







在处理数据之前,我们首先要观察以下各个feature的分布,方差,看看是否有outlier,如果,对其进行去噪处理。
采用的方法是:利用ensemble的方法,集成多个模型的预测结果。
在进行正式训练之前,我们可以将 train data 和 test data合并,一起对其进行预处理,这样,处理后的test最后便可以直接放到训练好的model中进行prediction。
code中一些note:
1、将不平滑的label(price)进行平滑(正态分布),从而更好地fit model,这种处理方式类似于对unbalanced data进行的处理:
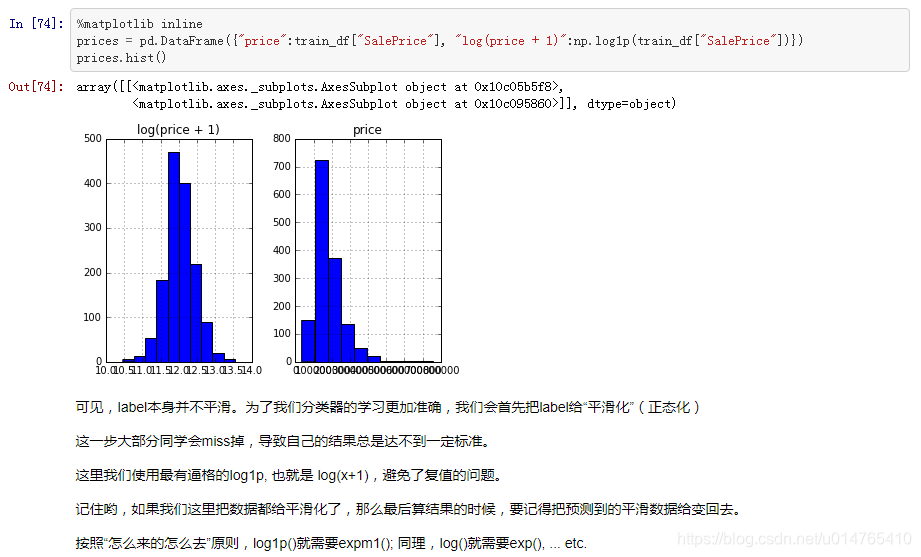
2、正确化变量
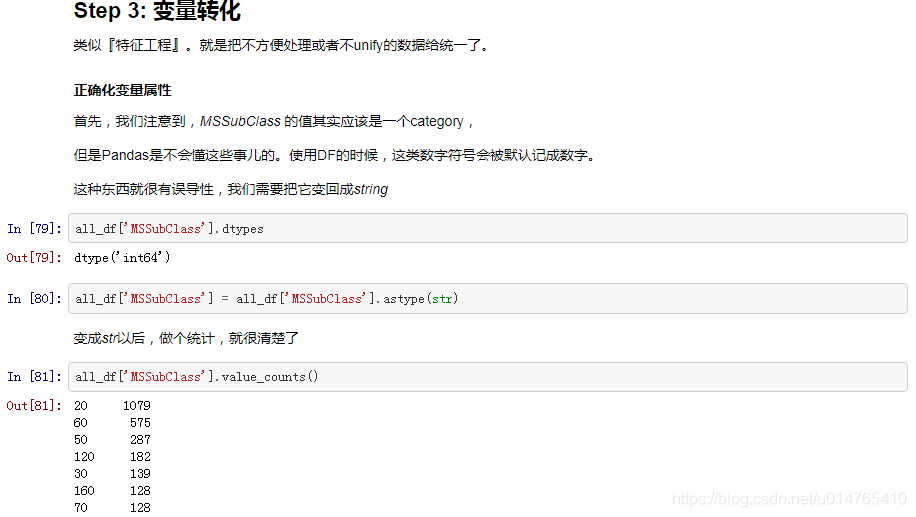
3、可以一次性将dataset中的所有category数据全都one-hot:
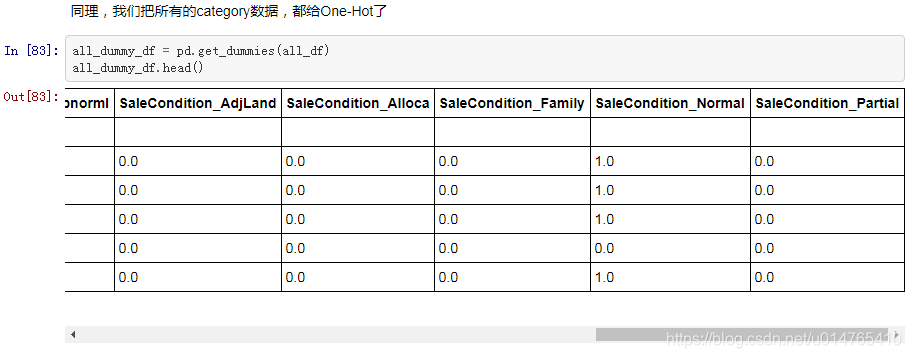


















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











