







 博客介绍了Spark运行环境,重点讲解local本地运行环境搭建,包括解压压缩包、修改配置文件等步骤。还编写了类似MapReduce的WordCount案例,分析其逻辑,介绍RDD操作,通过链式编程简化操作,最终完成TOP10数据分析。
博客介绍了Spark运行环境,重点讲解local本地运行环境搭建,包括解压压缩包、修改配置文件等步骤。还编写了类似MapReduce的WordCount案例,分析其逻辑,介绍RDD操作,通过链式编程简化操作,最终完成TOP10数据分析。
XY个人记
我们知道Spark的运行环境有:Spark运行环境 local:本地运行 standalone:spark自带的资源管理框架 yarn mesos,下面是Spark各种运行环境的安装步骤。
local 本地运行环境搭建
1.解压spark编译好的压缩包,并重命名
$ tar -zxf spark-2.0.2-bin-hadoop2.7.3.tgz -C /opt/modules/apache/
$ mv spark-2.0.2-bin-hadoop2.7.3 spark-2.0.2
2. 修改配置文件
$ cp spark-env.sh.template spark-env.sh
JAVA_HOME=/opt/modules/jdk1.7.0_67
SCALA_HOME=/opt/modules/apache/scala-2.11.8
HADOOP_CONF_DIR=/opt/modules/apache/hadoop-2.7.3/etc/hadoop
SPARK_LOCAL_IP=hadoop01.com
3. 测试自带案例
./bin/run-example SparkPi --计算圆周率
./bin/run-example SparkPi 100 --增加次数增加准确性
4. 启动spark命令行
./bin/spark-shell
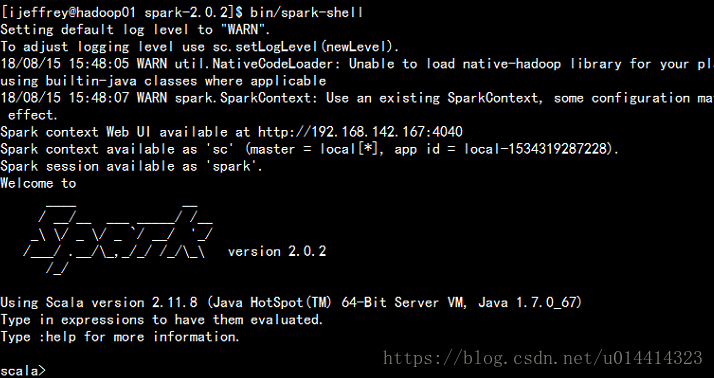
如果我们在启动一个shell 发现它为我们重启开启了一个新的端口4041
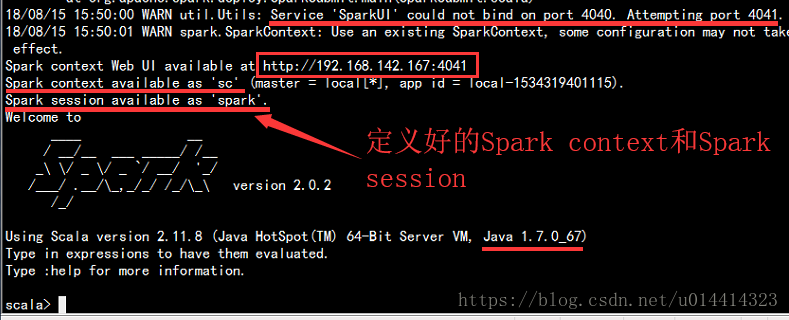
5. 可选:修改日志打印级别
cp log4j.properties.template log4j.properties
修改:
og4j.logger.org.apache.spark.repl.Main=INFO
编写类似MapReduce的案例 -- WordCount
分析逻辑:
1. 读取文件,单词之间用空格分割
2. 将文件里单词分成一个一个单词
3. 一个单词,计数为1,采用二元组计数word ->(word,1)
4. 聚合统计每个单词出现的次数
RDD的操作
1.读取文件
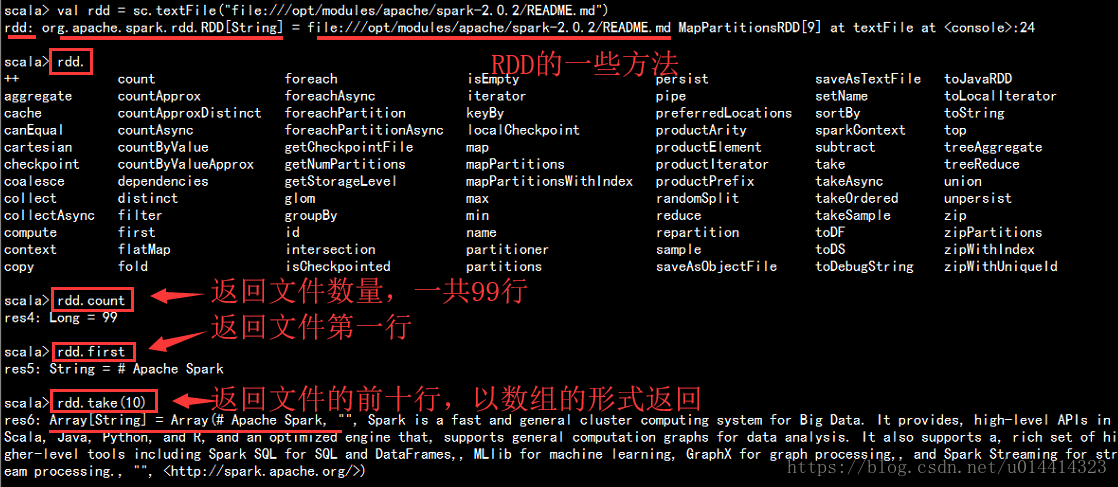
scala>val rdd = sc.textFile("file:///opt/modules/apache/spark-2.0.2/README.md")
#如果没有指定schema默认是从HDFS文件系统读取路径
定义一个变量rdd,下面是rdd相应的方法
2.使用空格进行拆分
scala> rdd.map(line => line.split(" "))
res7: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[10] at map at <console>:27
res7是进行split操作返回的类型,返回的类型还是一个RDD的数组类型 RDD[Array[String]]
scala> val flatMapRdd = rdd.flatMap(line => line.split(" "))
flatMapRdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[12] at flatMap at <console>:26
flatMapRdd 是使用flatMap进行一个扁平化的操作,返回的类型是一个RDD的字符,是我们想要的结果
scala> flatMapRdd.filter(word => word.nonEmpty)
3. 将每个单词进行计数
scala> val mapRdd = flatMapRdd.map(word => (word,1))
mapRdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[15] at map at <console>:28
4. 将相同的单词放在一起进行value值得聚合
scala> val reduceRdd = mapRdd.reduceByKey((a,b) => a + b)
reduceRdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[16] at reduceByKey at <console>:30
打印看一下每个RDD的结果

5.综上所述,我们可以进行一步链式编程及简化操作。
val res1 = sc.textFile("file:///opt/modules/apache/spark-2.0.2/README.md").flatMap(line => line.split(" ")).filter(word => word.nonEmpty).map(word => (word,1)).reduceByKey((a,b) => a + b).collect
简化操作:
val res2 = sc.textFile("file:///opt/modules/apache/spark-2.0.2/README.md").flatMap(_.split(" ")).filter(_.nonEmpty).map((_,1)).reduceByKey(_ + _).collect
6.取出单词最多的前10个元素
res6.sortBy(t => t._2,ascending=false).take(10)
sortBy函数:第一个匿名函数表示按照元组的第二个元素进行排序,ascending=false表示按照降序排序,如果不指定这个
参数,默认是升序的排序
也可以使用sortByKey,但是他是根据key排序的,所以要将我们的上面获取到的rdd使用swap进行一个反转
res6.map(t => t.swap).sortByKey(ascending=false).map(t => t.swap).take(10)
也可以用top(10)代替sortByKey(ascending=false).take(10)这一部分
res6.map(t => t.swap).top(10).map(t => t.swap)
综上所述,实现如下:
val res2 = sc.textFile("file:///opt/modules/apache/spark-2.0.2/README.md").flatMap(_.split(" ")).filter(_.nonEmpty).map((_,1)).reduceByKey(_ + _).map(_.swap).top(10).map(_.swap)
运行结果:

这样就完成了我们的TOP10数据分析操作。

















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









