牙齿不痛,但牙齿一颗颗掉下来之后,嘴巴变得凉飕飕的,舌头碰触到的东西变成了软软的牙龈,嘶,一股恐惧感直接让我背脊发凉。)
再次醒来后我去网上搜了一下解梦啊,说我要事业要上升了诶,好耶!也有说我亲人要出事的,呸呸呸。说到底,依靠背板的科学算命怎么可能算得准嘛,说起来我也不信算命。如果梦可以解的话,那我梦到奥特曼作何解,是预示着我要成为光了吗。
本篇文章就到这里,大家下次见。

















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









