




 本文深入探讨特征工程中的关键概念,包括二值化、量化、对数转换、特征缩放、交互特征生成及特征选择,旨在优化机器学习模型的输入,提升预测准确性。
本文深入探讨特征工程中的关键概念,包括二值化、量化、对数转换、特征缩放、交互特征生成及特征选择,旨在优化机器学习模型的输入,提升预测准确性。
dealing with counts
- Binarization
举例说明:
假设我们现在要构建一个music recommender,recommender可根据user的“listen count”来向其他user推荐歌曲。在recommender中有一弊病,即listen count次数并不一定能真实反应user对歌曲的喜爱程度,比如:user1听song1 10 ,user2听song2 1次,并不一定代表song1要比song2好听10倍,这种listen count的差别也可能是由于user的听歌习惯不同,比如某些user习惯单曲循环,而有些user习惯在特定环境听某一类歌曲。
为了解决上述recommender根据listen count来决定song popularity的问题,我们可以将每首song的listen count 这一特征“Binarization”,即:当listen count >= 1时,listen count = 1;当listen count = 0 时,listen count = 0; - Binning / Quantization
举例说明:
假设我们现在要根据“review count”给各个article打分,但是,根据这一准则给article打分存在一个问题,即:不同article的“review count”可能会处于不同的“数量级”,如果直接用model拟合review count的话,这很有可能会破坏model的学习。为了解决这一问题,我们可以采用Quantization的方法,将review count中不同数量级的value分到不同的bin中,并最终用bin value来表示review count。
Quantization可以通过以下几种方式进行:
- fixed width:在该种方法中bin是等宽的,bin的width可以为linear scaled,或exponentially scaled。
- adaptive:采用 quantiles of the distribution 来分割 feature value,使得每个bin具有同等数量的value。
Log transformation
首先声明:log transformation会改变feature vector的原始分布。
一般情况下,假设feature vector服从Guassian distribution,但是,当feature vector的value分布在不同的“数量级”上时,这种Guassion distribution将被破坏,为了解决这一问题,我们可以采用“Log transformation”,通过 log transformation,可以使得feature vector近似服从Guassion distribution。
除此以外,log transformation 也可以用于处理 heavy-tailed distribution。通过log transformation,可以“压缩长尾数据”,也可以“扩展断尾数据”。
个人理解:通过log transformation,可以增加feature value的差异性,从而能够更好的用于model的学习。
log transformation 是 power transformation 的一个特例。power transformation是一个 variance stabilizing transformations,可以减少heavy tailed的状况。
以“泊松分布”为例,在“泊松分布”中,variance = mean = lambda,当增大mean时,同时会增加variance,从而增加heavy tailed的情况,为了解决这一问题,我们可以采用“power transformation”,改变feature value的distribution,从而使得variance不在随着mean的变化而变化。例如,可以对feature value求square root,即 xhat = x1/2,通过这一transform,可以使得feature vector的variance为一个constant.
同时综合了“log transform”和“square root transform”的一个transformation叫做:Box-Cox transform,公式如下:
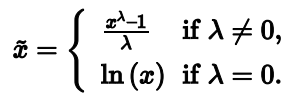
在scipy中可以找到Box-Cox transformation:
from scipy import stats
stats.boxcox(feature vector , lmbda = 0)
关于更多的power transformation可以参阅《power transforms in Econometric Methods》。
feature scaling or normalization
models that are smooth functions are sensitive to the scale of input feature。为解决这一问题,需要对input feature进行feature scaling,下面简述3种方法:
- Min-Max scaling
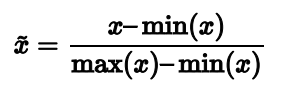
xhat 属于[0,1]。 - Standardization
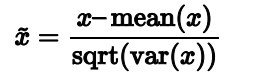
xhat 的mean=0,variance=1。 - L2 normalization
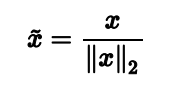

L2 normalization既可以用于data vector,也可以用于feature vector,实施L2 normalization后的data的norm =1 。
上述前2种方法,不能在sparse data上利用,这样会使得原本为0的feature value变为nonzero,从而增加“计算量”。此外,在word one-hot vector中,如果要使用上述2种方法处理数据,会使处理后的representation中,包含原本没有的word。
note that:feature scaling并不会改变原vector的distribution。
Interaction features
将原始feature之间进行inner product,可以产生interaction features。interaction features相当于是同时考虑了两种feature的情况下,类似于逻辑运算AND操作。
interaction features可以使用如下API产生:
import sklearn.preprocessing as preproc
preproc.PolynomialFeatures(include_bias=False).fit_transform(X)
使用interaction features势必会使data的feature量暴增,从而加大model fitting的计算量,为了解决这一问题,可以使用feature selection.
feature selection
feature selection主要有3种方式,具体如下:
- filtering
举例说明:计算feature与target之间的correlation 或 mutual information,进而判断feature是否影响target的取值,根据dependence进行feature removal。
这种feature selection,没有将要fitting model考虑在内,因此,要慎用。如果使用不当,很可能将原本对model fitting有用的feature去掉。 - wrapper methods
该方法会检验所用可能的subsets对于model学习的优劣,从而选出最优feature。这种方法并不会降低training time,只会降低scoring time,prediction time。其计算量非常大。 - embedding methods
如“decision tree” 或是 “在objective function中嵌入L1 normalization”。
这种方法,是对前两种方法的一种balance,既不会导致计算量非常庞大,也不会不考虑将model fitting。


















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











