







论文:《Deep Neural Networks for YouTube Recommendations》
基于物品、用户的召回方法,在得到i2i及u2u的相似性矩阵之后,还需要进行协同过滤召回才能得到召回结果,而YoutubeDNN双塔模型直接通过用户向量与物品向量的相似度计算得到召回结果。
相信很多小伙伴已经看过相关的文章,这篇文章主要目的在于阐述一些其他人很少关注但却是极其重要的点,当然也包括很多人提到点:
- 推荐的流程
- 召回模型的本质
- 负采样的注意事项
- 为什么召回要分成离线training和在线serving?为什么在线serving可以用Faiss这样的工具来代替?
PS:我觉得这篇论文的思想简直就是深度学习应用至推荐系统的工程教科书。
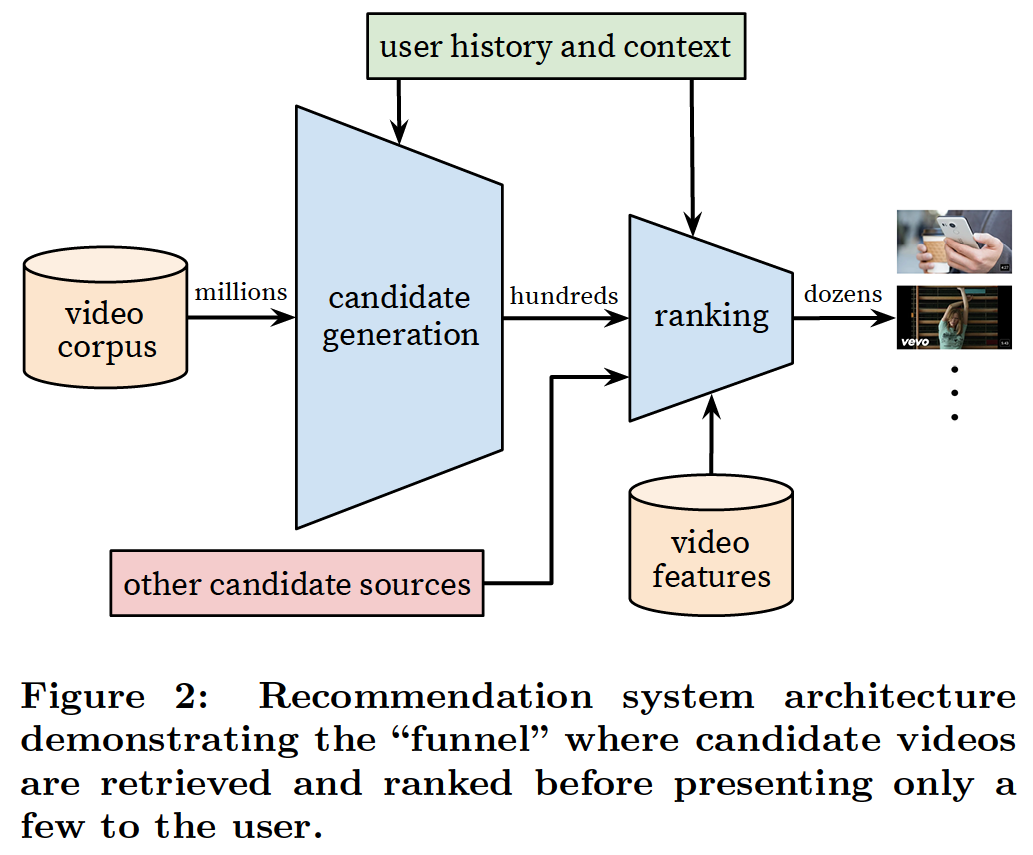
这张图就很清晰地阐述整个推荐系统的流程:
- 从百万量级的视频库,根据用户的特征及上下文信息,通过召回模型,筛选出用户可能感兴趣的少量视频,称为候选集(百量级);
- 接着,再通过排序模型,将上一步的候选集,进行排序,最终呈现给用户。
这个框架不知道是不是深度学习推荐系统的鼻祖(未去验证),但只能说,直到如今,很多还是沿用着这个框架。(现在可能还会加入粗排、重排等步骤)
二、召回层
1、召回网络
首先,需要定义召回网络的目标,如下公式:U代表用户,C代表上下文信息,V代表视频
那么召回网络的目标即可以理解为预测对于一个用户,在当前的上下文场景下,观看每个视频的概率。
这就相当于转化于一个多分类问题了。
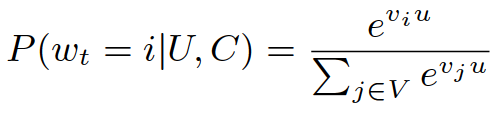
召回模型的整体结构还是比较简单的:
- 输入层是用户观看视频序列的embedding mean pooling、搜索词的embedding mean pooling、地理位置embedding、用户特征;
- 输入层给到三层激活函数位ReLU的全连接层,然后得到用户向量;
- 最后,经过softmax层,得到每个视频的观看概率。
(这一层的offline training和online serving是非常关键的点,下文详细展开)
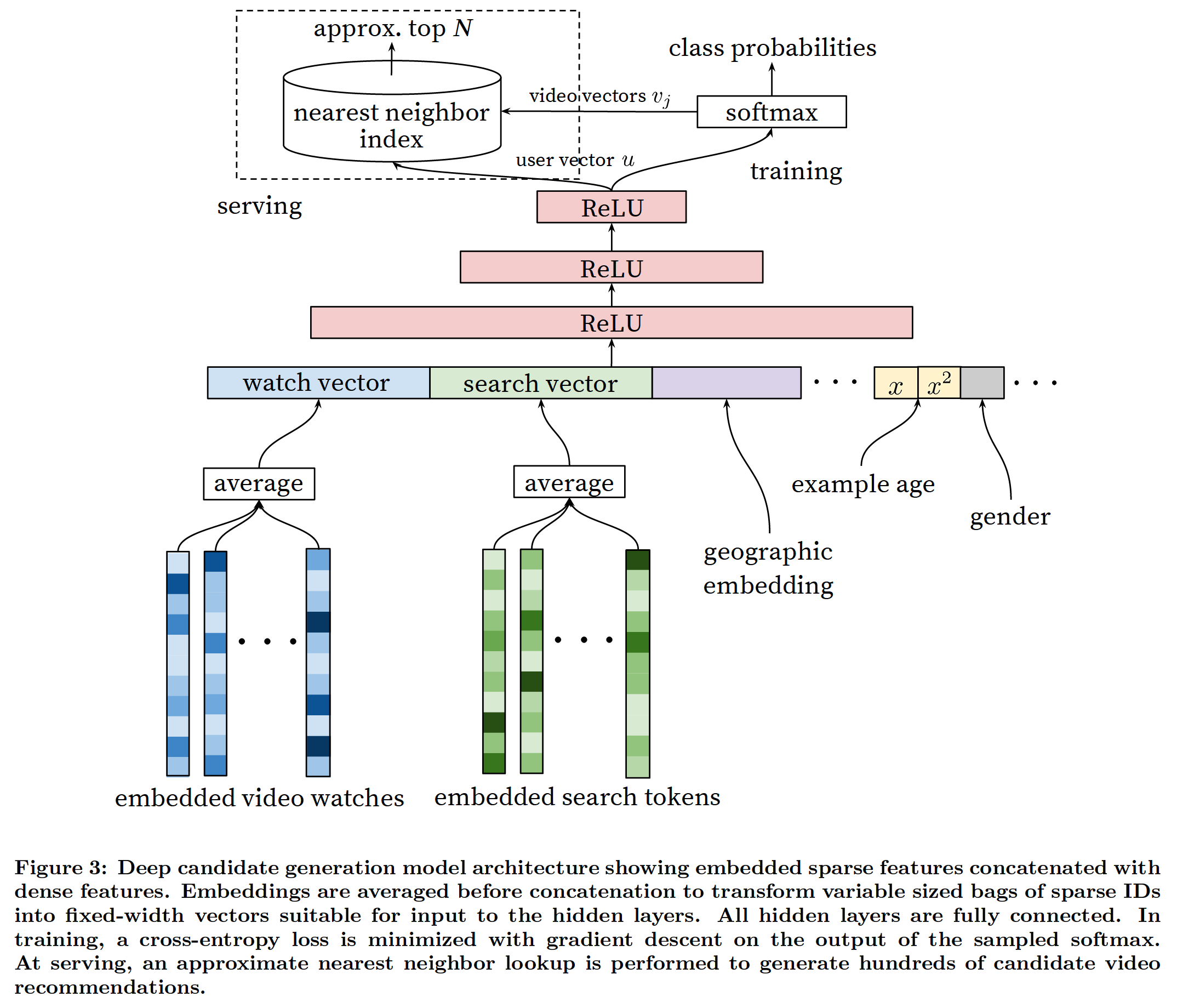
从图中看出在网络结构方面YoutubeDNN并没有做什么创新,他的创新点在于:
- 架构图的左上角,为了加快召回的速度,根据User embedding和item imbedding使用nearest neighbor search 的方法召回;
- 在softmax采用负采样;
下面仔细讲解是怎么得到User embedding和item imbedding向量:
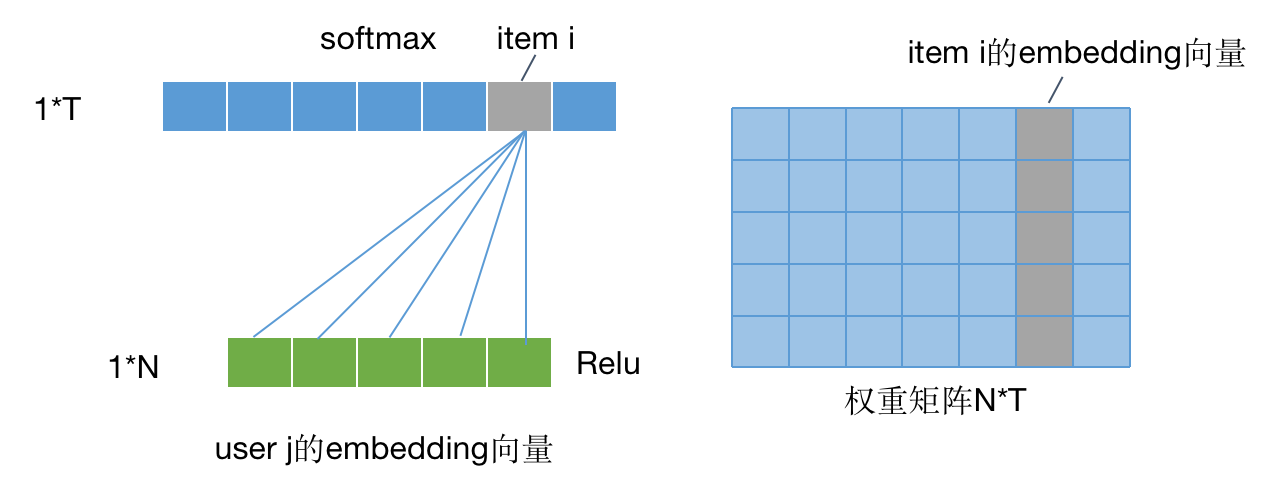

YoutubeDNN规定:
- 每个用户的embedding向量为每个用户对应的样本的softmax层前一层的Relu激活后的向量,即图中绿色部分。
- 而item对应的向量为最后一层与softmax的权重矩阵中,该item对应的位置所在的列,图中灰色部分。
user embedding 与 item embedding的乘积越大,证明该用户对该item的兴趣越大。
优势有两点:
- 所以可以提前将User Embedding和video Embedding存储到线上内存数据库,通过内积运算再排序的方法得到video的排名,以此来提高召回速度和效率。
- 通过计算用户和物品的Embedding相似度,Embedding可以直接作为推荐系统的召回层或者召回方法之一。
2、工程部分
下面,我列举出几个关键的工程部分:
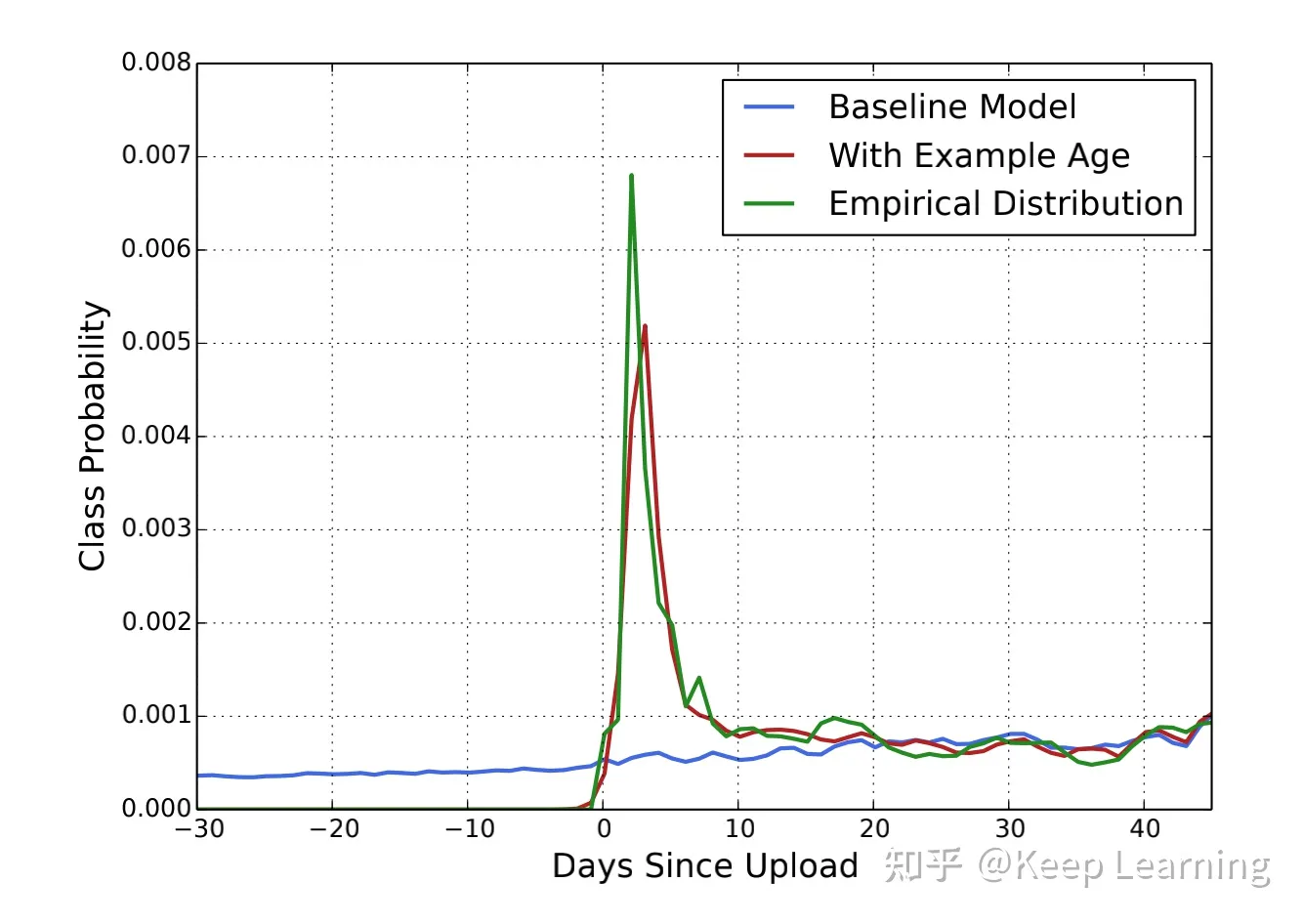
2.1 模型增加视频年龄的特征
首先,YouTube发现用户偏爱于新鲜的视频;其次,视频流行度的分布是非常不平稳的:即视频在刚发布时,更受用户喜爱,随着发布时间的越发久远,受喜爱趋势就会快速下降,但baseline模型在一段时间的训练窗口内,却是表现得很平稳(该窗口内预测概率的平均)
所以为了修复这个问题,模型加入视频年龄的特征,即视频的发布时间,实验结果也证明是有效的;
2.2 训练样本
训练样本不仅从推荐系统中抽取,还从Youtube的所有视频相关场景下获取,这样可以减少冷启动的视频;
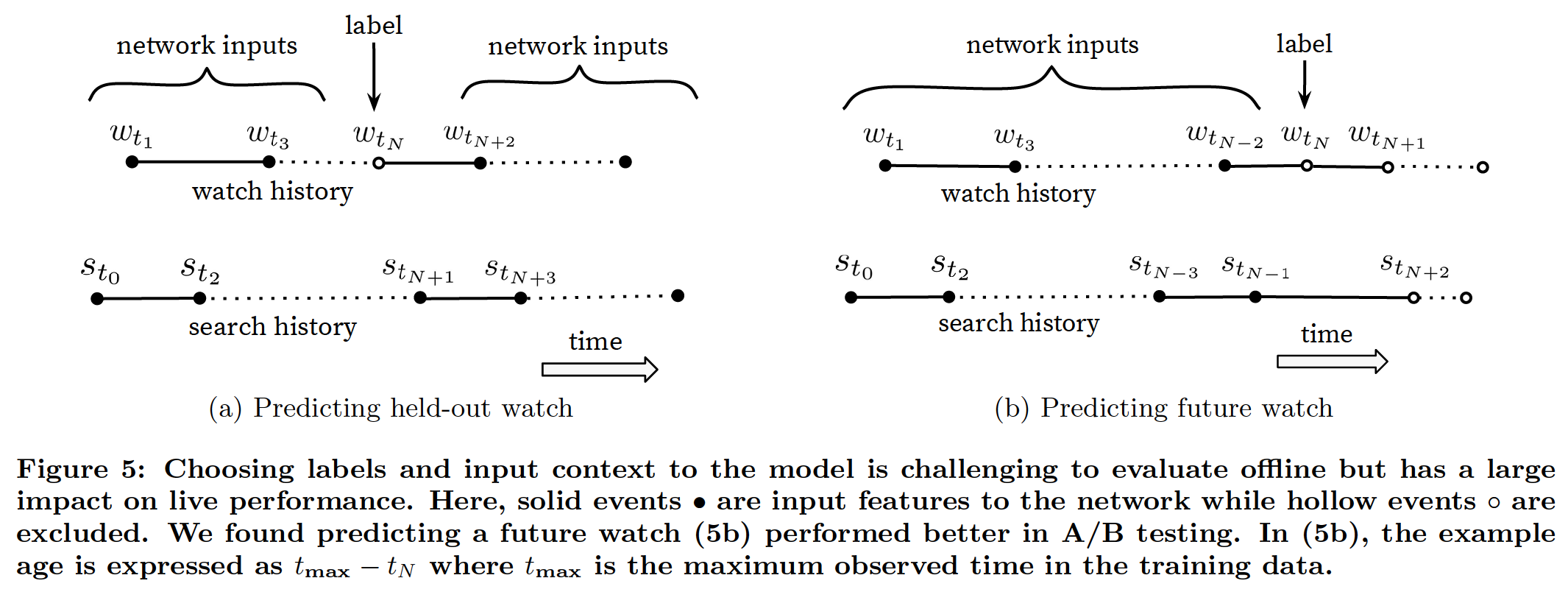
2.3 上下文和标签选择
Youtube发现用户一开始都会范围比较广地浏览各种视频,然后再专注于一个比较小的范围内。(应该是从探索到发现喜爱),这是一种不对称的浏览行为,所以,相对于从观看序列中随机抽取一个作为label(下图a),即忽略这种不对称性又缺失未来的信息,
把序列的最后一次观看作为label(下图b)会更适合
2.4 负采样
上面也提到:召回网络的目标即可以理解为预测对于一个用户,在当前的上下文场景下,观看每个视频的概率。
那么,对于每个样本来说,所有视频都可能是正样本。假如有100W个视频,那么召回模型就变成一个100W分类模型了,这显然带来了很大的训练难度。
所以,就需要用到负采样了,论文这里讲得比较模糊,大概思路就是:
- 把100W分类调整为K级别的分类;
- 正样本如上述方法提取,负样本则从视频库中根据重要性抽样;
- 这里分享下个人的拙见:本人也负责过召回模型的研发,一开始为了方便排序模型的处理,就从曝光未点击的样本进行负采样,作为召回模型和排序模型的负样本。离线训练时,召回模型的指标都还挺好,但上线之后,发现推荐与用户画像根本搭不上边。所以,召回模型的负采样必须要包含从全量item抽取的部分(easy negative samples),但一般还需要包括另外一部分hard negative samples。
- 为什么呢?主要是为了与真实场景统一,很好理解,真实的召回场景本来就是从全量item库中进行推荐,而不是从小部分item(如曝光非点击的item)。并且曝光的item是由上一个版本的召回模型决定,会导致长尾效应,推荐越来越“窄”;
- 另外,hard negative samples是为了在召回模型大方向正确的前提下,能够增加模型的训练难度,增强个性化推荐能力。一般会使用推荐流曝光位置靠中的未点击item。
2.5 softmax层
这一节本来应该也属于工程部分的,但它实在是论文的精华,就单拎出来讲了。包括双塔模型DSSM也是同样的套路。
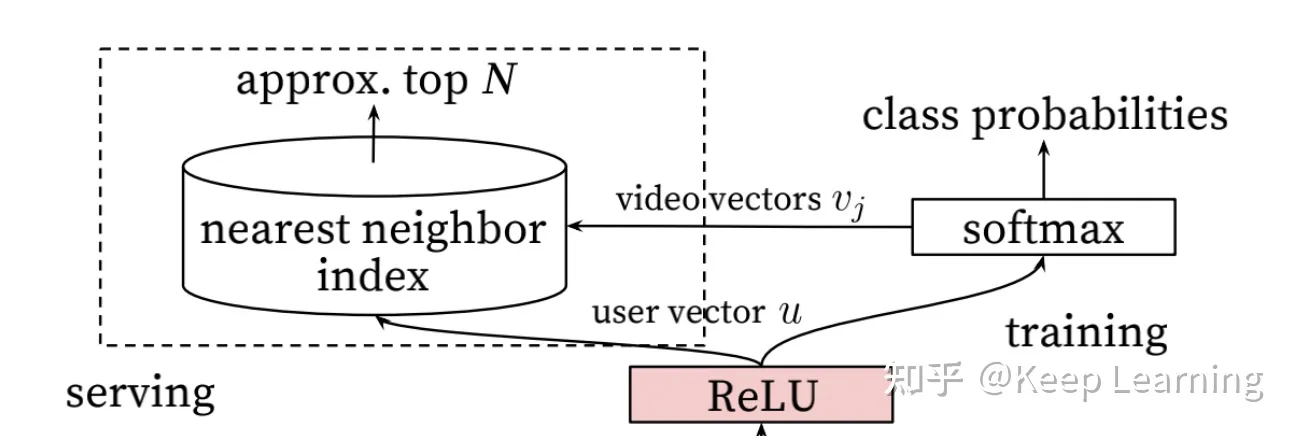
到ReLU全连接层得到用户向量u这一步,都还是很清晰易懂的。
2.6 离线training部分
- 向量u接softmax激活的全连接层,得到概率分布,多么标准的多分类输出:P = softmax(uW)
很多没真正做过召回模型的同学,包括很多文章,到这里就“点到为止”了。
- 其实这里的W,不是随便配的权重,而就是视频的向量V,怎么理解:
![]()
用户向量u与每个视频向量v进行内积,就得到用户观看每个视频的概率,然后选择最大的作为模型预测输出。
2.7 在线serving部分
- 首先,先理解为什么要拆分offline和online呢?主要原因还是工程的妥协,想象线上预测时,把所有视频都塞进模型进行计算,然后再得到概率最高的n个作为召回结果,这得消耗多大的性能,十分不合理。
那么,在线serving怎么做呢?
- 一般情况下,视频(item)不会发生什么改变,而用户则不同,他的浏览行为一直在改变,偏好可能一直在变化,所以,视频(item)向量则通过离线training之后,将其存储在数据库,而用户向量则通过模型实时计算得到;
- 得到用户向量之后,为了与离线training保持一致,仍然要与每个视频(item)向量进行内积运算,然后得到观看概率最高的n个,此时Annoy、Faiss等工具就派上用场了,它们其实就是输入用户向量,通过各种优化手段,近似得与每个视频(item)向量进行内积计算,这就是为什么在线serving时可以用Annoy&Faiss来代替的原因了。
Keep Learning:推荐系统的向量检索工具: Annoy & Faiss
三、排序模型
论文后面还提到了排序部分,但如今排序模型已经是迭代得很厉害了,例如XDeepFM、DIN、Transformer等等,在这里就不展开讲了。
四、总结
再重述一下文章的几个点,如果看到这里还有不清楚的地方,可以再往上翻翻:
- 推荐的流程
- 召回模型的本质
- 负采样的注意事项
- 为什么召回要分成离线training和在线serving?为什么在线serving可以用Faiss这样的工具来代替?
https://datawhalechina.github.io/fun-rec/#/
重读Youtube深度学习推荐系统论文,字字珠玑,惊为神文 - 知乎
Task3:召回模型 YoutubeDNN, DSSM - 知乎
DSSM 和 YoutubuDNN 召回模型及 Torch-RecHub 代码实战 - Junwei_Kuang - 博客园
【Pytorch基础教程31】YoutubeDNN模型解析-云社区-华为云
YoutubeDNN详解_蓝色仙女的博客-优快云博客_youtuobednn
DSSM、YoutubeDNN-推荐系统小结_dssm原理_seetimee的博客-优快云博客
https://www.youtube.com/watch?v=oORdDAs6abI
北大博士后【人工智能入门到精通】-18.youtubeDNN模型-AI算法专家金牌讲师卢菁-【百万年薪计划】算法深度学习机器神经网络量化投资计算机视觉推荐系统自_哔哩哔哩_bilibili

















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









