







 本文深入探讨深度学习核心概念,包括CNN、RNN、LSTM、GAN等网络结构,详解BatchNormalization、梯度消失与爆炸解决方案,及CNN在CV、NLP、Speech领域的成功应用。同时,介绍了WordEmbedding、目标检测、迁移学习等关键技术。
本文深入探讨深度学习核心概念,包括CNN、RNN、LSTM、GAN等网络结构,详解BatchNormalization、梯度消失与爆炸解决方案,及CNN在CV、NLP、Speech领域的成功应用。同时,介绍了WordEmbedding、目标检测、迁移学习等关键技术。
1、深度学习中的归一化问题
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm
2、CNN卷积核
CNN的卷积核是单层的还是多层的?
什么是卷积?
什么是CNN的池化pool层?
请详细说说CNN的工作原理
???CNN究竟是怎样一步一步工作的?
CNN是什么,CNN关键的层有哪些?
CNN的特点以及优势
卷积Output计算公式:[(n+2p-f)/s + 1] * [(n+2p-f)/s + 1]
3、生成对抗网络
4、学梵高作画的原理。
5、请简要介绍下tensorflow的计算图
6、简单说说CNN常用的几个模型
6、你有那些CNN,RNN的调参经验
7、CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
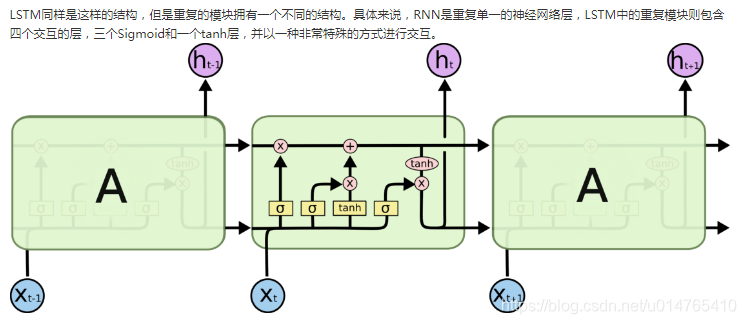
8、LSTM结构推导,为什么比RNN好?
为什么LSTM模型中既存在sigmoid又存在tanh两种激活函数,而不是选择统一一种sigmoid或者tanh?这样做的目的是什么?
LSTM神经网络输入输出究竟是怎样的?
如何从RNN起步,一步一步通俗理解LSTM
如何形象的理解LSTM的三个门
???通过一张张动图形象的理解LSTM
***记住GRU/LSTM的推导

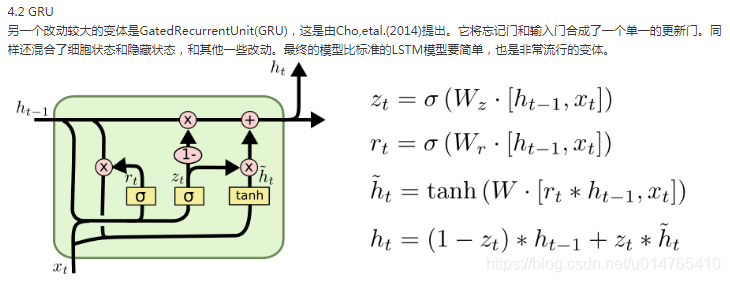
9、Sigmoid、Tanh、ReLu这三个激活函数有什么缺点或不足,有没改进的激活函数。
为什么引入非线性激励函数?
请问人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
神经网络中激活函数的真正意义?一个激活函数需要具有哪些必要的属性?还有哪些属性是好的属性但不必要的?
ReLU、LReLU、PReLU、CReLU、ELU、SELU
简单说下sigmoid激活函数
10、word embedding
NNLM ->Word2Vec ->Seq2Seq ->Seq2Seq with Attention ->Transformer(self-attention) ->Elmo->GPT ->BERT
***deeplearning笔记5:序列模型(Glove)
Glove:充分利用语料库
Word2vec:没有充分利用语料库(Skip-gram(word->context;负采样/层级softmax)(CBOW(context -> word))
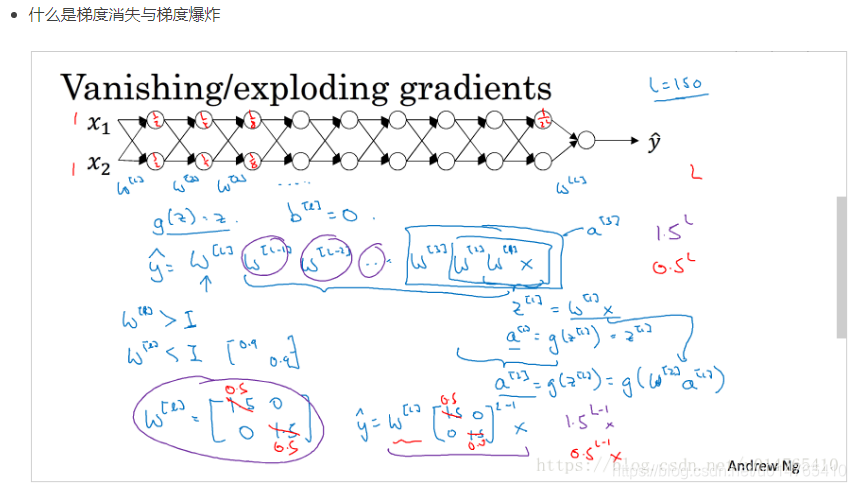
11、梯度消失 和 梯度爆炸
如何解决RNN梯度爆炸和弥散的问题?
如何解决梯度消失和梯度膨胀
什么是梯度爆炸?
梯度爆炸会引发什么问题?
如何确定是否出现梯度爆炸?
如何修复梯度爆炸问题?



12、广义线性模型是怎被应用在深度学习中?
13、深度学习常用方法
DNN,CNN,RNN,自动编码器(AutoEncoder)、稀疏编码(Sparse Coding)、深度信念网络(DBM)、限制玻尔兹曼机(RBM)
14、梯度下降法的神经网络容易收敛到局部最优,为什么应用广泛?
15、什么是RNN?
16、???rcnn、fast-rcnn和faster-rcnn三者的区别是什么
17、在神经网络中,有哪些办法防止过拟合?
请简述应当从哪些方向上思考和解决深度学习中出现的的over fitting问题?
dropout:实施dropout后,需要对dropout后的layer在除以keep-prob,以保证后一层的z值不变;
L1 , L2
early stopping
batch normalization: (batch-mean)/std,mean和std都是batch计算的结果,这相当于给x增加了一些noise,从而使其具有一定的正则化效果
网络bagging
data augmentation
权重衰减
调整网络结构
18、神经网络中,是否隐藏层如果具有足够数量的单位,它就可以近似任何连续函数?
Yes。
19、不平衡数据是否会摧毁神经网络?
Yes,可以利用 下采样方式 补救。或者 生成 新的样本。
20、???你如何判断一个神经网络是记忆还是泛化?
21、迁移学习
22、目标检测
什么是边框回归Bounding-Box regression,以及为什么要做、怎么做
请阐述下Selective Search的主要思想
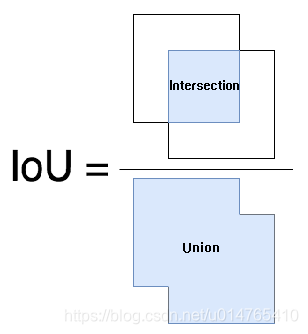
什么是非极大值抑制(NMS)?
什么是深度学习中的anchor?
23、深度学习中有什么加快收敛/降低训练难度的方法?
残差网络
优化方法:Adam
pretrain
学习率

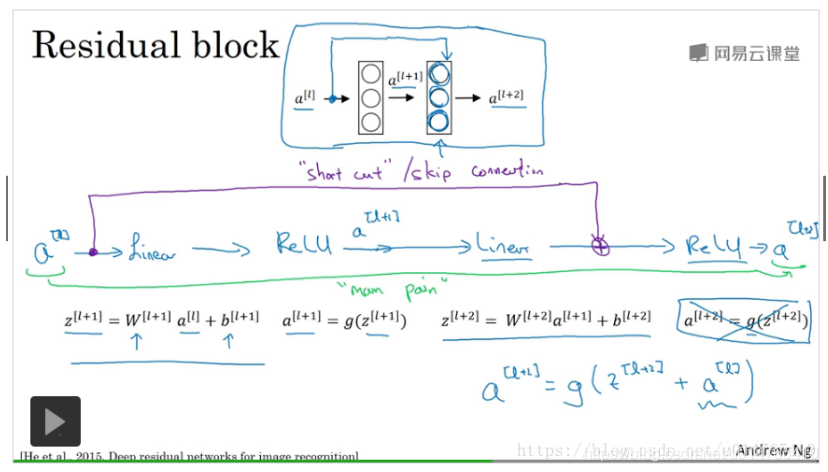

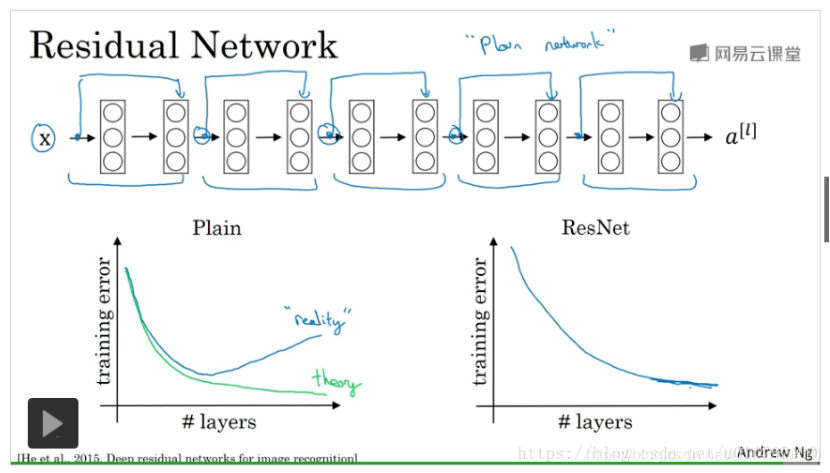

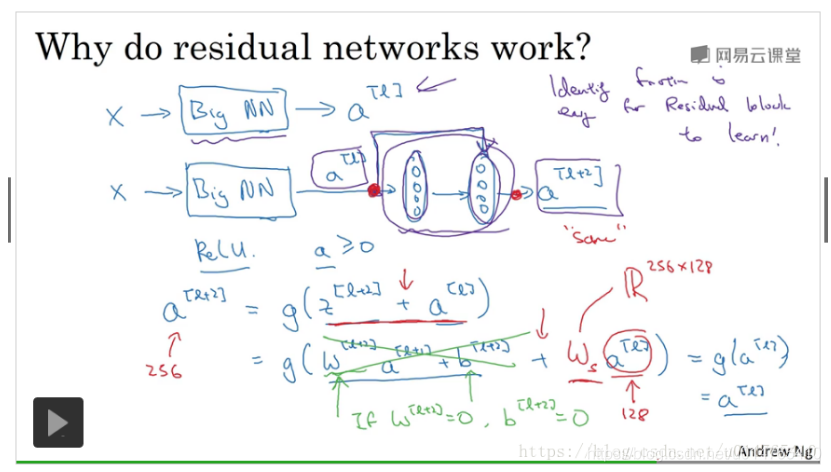

24、???请写出Batch Normalization的计算方法及其应用
25、神经网络 前向 后向 传播
deeplearning笔记1:神经网络和深度学习
当神经网络的调参效果不好时,从哪些角度思考?(不要首先归结于overfiting)


















 34万+
34万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











