




 本文介绍了推荐系统中经典的双塔模型,包括DSSM和YouTubeDNN。DSSM最初用于NLP领域的语义相似度计算,但在推荐系统中常用于用户与物品的匹配。双塔模型结构简单,但无法处理特征交叉,可能导致效果受限。文章探讨了模型优化技巧,如归一化、温度系数、负样本采样策略,以及YouTubeDNN中的特征处理和工业经验,强调了新鲜度、噪声处理和规模挑战。
本文介绍了推荐系统中经典的双塔模型,包括DSSM和YouTubeDNN。DSSM最初用于NLP领域的语义相似度计算,但在推荐系统中常用于用户与物品的匹配。双塔模型结构简单,但无法处理特征交叉,可能导致效果受限。文章探讨了模型优化技巧,如归一化、温度系数、负样本采样策略,以及YouTubeDNN中的特征处理和工业经验,强调了新鲜度、噪声处理和规模挑战。
DSSM、YoutubeDNN-推荐系统小结
双塔模型在推荐领域中是一个十分经典的模型,无论是在召回还是粗排阶段,都会是首选。这主要是得益于双塔模型结构,使得能够在线预估时满足低延时的要求。但也是因为其模型结构的问题,使得无法考虑到user和item特之间的特征交叉,使得影响模型最终效果,因此很多工作尝试调整经典双塔模型结构,在保持在线预估低延时的同时,保证双塔两侧之间有效的信息交叉。
1.经典双塔模型:DSSM
DSSM(Deep Structured Semantic Model)是由微软研究院于CIKM在2013年提出的一篇工作,该模型主要用来解决NLP领域语义相似度任务 ,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和query匹配的问题。DSSM 模型的原理主要是:通过用户搜索行为中query 和 doc 的日志数据,通过深度学习网络将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之 间的余弦相似度,从而训练得到隐含语义模型,即 query 侧特征的 embedding 和 doc 侧特征的 embedding,进而可以获取语句的低维 语义向量表达 sentence embedding,可以预测两句话的语义相似度。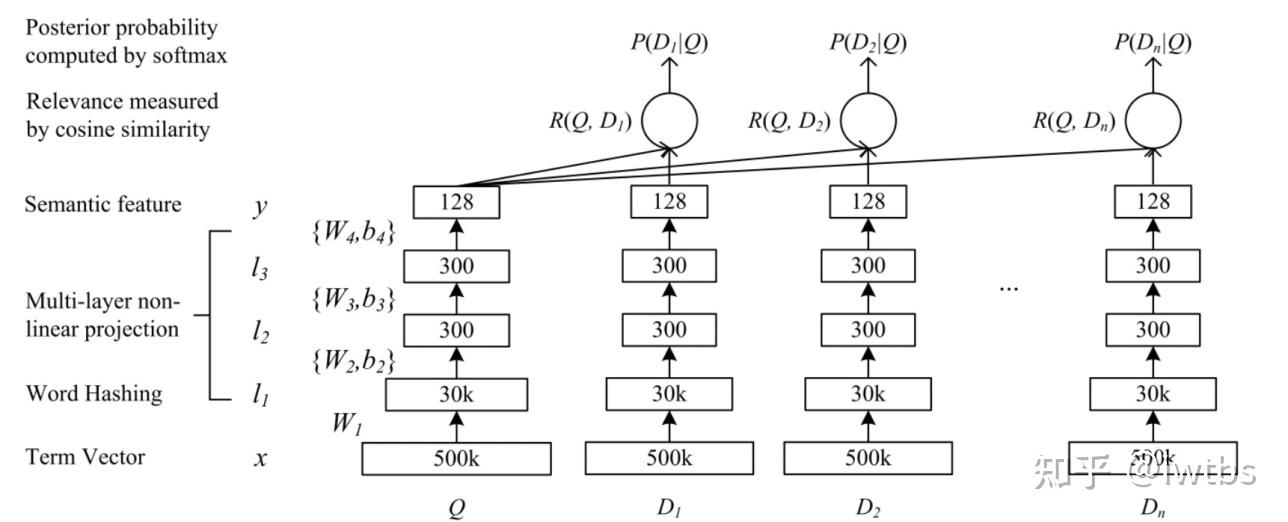
该网络结构比较简单,是一个由几层DNN组成网络,我们将要搜索文本(Query)和要匹配的文本(Document)的 embedding 输入到网络,网络输出为 128 维的向量,然后通过向量之间计算余弦相似度来计算向量之间距离,可以看作每一个 query 和 document 之间相似分数,然后在做 softmax。
而在推荐系统中,最为关键的问题是如何做好用户与item的匹配问题
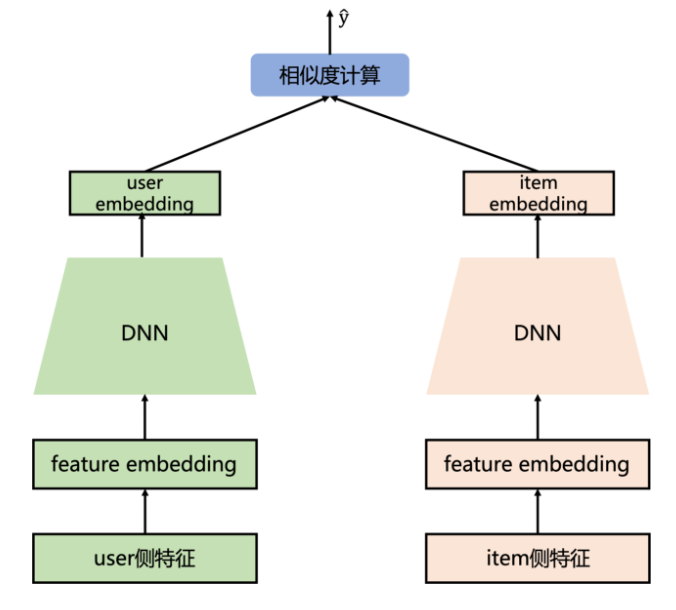
需要注意的是:对于user和item两侧最终得到的embedding维度需要保持一致,即最后一层全连接层隐藏单元个数相同。
在召回模型中,将这种检索行为视为多类分类问题,类似于YouTubeDNN模型。将物料库中所有的item视为一个类别,因此损失函数需要计算每个类的概率值:
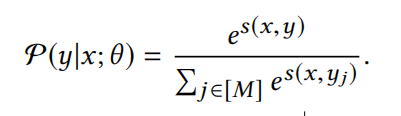
其中s*(x,y)表示两个向量的相似度,P(y∣x;θ)表示预测类别的概率,M表示物料库所有的item。但是在实际场景中,由于物料库中的item数量巨大,在计算上式时会十分的耗时,因此会采样一定的数量的负样本来近似计算。
以上就是推荐系统中经典的双塔模型,之所以在实际应用中非常常见,是因为在海量的候选数据进行召回的场景下,速度很快,效果说不上极端好,但一般而言效果也够用了。之所以双塔模型在服务时速度很快,是因为模型结构简单(两侧没有特征交叉),但这也带来了问题,双塔的结构无法考虑两侧特征之间的交互信息,在一定程度上牺牲掉模型的部分精准性。例如在精排模型中,来自user侧和item侧的特征会在第一层NLP层就可以做细粒度的特征交互,而对于双塔模型,user侧和item侧的特征只会在最后的內积计算时发生,这就导致很多有用的信息在经过DNN结构时就已经被其他特征所模糊了,因此双塔结构由于其结构问题先天就会存在这样的问题。
1.1双塔模型细节
1.1.1归一化与温度系数
在Google的双塔召回模型中,重点介绍了两个trick,将user和item侧输出的embedding进行归一化以及对于內积值除以温度系数,实验证明这两种方式可以取得十分好的效果。那为什么这两种方法会使得模型的效果更好呢?
-
归一化:对user侧和item侧的输入embedding,进行L2归一化
u ( x , θ ) ← = u ( x , θ ) ∣ ∣ u ( x , θ ) ∣ ∣ 2 u(x,\theta) \leftarrow = \frac{u(x,\theta)}{||u(x,\theta)||_2} u(x,θ)←=∣∣u(x,θ)∣∣2u(x,θ)
v ( x , θ ) ← = v ( x , θ ) ∣ ∣ v ( x , θ ) ∣ ∣ 2 v(x,\theta) \leftarrow = \frac{v(x,\theta)}{||v(x,\theta)||_2} v(x,θ)←=∣∣v(x,θ)∣∣2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1439
1439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









