







 本文介绍了一种基于特征处理的信贷风险控制系统。主要内容包括数据清洗、异常值识别、文本及图像数据处理、特征选择等方法,并提供了地理位置处理的具体案例。此外,还介绍了xgboost防止过拟合的策略。
本文介绍了一种基于特征处理的信贷风险控制系统。主要内容包括数据清洗、异常值识别、文本及图像数据处理、特征选择等方法,并提供了地理位置处理的具体案例。此外,还介绍了xgboost防止过拟合的策略。
项目简介:根据一堆特征,判定用户是否信誉良好,可进行借贷。
这一节主要总结一下 “特征处理” 方面的知识:
1、数据清洗
(1)缺失值处理
1)当缺失值过多的时候,如:达到90%,则有2种策略:1)直接去掉这一feature;可以将不缺省的sample打印出来,查看是否具有某一规律,比如:该feature是用户比较难填写的项目,一般填写的用户,信贷信誉都很好。
2)当缺失值为40% - 60%时,可以将这些缺失值单独看成是一个新的category。
3)当缺失值达到1% - 20%时,可以用mean,众数 等value进行填充。
(2)outlier识别:在dataset中下述两种sample可以考虑剔除:
1)有很多feature都缺失的sample;
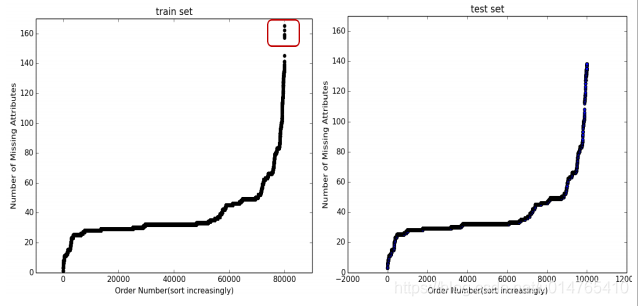
2)分别统计trainset和testset中,各个sample缺失值的可能个数N,以及各个N值下的sample个数Y,以N为横坐标,Y为纵坐标,观察trainset和testset的分布曲线,剔除与 testset中分布不一致的点。如下图所示,trainset中红色方框内的sample分布于testset不同,可以作为outlier剔除。
(3)文本处理
举个栗子,比如在淘宝上买东西时,进入商品页面,在商品下方会有一个评论区,买家往往会根据评论的好坏来决定要不要买。因此,在预测商品销量时,我们可以将评论区的文本数据进行挖掘,比如,根据文本数据建立一个词表,从而判定一个评论是positive还是negative,我们在predict商品销量时,即可将评论的positive和negative属性作为一个feature。
(4)图像数据的outlier检测
可以将image放入一个训练好的net中,将output的全连接层看成是其new_feature,根据new_feature,求各类image的平均值center,离center较远的image即可被视为outlier。in pratical,outlier检测方法要复杂的多。
(5)一个feature方差较大,除了能推出其对predict可能起着重要作用,我们还应该注意,方差较大,说明数据之间的value相差较大,如:买家购买物品价格,可能从1元-上万不等,如果不对数据做预处理,可能会影响model fit,在这个例子中,我们可以对数据进行“离散化”操作。
(6)feature selection共有3种方案:filter,wrapper,embedding,在本节中老师提到了filter,embedding方法,分别为:
1)filter:如果feature的方差较小,则可推断其对predict所起的作用较小,可剔除;
2)embedding:我们可以根据xgboost/GBDT的结果,得出feature_importance,从而选择Top20/40的feature,具体要选多少feature应该根据dataset大小来定。
(7)unbalanced data两种处理方法
1)对loss function中不同label误分赋以不同的weight,从而弥补data unbalanced的问题;
2)对数据量较少的label进行上采样;
2、通过案例学习到的一些特征处理方法
(1)地理位置的处理
1)我们可以首先对city进行聚类,将其分为“一线/二线/三线”城市;
2)可以网上搜集各个city的经纬度信息,从而获得不同city之间的相似度;
3)对city 进行离散化处理:如将300多个city离散化为6个region;
(2)用户信息中 地址栏 书写地址不同
当用户地址栏 书写的地址 不同时,我们可以推断,这些地址栏中书写的地址可能是:身份证地址、工作地址、或常居地,从而可以推断出,用户不是本地居民,则其经济水平相比土著,可能较低。
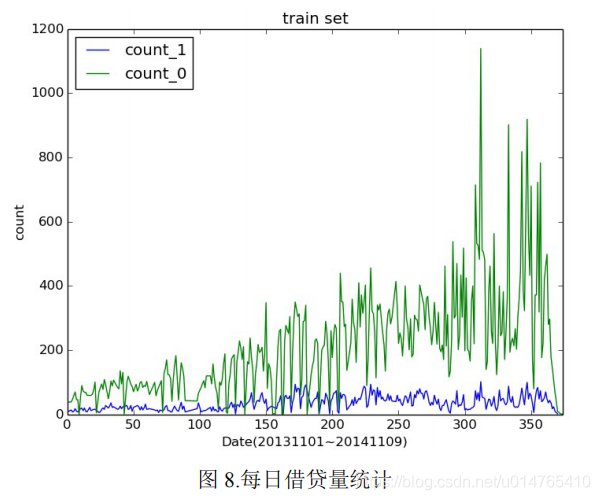
(3)我们可以根据“业务线的变化”,将一些连续值离散化。
从下图可以看出,借贷数量随着时间的推移会呈现不同的count,我们可以根据变化边界,将数据离散化。
3、xgboost防止overfitting可采取方式
1)bagging;
2)early-stopping;
以下为case第一名解决方案
https://github.com/wbqjyjy/ML-/tree/master/kaggle%E5%AE%9E%E6%88%98%E6%A1%88%E4%BE%8B/%E9%87%91%E8%9E%8D%E9%A3%8E%E6%8E%A7%E5%A4%A7%E8%B5%9B/PPD_RiskControl_Competition


















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











