






分而治之。
马其顿的菲利普二世
本章介绍如何利用现代商品化的多核系统的优势,通过使用惯用法或“设计模式”[Ale79,GHJV95,SSRB00]来平衡性能、可扩展性和响应时间。正确划分的问题可以产生简单、可扩展且高性能的解决方案,而划分不当的问题则会导致缓慢且复杂的解决方案。本章将帮助你设计分区方法。 将这些内容融入你的代码中,同时讨论批处理和弱化的问题。“设计”这个词非常重要:你应该先进行分区,然后是批处理,接着是弱化,最后才是编码。改变这个顺序通常会导致性能和可扩展性下降,还会带来极大的挫败感。
1.对经典“哲学家用餐”问题的限制,要求所有哲学家能够同时用餐。
2.基于锁的双端队列实现,当队列中有很多元素时,它可以在给定队列的两端提供并发操作,但当队列中只有少数元素时,它仍然能正确工作。(或者,就此而言,没有元素。)
3.仅用几个数字来总结并发算法的粗略质量。
5.当前设计适用于未完全分区的应用程序。
为此,第6.1节 给出了分区练习,第6.2节 评审可分割性设计标准,第6.3节 讨论同步粒度选择,第6.4节 概述了重要的并行快速路径设计模式,这些模式在使用更简单的“慢路径”回退来处理异常情况的同时,在常见情况下提供了速度和可伸缩性,最后是第6.5节 简要地看一下分区之外的内容。
每当一种理论出现在你面前,作为唯一可能的理论时,把它当作一个信号,表明你既没有理解这个理论,也没有理解它想要解决的问题。
卡尔·波普尔
尽管分区比20世纪初更广为人知,但其价值仍被低估。第6.1.1节 因此对经典的“哲学家用餐”问题和第6.1.2节进行了更深入的探讨 重新访问双端队列。
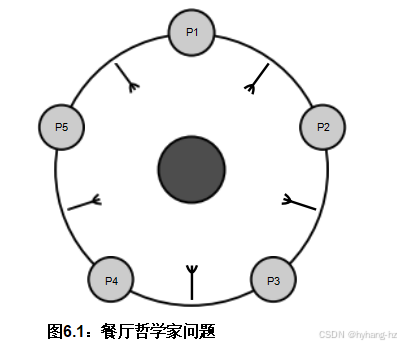
图6.1 展示了一个经典的“哲学家用餐”问题[Dij71]的图表。这个问题涉及五个哲学家,他们除了思考和吃一种“非常难吃的意大利面”外什么都不做,而这种意大利面需要两把叉子才能吃完。 一个哲学家只被允许使用他或她左右的叉子,但不会放下一个叉子,直到他或她满足为止。
目标是构建一个算法,真正防止饥饿。一种饥饿的情况是所有哲学家同时拿起他们最左边的叉子。因为没有人会在吃完饭之前放下他们的叉子,而且没有人可以在至少一个哲学家吃完饭后才拿起第二个叉子,所以他们都饿了。请注意,仅仅允许至少有一个哲学家吃饭是不够的。如图6.2所示。 研究表明,即使是少数哲学家的饥饿也应避免。
迪杰斯特拉的解决方案使用了一个全局信号量,这在减少微不足道的通信延迟方面是有效的,但这一假设在20世纪80年代末或早期变得无效

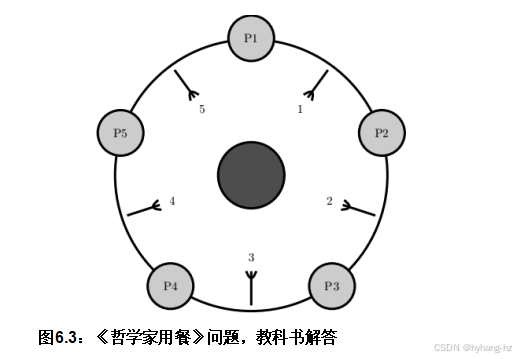
1990s . 3 最近的解决方案将分支编号,如图6.3所示。 每位哲学家依次拿起自己盘子旁编号最低的叉子,然后拿起另一只叉子。图中位置最高的哲学家首先拿起最左边的叉子,接着是右边的叉子;而其他哲学家则先拿起自己的右边的叉子。由于有两位哲学家会尝试先拿1号叉子,但只有其中一位能成功,因此四位哲学家将共有五个叉子可用。至少有一位哲学家会有两把叉子,从而能够进食。
这种按数字顺序对资源进行编号和获取的通用技术被大量用作防止死锁的技术。然而,很容易想象一系列事件,即使所有哲学家都饿了,也会导致只有一个哲学家同时进食:
1. P2拾取叉子1,防止P1取叉子。
2. P3拾取叉2。
3. P4拿起叉子3。
4. P5拾取叉4。
5. P5拿起叉子5并吃。
6. P5适用于小学四年级和五年级。
7. P4拿起叉子4并吃起来。
简而言之,这个算法只能让一个哲学家在某一时刻进食,即使五个哲学家都饿了,尽管有足够的叉子让两个哲学家同时进食。应该有可能做得更好!
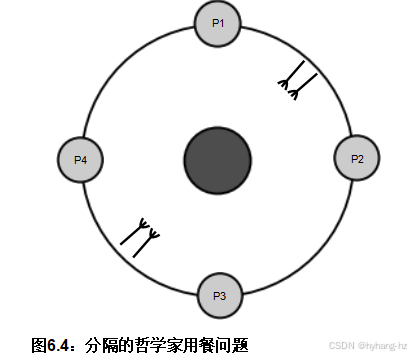
一种方法如图6.4所示 这包括四位哲学家而不是五位,以便更好地说明分区技术。这里最上方和最右侧的哲学家共享一对叉子,而最下方和最左侧的哲学家则共享另一对叉子。如果所有哲学家同时感到饥饿,至少会有两位能够同时进食。此外,如图所示,现在可以将叉子捆绑在一起,使得一对叉子可以同时被拿起和放下,简化了获取和释放算法。

这是“横向并行性”[Inm85]或“数据并行性”的一个例子,之所以这样命名是因为哲学家之间的关系没有相互依赖。在横向并行的数据处理系统中,给定的数据项只会被复制的软件组件集中的一个处理。
![]()
双端队列是一种数据结构,包含一个元素列表,可以从中任一端插入或移除[Knu73]。有观点认为,基于锁的实现允许同时在双端队列两端进行并发操作是困难的[Gro07]。本节将展示如何通过分区设计策略实现一个相对简单的实现方法,接下来将探讨三种通用的方法。但首先,我们该如何验证一个并发的双端队列?
6.1.2.1双端队列验证
一个好的起点是不变量。例如,如果元素a被推入双端队列的一端,然后从另一端弹出,这些元素的顺序必须保持不变。同样地,如果元素被推入队列的一端,然后从同一端弹出,这些元素的顺序必须反转。任何从队列中弹出的元素都必须是最近才被推入该队列的,如果队列清空,所有被推入队列的元素都必须已经被弹出。
并发双端队列测试套件(“deqtorture.h”)的初始版本提供了以下检查:
1.CHECK_SEQUENCE_PAIR()提供的元素排序检查。
2.检查最近由melee()提供的元素是否被弹出。
3.检查在队列清空之前是否已将被压入的元素弹出,也由melee()提供。
本套件包括顺序测试和并发测试。虽然这个套件对于教科书代码来说已经足够好,但是您应该对用于生产环境的代码进行更彻底的测试。第11章和第12章介绍了大量的验证工具和技术。
但是,有了原型测试套件,我们已经准备好在接下来的章节中研究双端队列算法。
6.1.2.2 左手和右手锁
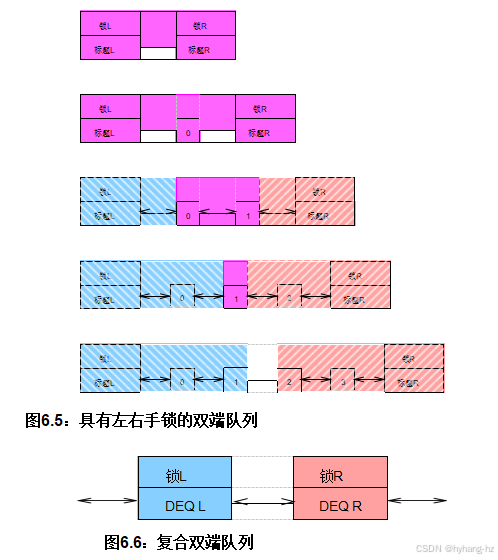
一种看似简单的处理方法是使用双向链表,左端队列和出队操作使用左锁,右端操作使用右锁,如图6.5所示。 然而,这种方法的问题在于当列表中元素少于四个时,双锁域必须重叠。这种重叠是因为移除任何一个给定元素不仅会影响该元素本身,还会对其左右相邻的元素产生影响。这些域在图中用颜色表示,蓝色带向下条纹表示左锁域,红色带向上条纹表示右锁域,紫色(没有条纹)表示重叠域。尽管可以设计出这样的算法,但考虑到它至少有五个特殊情况,这应该是一个很大的警示信号,尤其是在列表另一端的并发活动随时可能将队列从一个特殊情况转移到另一个特殊情况的情况下。因此,考虑其他设计要好得多。
6.1.2.3复合双端队列
强制不重叠的锁域的一种方法如图6.6所示。 两个双端队列并行运行,每个双端队列都由自己的锁保护。这意味着元素必须偶尔从一个双端队列转移到另一个双端队列,在这种情况下,必须同时持有两个锁。可以使用简单的锁层次结构
为了避免死锁,例如,在获取右侧锁之前总是先获取左侧锁。这比在同一双端队列上应用两个锁要简单得多,因为我们可以无条件地将元素左移入左侧队列,右移入右侧队列。主要的复杂情况出现在从空队列出队时,此时需要:
1.如果握着右手锁,松开它并获得左手锁。
2.获取右侧锁。
3.重新平衡两个队列中的元素。
4.如果存在,则删除所需元素。
5.释放两个锁。

生成的代码(locktdeq.c)相当直接。重新平衡操作可能会将某个元素来回传递于两个队列之间,浪费时间,可能需要依赖工作负载的启发式方法来获得最佳性能。尽管在某些情况下这可能是最好的方法,但尝试设计一个更确定性的算法仍然很有意义。
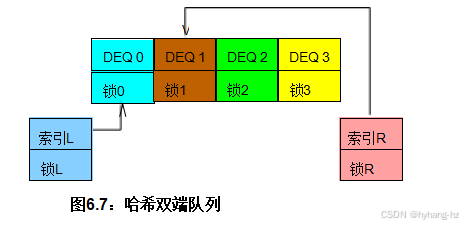
6.1.2.4哈希双端队列
确定性地划分数据结构最简单且有效的方法之一是对其进行哈希处理。可以轻松地对双向队列进行哈希处理,通过根据每个元素在列表中的位置分配一个序列号来实现,使得第一个左入空队列的元素编号为零,第一个右入空队列的元素编号为一。一系列左入其他空队列的元素会被赋予递减的数字(-1,-2,-3,.. .),而一系列右入其他空队列的元素则会被赋予递增的数字(2,3,4,.. .)。关键在于,无需实际表示给定元素的编号,因为这个编号会由其在队列中的位置隐含。
根据这种方法,我们为左索引分配一个锁,为右索引分配一个锁,为每个哈希链分配一个锁。图6.7 显示了给定四个哈希链的结果数据结构。请注意,锁域d不重叠,并且
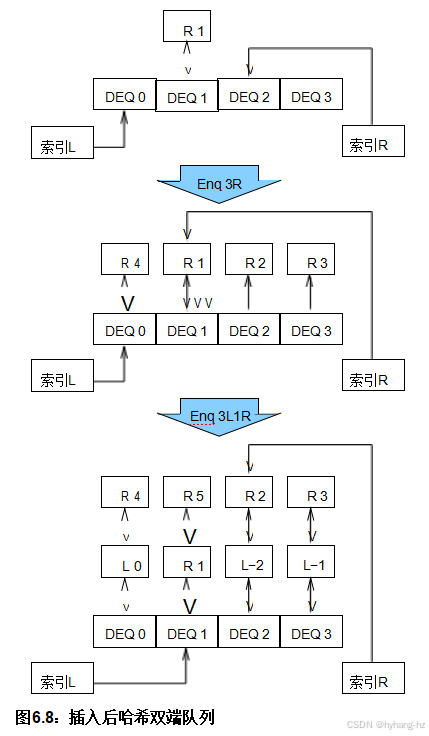
发现结果为非NULL,第10行记录新的左手索引。不管怎样,第11行 释放锁,最后,第12行 如果存在元素,则返回该元素,否则返回NULL。
第29行– 38 showpdeq_push_l(),将指定元素放入队列。第33行 获取左手锁,以及第34行 拾起左手食指。第35行 将指定元素左移并放入由左索引索引的双队列中。行36 然后更新左侧索引和第37行 释放锁。
如前所述,右侧操作与左侧操作完全类似,因此分析这部分内容留待读者自行完成。
![]()
6.1.2.5复合双端队列再探
本节重新审视复合双端队列,使用一个简单的重新平衡方案,将所有元素从非空队列移动到当前空队列。

与上一节中介绍的哈希实现不同,复合实现将基于一个不使用锁或原子操作的双向队列的顺序实现。
清单6.3 显示了实现。与哈希实现不同,这种复合实现是非对称的,因此我们必须分别考虑pdeq_pop_l()和pdeq_pop_r()实现。

pdeq_ pop_l()的实现如第1行所示 – 16 图中的线条5 获取左侧锁,该线14 发布。第6行 尝试从左端的双端队列中左出一个元素,如果成功,则跳过行8 – 13 简单地返回此元素。否则,第8行 获取右侧锁,第9行 从右队列中删除一个元素,以及行10 将右手队列中的任何剩余元素移动到左手队列中,第11行 初始化右侧队列,以及第12行 释放右侧锁。如果存在元素,则在第9行从队列中出队将被退回。
pdeq_ pop_r()的实现如第18行所示 – 38 图中的数字。和以前一样,第22行 获取右手锁(和第36行 发布i t),以及第23行 尝试从右队列中右出一个元素,如果成功,则跳过第25行 – 35仅仅返回此元素。但是,如果第24行 确定没有元素要出队,第25行 释放右侧锁和线路26 – 27按正确的顺序获取两个锁。第28行 然后尝试从右列表中再次右出队一个元素,如果第29行 确定此第二次尝试失败,第30行 从左队列(如果有可用的)中右出队一个元素,第31行 将左队列中剩余的元素移动到右队列中,并行32 初始化左侧队列。无论如何,第34行 释放左手锁。


Thepdeq_push_l()实现如第40行所示 – 45见清单6.3。 第42行 获取左手旋转锁,行43 left-en将元素放入左侧队列,最后行44 释放锁。Thepdeq_push_r()实现(在第47行显示 – 52)非常相似。

6.1.2.6 双端队列讨论
与第6.1.2.4节中介绍的哈希变体相比,复合实现更为复杂。 但仍然相当简单。当然,更智能的重新平衡方案可以任意复杂,但这里展示的简单方案已被证明与软件替代方案相比表现良好[DCW+11],甚至与使用硬件辅助的算法相比也表现出色[DLM+10]。然而,我们能期望这种方案的最佳性能是2倍的可扩展性,因为最多只有两个线程可以同时持有队列的锁。这一限制同样适用于基于非阻塞同步的算法,例如迈克尔提出的基于比较和交换的队列算法[ Mic 03]。
事实上,正如Dice等人[DLM+10]所指出的,一个不同步的单线程双向队列显著优于他们研究的所有并行实现。因此,关键在于无论采用何种实现方式,向共享队列中排队或出队都可能产生显著的开销。鉴于这些队列严格遵循先进先出(FIFO)的原则,这一点并不令人意外。
此外,这些严格的FIFO队列仅在线性化点上严格遵循FIFO[HW90]6 这些对调用者来说是不可见的,在事实上,这些线性化点被埋藏在基于锁的关键段中。这些队列对于(比如说)各个操作开始的时间而言,并不是严格遵循先进先出的原则[HKLP12]。这表明,在并发程序中,严格的先进先出属性并非那么有价值,实际上,Kirsch等人提出了较为宽松的队列,提供了更好的性能和可扩展性[KLP12]。7 尽管如此,如果你在推动所有
通过单个队列使用并发程序的数据,您确实需要重新考虑您的整体设计。
第6.1.1节快速测验答案中给出的就餐哲学家问题的最佳解决方案 是一个“横向并行”或“数据并行”的绝佳例子。在这种情况下,同步开销几乎(甚至完全)为零。相比之下,双端队列实现则是“纵向并行”或“流水线”的例子,因为数据从一个线程移动到另一个线程。流水线所需的更紧密协调反过来又需要更大的工作单元来达到一定的效率水平。

这两个例子说明了划分在设计par allel算法方面是多么强大。第6.3.5节简要介绍第三个例子,即矩阵乘法。然而,这三个例子都要求并行程序有更多更好的设计准则,这一主题将在下一节中讨论。
学习一磅需要十磅常识来应用它。
波斯谚语
获得最佳性能和可扩展性的方法之一是不断优化,直到找到最佳的并行程序。然而,如果你的程序不是微乎其微,那么可能的并行程序的数量将如此庞大,以至于在宇宙的寿命内无法保证收敛。此外,“最佳的并行程序”到底是什么意思?毕竟,第2.2节中列出了至少三个并行编程的目标:性能、生产力和通用性,而最佳的性能可能会以牺牲生产力和通用性为代价。显然,我们需要在设计时能够做出更高层次的选择,以便在该程序过时之前,能够达到一个令人满意的并行程序。
然而,要实际产生一个现实世界的设计,需要更详细的设计标准,这一任务将在本节中进行。由于这是现实世界,这些标准往往在不同程度上相互冲突,要求设计师仔细权衡由此产生的折衷。
因此,这些标准可以被看作是作用于设计的“力量”,而这些力量之间特别好的权衡被称为“设计模式”[Ale79,GHJV 95]。
实现三个并行编程目标的设计标准是:加速、竞争、开销、读写比和复杂度:
加速比:如第2.2节所述,提高性能是进行并行化所需付出全部时间和努力的主要原因。加速比定义为运行顺序版本程序所需时间与运行并行版本程序所需时间之比。
争论:如果一个并行程序使用的CPU多于该程序能够保持忙碌的CPU数量,那么多余的CPU将因争用而无法执行有用的工作。这可能是锁争用、内存争用或许多其他性能杀手。
工作与同步比率:单处理器、单线程、不可抢占且不可中断的8 给定并行程序的某个版本不需要任何同步原语。因此,这些原语所消耗的时间(包括通信缓存未命中、消息延迟、锁定原语、原子指令和内存屏障)都是间接的开销,不会直接贡献于程序预期完成的有效工作。需要注意的是,关键在于同步开销与临界区代码开销之间的关系,较大的临界区能够容忍更大的同步开销。工作与同步的比例与同步效率的概念有关。
读写比:一种很少更新的数据结构通常会被复制而不是分区,而且可能通过不对称同步原语进行保护,这些原语以牺牲写入者的同步开销为代价减少读取者的同步开销,从而降低整体同步开销。对于频繁更新的数据结构,相应的优化也是可行的,如第五章所述。
复杂性:并行程序比等效的顺序程序更复杂,因为并行程序的状态空间远大于顺序程序。尽管具有规律结构的大状态空间在某些情况下可以容易理解,但并行程序员必须考虑同步原语、消息传递、锁定设计、临界区识别和死锁等问题,在这个更大的状态空间背景下进行处理。
这种更高的复杂性通常会转化为更高的开发和维护成本。因此,预算限制可能会减少对现有程序进行修改的数量和类型,因为给定程度的加速只能带来有限的时间和麻烦。更糟糕的是,增加的复杂性实际上会降低性能和可扩展性。
因此,超过某个点后,可能存在比并行化更便宜且更有效的顺序优化。如第2.2.1节所述,并行化只是众多性能优化之一,而且更易于应用于基于CPU的瓶颈问题。
请注意,这些标准也可能作为需求规范的一部分出现,并且它们是总结并发算法质量问题的一个解决方案,见第113页。 例如,加速可以作为相对需求(“越快越好”)或工作负载的绝对要求(“系统必须支持每秒至少1,000,000次网络访问”)。经典的设计模式语言将相对需求描述为力,而将绝对要求描述为上下文。
了解这些设计标准之间的关系,对于确定并行程序的适当设计权衡非常有帮助。
1.程序在独占锁关键部分花费的时间越少,潜在的加速就越大。这是Amdahl定律的结果[Amd 67],因为在给定的时间内,只有一个CPU可以在一个给定的独占锁关键部分执行。
更具体地说,对于无界线性扩展而言,程序在给定的独占临界区中花费的时间比例必须随着CPU数量的增加而减少。例如,除非一个程序在最严格的独占锁临界区中的时间少于十分之一,否则它无法扩展到10个CPU。
2.当实际加速比小于可用CPU数量时,争用效应会消耗多余的CPU时间和/或时间。CPU数量与实际加速比之间的差距越大,CPU使用效率就越低。同样地,期望的效率越高,可实现的加速比就越小。
3.如果可用的同步原语相对于它们保护的关键部分具有较高的开销,提高速度的最佳方法是减少这些原语被调用的次数。这可以通过批量处理关键部分、使用数据所有权(见第8章)、使用非对称原语(见第9章)或采用粗粒度设计如代码锁定来实现。
4.如果关键部分的开销比保护它们的基本操作高,那么提高加速的最佳方法是通过移动到读/写锁定、数据锁定、不对称或数据所有权来增加并行性。
5.如果临界区的开销相对于保护它们的原语来说较高,并且被保护的数据结构被读取的次数远多于修改的次数,则提高并行性的最佳方法是转向读/写锁定或不对称原语。
6.许多改进SMP性能的改变,例如减少锁保留,也改善了实时延迟[McK05c]。

值得重申的是,竞争包括各种形式,包括锁竞争、内存竞争、缓存溢出、热限制等。本章主要探讨锁竞争和内存竞争。
做好小事是做好大事的一步。
哈里·F·班克斯
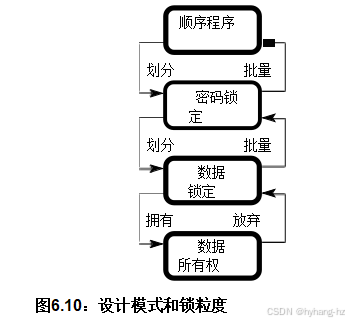
图6.10 给出了不同同步粒度级别的图示视图,每个级别都在以下各节中进行了描述。这些章节主要关注锁定,但所有形式的同步都存在类似的粒度问题。
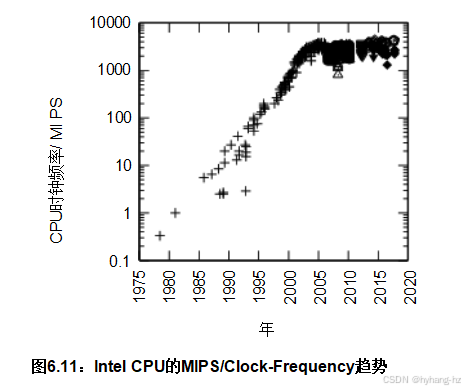
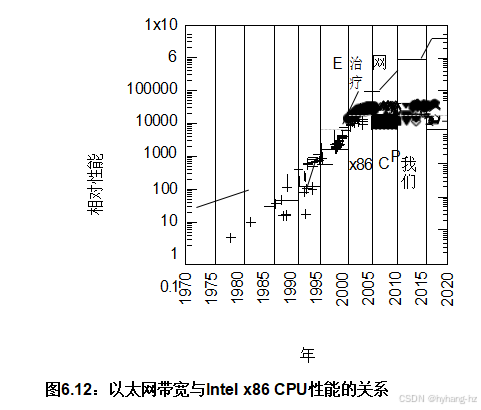
如果程序在单个处理器上运行足够快,并且不与其他进程、线程或中断处理程序交互,你应该移除同步原语,以节省它们带来的开销和复杂性。几年前,有人认为摩尔定律最终会迫使所有程序都属于这一类。然而,如图6.11所示,事实并非如此。 在2003年左右,单线程性能的指数级增长停止了。因此,提高性能将越来越需要并行性。10 考虑到2006年保罗在一台双核笔记本电脑上首次使用了这个句子的第一个版本,再加上2020年添加的许多图表是在每个插槽有56个硬件线程的系统上生成的,可以看出并行计算已经真正普及。同样重要的是,以太网带宽仍在持续增长,如图6.12所示。 这种增长将继续激励多线程服务器来处理通信负载。
请注意,这并不意味着您应该以多线程方式编写每个程序。同样,如果一个程序在一个单处理器上运行得足够快,那么请不要浪费自己在SMP同步定时器上所花费的开销和复杂性。
| 清单6.4:顺序程序哈希表搜索 |
| 1 structhash_table 2{ 3 longnbuckets; 4个结构节点**桶;5} 6 7类型定义结构节点{ 8个未签名的长密钥; 9结构节点*next;10}node_t; 11 12 int hash_search(structhash_table *h,长密钥)13{ 14结构节点*cur;15 16 cur=h->buckets[key%h->nbuckets]; 17 while(cur!=NULL){ 18如果(cur->key>=key){ 19返回(cur->key ==key);20} 21 cur=cur->next; 22} 23 return0; 24} |
| 清单6.4中的哈希表查找代码的简洁性 强调这一点. 11 一个关键点是,由于并行性而产生的加速通常仅限于CPU的数量。相比之下,由于顺序优化而产生的加速,例如精心选择的数据结构,可以任意大。 |
| 快速测试6.15:如何验证哈希表? |
| 另一方面,如果你没有处于这种幸福的状态,请继续阅读! 由于代码锁定仅使用全局锁,因此它非常简单。12 特别容易将现有程序改造以使用代码锁定,以便在多处理器上运行。如果程序只有一个共享资源,代码锁定甚至可以提供最优性能。然而,许多更大更复杂的程序需要大部分执行发生在关键部分,这反过来又导致代码锁定严重限制了它们的可扩展性。 因此,对于那些执行时间中只有很小一部分用于关键部分或只需要适度扩展的程序,你应该使用代码锁定。此外,主要采用后续章节中描述的可扩展方法的程序,通常会使用代码锁定来处理罕见的错误情况或重要的状态转换。在这种情况下,代码锁定将提供一个相对简单的程序,其与顺序版本非常相似,如清单6.5所示。 但是请注意,在清单6.4的hash_ search()中,比较的简单返回 由于需要在返回之前释放锁,现在变成了三个语句。 请注意,hash_loc k获取和释放语句位于第19行, 24 ,和29 在希望并发访问哈希表的CPU之间进行哈希表所有权的调解 |
1spinlock_thash_lock; 2
3 structhash_table 4{
5 longnbuckets;
6个结构节点**桶;7};
8
9类型定义结构节点{
10个未签名的长密钥;
11结构节点*next;12}node_t;
13
14 int hash_search(structhash_table *h,长键)15{
16个结构节点*cur;
17 intretval; 18
20 cur=h->buckets[key%h->nbuckets];
21 while(cur!=NULL){
22如果(cur->key>=key){
24spin_unlock(&hash_lock);
25 returnretval; 26}
27 cur=cur->next; 28}
30 return0;
31}
访问哈希表。另一种理解方式是,hash_lock分配了时间分区,因此每个请求的CPU在拥有该哈希表期间都有自己的时间分区。此外,在设计良好的算法中,应该有足够多的时间分区,在这些时间里没有CPU拥有该哈希表。
不幸的是,代码锁定特别容易发生“锁竞争”,即多个CPU需要同时获取锁。那些照顾过小孩(或像孩子一样行事的老年人)的SMP程序员会立即意识到只有某样东西的一个副本存在的危险,如图6.13所示。
下面的章节中介绍了一种名为“数据锁定”的解决方案。
许多数据结构可以被分区,每个分区都有自己的锁。这样,数据结构的每个部分的关键段可以并行执行,尽管在给定时间只能有一个实例执行某个部分的关键段。当需要减少竞争且同步开销不会限制加速时,应使用数据锁定。数据锁定通过将过大的关键段实例分布在多个数据结构中来减少竞争,例如,在哈希表中为每个哈希桶维护关键段,如清单6.6所示。 可扩展性的增加再次导致复杂性略有增加,形式为额外的数据结构,即结构桶。 与图6.13所示的争议情况相反
如图6.14所示,数据锁定有助于促进和谐。 在并行程序中,这一点几乎是正确的

| 1 structhash_table 2{ 3 longnbuckets; 4个结构桶**个桶;5个; 6 7个结构桶bucket{ 8spinlock_tbucket_lock; 9node_t*list_head;10}; 11 12类型定义结构节点{ 13个未签名的长密钥; 14结构节点*next;15}node_t; 16 17 int hash_search(structhash_table *h,长键)18{ 19个结构桶*bp; 20个结构节点*cur; 21 intretval; 22 23 bp = h->桶[key%h->nbuckets]; 24spin_lock(&bp->bucket_lock); 25 cur=bp->list_head; 26 while(cur!=NULL){ 27如果(cur->key>=key){ 28 retval=(当前->key==键); 29spin_unlock(&bp->bucket_lock); 30 returnretval; 31} 32 cur=cur->next; 33} 34spin_unlock(&bp->bucket_lock); 35 return0; 36} |

图6.14:数据锁定
总是转化为性能和可扩展性的增加。因此,Sequentin在其内核中大量使用了数据锁定[ BK85,In m85,Gar90,Dov90,MD92,MG 92,MS 93]。
另一种看待这个问题的方式是将每个->桶锁视为仅管理与该->桶锁对应的桶的所有权,而不是像代码锁定那样管理整个哈希表的所有权。每个锁仍然划分时间,但每桶锁定技术还划分了地址空间,因此整个技术可以被认为是在划分时空。如果桶的数量足够多,这种空间划分应该能够以高概率允许特定CPU间接访问某个哈希桶。
然而,正如照顾过小孩的人可以再次证明的那样,即使提供足够的资源也无法保证平静的生活。类似的情况也可能出现在SMP程序中。例如,Linux内核维护了一个文件和目录缓存(称为“dcache”)。缓存中的每个条目都有自己的锁,但与根目录及其子目录对应的条目比那些较为冷门的条目更可能被访问。这可能导致许多CPU争夺这些热门条目的锁,从而导致类似图6.15所示的情况。
在许多情况下,可以设计算法来减少数据偏斜的实例,在某些情况下甚至完全消除它(例如,在Linux内核的dcache[MSS04,Cor10a,Bro15a,Bro15b,Bro15c]中)。数据锁定常用于可分区的数据结构,如哈希表,以及多个实体各自由给定数据结构的一个实例表示的情况。Linux内核的任务列表就是一个例子,每个任务结构都有自己的alloc_锁和pi_锁。
在动态分配的结构上使用数据锁定的一个关键挑战是确保在获取锁时结构仍然存在[GKAS99]。清单6.6中的代码 通过将锁放置在静态分配的哈希桶中来解决这一挑战,这些哈希桶永远不会被释放。然而,如果哈希表是可重置的,那么这个技巧就不起作用了,因为此时锁现在是动态分配的。在这种情况下,

图6.15:数据锁定和偏斜
需要有一些方法来防止在获取锁期间释放哈希桶。
数据所有权将给定的数据结构分配到各个线程或CPU上,使得每个线程/CPU可以独立访问其子集的数据结构,而无需任何同步开销。然而,如果一个线程希望访问其他线程的数据,则第一个线程无法直接访问。相反,第一个线程必须与第二个线程通信,让第二个线程代表第一个线程执行操作,或者将数据迁移到第一个线程。
数据所有权可能看起来很晦涩,但它被经常使用:
1.仅由一个CPU或线程可访问的变量(例如Cand C++中的自动变量)属于该CPU或进程。
2.用户界面的实例拥有相应用户的上下文。应用程序与并行数据库引擎交互时,通常被编写得像完全顺序程序一样。这些应用程序拥有用户界面及其当前操作。因此,显式的并行性仅限于数据库引擎本身。
3.参数化模拟通常通过授予每个线程对参数空间的特定区域的所有权而简单地并行化。也有为这类问题设计的计算框架[Uni08a]。
如果存在大量共享,线程或CPU之间的通信可能会导致显著的复杂性和开销。此外,如果最常使用的数据恰好由单个CPU拥有,该CPU将成为“热点”,有时结果类似于图6.15所示。 然而,在不需要共享的情况下,数据所有权可以实现理想的性能,并且使用代码
可以像清单6.4中所示的顺序程序那样简单。 这种情况通常被称为“令人尴尬的平行”,在最好的情况下,类似于之前图6.14中所示的情况。
另一个重要的数据所有权实例发生在数据被读取时,在这种情况下,所有线程都可以通过复制“拥有”它。
数据锁定分区了地址空间(每个分区有一个哈希桶)和时间(使用每个桶的锁),而数据所有权仅分区了地址空间。数据所有权无需分区时间的原因是,给定的线程或CPU被分配了特定地址空间分区的永久所有权。

数据所有权将在第8章中详细说明。
本节从数学同步效率的角度探讨锁定粒度和性能。对数学不感兴趣读者可以选择跳过本节。
该方法是使用一个粗糙的排队模型来评估基于单个共享全局变量的同步机制的效率,该模型基于M/M/1 queue.M/M/1排队模型,即“到达率”λ和“服务率”μ呈指数分布。到达率λ可以理解为系统在同步自由时每秒处理的平均同步操作次数,换句话说,λ是非同步单位工作开销的倒数。例如,如果每个工作单位是一个事务,且每个事务处理需要一毫秒的时间,不包括同步开销,则λ为每秒1000个事务。
服务率μ的定义类似,但它是系统在每个事务开销为零的情况下每秒处理的平均同步操作次数,忽略CPU之间必须等待以完成其同步操作这一事实。换句话说,μ可以大致理解为在没有竞争的情况下同步开销。例如,假设每个事务的同步操作涉及一个原子增量指令,并且计算机系统能够在每个CPU上每5纳秒执行一次私有变量的原子增量(见图5.1 )。13 因此,μ的值约为每秒200,000,000个原子增量。
当然,随着越来越多的CPU增加一个共享变量,ofλ值就会增加,因为每个CPU都能够独立地处理事务(再次忽略同步):
λ = nλ 0 (6.1)
这里,n是CPU的数量,λ0是单个CPU的事务处理能力。请注意,在没有竞争的情况下,单个CPU执行单个事务的预期时间为1/λ0。
因为CPU必须“等待”在彼此后面才能获得增加单个共享变量的机会,我们可以使用M/M/1排队模型来表达预期的总等待时间:

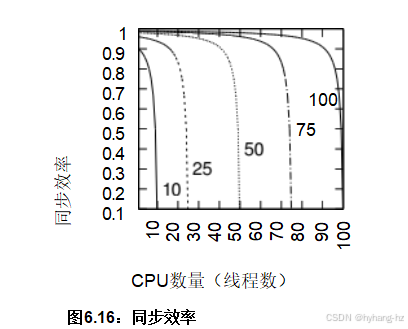
图6.16 绘制了同步效率e与CPU/线程数n的关系图,针对几个开销比f的值。例如,在使用5纳秒原子增量时,f = 10的线表示每个CPU每50纳秒尝试一次原子增量,而f= 100的线则表示每个CPU每500纳秒尝试一次原子增量,这进而
对应着数百(或许数千)条指令。鉴于每条跟踪随着CPU或线程数量的增加急剧减少,我们可以得出结论,在当前的商用硬件上大量使用基于单个全局共享变量原子操作的同步机制将无法良好扩展。这是第五章讨论的并行计数算法背后力量的抽象数学描绘。实际应用中可能会有所不同。
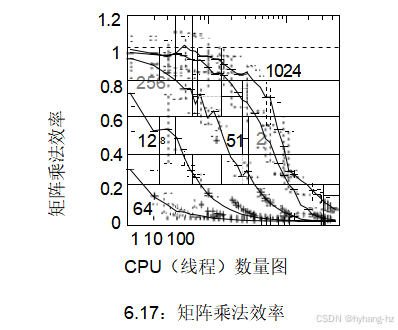
然而,效率的概念仍然有用,即使在几乎没有或完全没有正式同步的情况下也是如此。以矩阵乘法为例,其中一个矩阵的列与另一个矩阵的行相乘(通过“点积”),结果是第三个矩阵的一个元素。由于这些操作之间没有冲突,可以将第一个矩阵的列分配给一组线程,每个线程计算结果矩阵中对应的列。因此,线程可以完全独立运行,没有任何同步开销,正如在matmul .c中所做的那样。因此,可以预期完美的效率为1.0。
然而,图6.17 讲述了一个不同的故事,特别是对于64乘64矩阵乘法,即使在单线程运行时,其效率也从未超过0.3,而且随着更多线程的加入而急剧下降。14 128×128矩阵表现更好,但增加线程后性能提升不大。256×256矩阵的扩展性尚可,但仅限于少数几颗CPU。512×512矩阵的乘法效率在10个线程时明显低于1.0,而1024×1024矩阵乘法在几十个线程时也明显偏离完美状态。尽管如此,这一数据清楚地展示了批量处理带来的性能和可扩展性优势:如果必须承担同步开销,不妨物有所值,这正是第113页提出的关于同步粒度选择问题的解决方案。

鉴于这些低效性,值得研究一些可内扩展的方法,例如第6.3.3节中描述的数据锁定或者采用下一节中讨论的并行快速路径方法。

面对困难有两种方法:改变困难,或者改变自己去面对困难。
菲莉丝·博托姆
细粒度(因而通常性能更高)的设计通常比粗粒度设计更复杂。在许多情况下,大部分开销是由一小部分代码造成的[Knu73]。那么为什么不把精力集中在那小部分上呢?
这是并行快速路径设计模式背后的理念,即在不增加整个算法复杂度的情况下,积极地并行化常见情况下的代码路径。你不仅需要了解希望并行化的具体算法,还要考虑该算法将面临的负载。构建一个并行快速路径通常需要极大的创造力和设计努力。
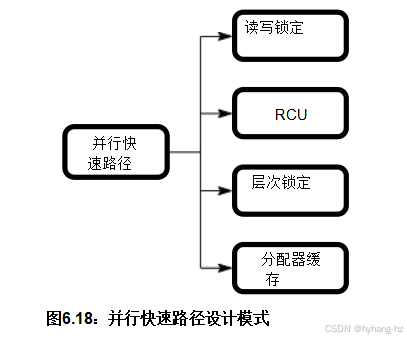
并行快速路径结合了不同的模式(一个用于快速路径,另一个用于其他地方),因此是一个模板模式。以下并行快速路径实例经常出现
足以证明它们自身的模式,如图6.1 8所示:
1.读写锁定(下文第6.4.1节中描述) .
| 清单6.7:读写锁定哈希表搜索 |
| 1rwlock_thash_lock; 2 3 structhash_table 4{ 5 longnbuckets; 6个结构节点**桶;7} 8 9类型定义结构节点{ 10个未签名的长密钥; 11结构节点*next;12}node_t; 13 14 int hash_search(structhash_table *h,长密钥)15{ 16个结构节点*cur; 17 intretval; 18 19read_lock(&hash_lock); 20 cur=h->buckets[key%h->nbuckets]; 21 while(cur!=NULL){ 22如果(cur->key>=key){ 23 retval=(cur->key == key); 24read_unlock(&hash_lock); 25 returnretval; 26} 27 cur=cur->next; 28} 29read_unlock(&hash_lock); 30 return0; 31} |
2.读取副本更新(RCU)可以在第9.5节中作为高性能的读写锁定替代方案。其他替代方案包括危险指针(第9.3节)和序列锁定(第9.4节)。本章不再进一步讨论这些替代方案。
3.层次锁定([ McK96a]),在第6.4.2节中提及。
4.资源分配器缓存([ McK96a,MS93])。请参见第6.4.3节 更多详细信息。
如果同步开销可以忽略不计(例如,程序使用粗粒度并行处理且临界区较大),并且只有少量的临界区会修改数据,那么允许多个读取器并行执行可以显著提高可扩展性。写入器排除了其他所有读取器。有许多读写锁的实现方式,包括第4.2.4节中描述的POSIX实现。清单6.7 展示了如何使用读写锁定实现哈希搜索。
读写锁定是一种简单的非对称锁定实例。Snaman[ST87]描述了一种更复杂的六模式非对称锁定设计,它被用于几个集群系统中。一般而言,以及特别地,读写迭代锁定在第7章中进行了详尽的描述。
层次锁定背后的理念是拥有一个粗粒度的锁,它只持有足够长的时间来决定获取哪个细粒度的锁。清单6.8 如何显示
我们的哈希表搜索可能被调整为进行层次锁定,但也显示了这种方法的巨大弱点:我们已经支付了获取第二个锁的开销,但我们只持有它很短的时间。在这种情况下,数据锁定方法会更简单,而且很可能表现得更好。
![]()
本节介绍了一个并行固定块大小内存分配器的简化示意图。更详细的描述可以在文献[MG92,MS93,BA 01,MSK 01,Eva 11,Ken 20]或Linux内核[Tor 03]中找到。
6.4.3.1并行资源分配问题
并行内存分配器面临的基本问题是,在一般情况下,需要提供极快的内存分配和释放,同时需要在不利的分配和释放模式下有效地分配内存。
要了解这种紧张关系,可以考虑将数据所有权直接应用于这个问题——简单地划分内存,让每个CPU拥有自己的份额。例如,假设一个有12个CPU的系统有64g内存,那么
我正在使用的笔记本电脑。我们可以简单地为每个CPU分配5吉字节的内存区域,并允许每个CPU从自己的区域内分配内存,而无需锁定及其复杂性和开销。不幸的是,当CPU 0仅分配内存而CPU 1仅释放内存时,这种方案就会失败,这在简单的生产者-消费者工作负载中经常发生。
另一种极端,即代码锁定,由于锁竞争过多和开销过大而受到困扰[MS93]。
6.4.3.2 并行快速路径用于资源分配
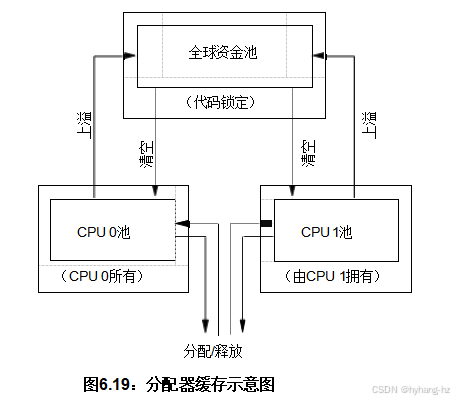
常用的解决方案采用并行快速路径,每个CPU拥有少量缓存块,并且有一个大型代码锁定共享池用于额外的块。为了防止任何给定的CPU独占内存块,我们限制了每个CPU缓存中可以包含的块数量。在双CPU系统中,内存块的流动如图6.19所示。 :当某个CPU试图释放一个块时,如果其池已满,它会将块发送到全局池;同样地,当该CPU试图分配一个块时,如果其池为空,它会从全局池中提取块。
6.4.3.3 数据结构
“玩具”实现的分配器缓存的实际数据结构如清单6.9所示 (“smpalloc.c”)。图6.19中的“全局池”。 由全局内存globalmem实现,类型为struct globalmempool,两个CPU池则由每线程变量perthreadme m实现,类型为struct perthreadmempool。这两种数据结构在其池字段中都包含指向块的指针数组,这些指针从索引零开始填充。因此,如果全局内存pool[3]为空,则从索引4开始的其余数组也必须为空。cur字段包含池数组中最高编号的完整元素的索引,或在所有元素均为空时为-1。所有
| 清单6.9:分配器-缓存数据结构 |
| 1 #define TARGET_POOL_SIZE 3 2 #define GLOBAL_POOL_SIZE 40 3 4个全局结构mempool{ 5spinlock_tmutex; 6 intcur; 7个结构memblock * pool[ GLOBAL_ POOL_ SIZE];8}全局mem; 9 每个线程10个结构mempool{ 11 intcur; 12个结构memblock * pool[2 * TARGET_ POOL_ SIZE];13}; 14 15DEFINE_PER_THREAD(每个线程的结构内存池,每个线程的内存); |
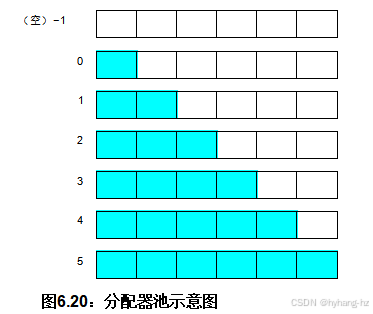
globalmem.pool[0]到globalmem.pool[globalmem.cur]中的元素必须全部满,其余的必须全部为空。15
池数据结构的操作如图6.20所示,六个方框代表构成池字段的指针数组,前面的数字表示cur字段。阴影方框表示非空指针,而空白方框表示空指针。尽管这一数据结构可能令人困惑,但一个重要的不变量是,cur字段总是比非空指针的数量少一个。
6.4.3.4功能分配
分配函数memblock_alloc()可以在清单6.10中看到。 第7行 获取当前线程的每个线程池,以及行8 检查是否为空。
如果是,第9行 – 16 尝试从在线9处获得的自旋锁下的全局池中重新填充它 并于第16行发布。 第10行 – 14 将块从全局池移动到线程池,直到本地池达到目标大小(半满)或全局池耗尽,第15行 将每个线程池的计数设置为正确的值。
在任何情况下,第18行 检查每个线程池是否仍然为空,如果不是,则行19 – 21移除一个模块并重新旋转它。否则,请参见第23行 讲述了记忆耗尽的悲惨故事。
6.4.3.5免费功能
清单6.11 显示内存块空闲功能。第6行 获取此线程的池指针,以及第7行 检查此线程池是否已满。
如果是,则第8行 – 15将每个线程池的一半空出,放入全局线程池中,第8行 和14 获取和释放自旋锁。第9行 – 12将循环移动块从本地移到全局池,并行13 将每个线程池的计数设置为正确的值。
在任何情况下,第16行 然后将新释放的块放入线程池中。

6.4.3.6 表演
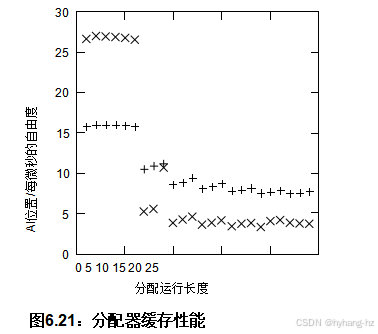
粗略性能结果16 如图6.21所示 在双核英特尔x86架构上运行,主频为1 GHz(每个CPU 4300 MIPS),每个CPU的缓存最多允许六个块。在这个微基准测试中,每个线程反复分配一组块,然后释放该组中的所有块,组内块的数量即为x轴上显示的“分配运行长度”。y轴显示每微秒成功分配/释放对的数量——失败的分配不计入。图中的“X”表示双线程运行的结果,而“+”则表示单线程运行的结果。
请注意,长度不超过六的运行线性扩展并表现出色,而超过六的运行则表现不佳,几乎总是呈现负增长。因此,确保TARGET_POOL_SIZE足够大非常重要,幸运的是,在实际操作中这通常很容易实现[MSK01],尤其是在当今的大容量内存环境下。例如,在大多数系统中,将TARGET_POOL_SIZE设置为100是相当合理的,在这种情况下,分配和释放可以保证至少99 %的时间限制在每个线程池内。
从图中可以看出,在适用通用数据所有权的情况下(运行长度不超过六个),性能比必须获取锁的情况有了很大的提高。避免通用情况下的同步将是本书的一个反复出现的主题。

快速测验6.25:在两线程测试中,当运行长度达到或超过19时观察到了分配失败。考虑到全局池大小为40,每线程的目标池大小为三个,线程数n等于两个,并假设每个线程的池最初为空且没有使用任何内存,那么最小的分配运行长度m是多少,导致了失败。
可能发生什么?(回想一下,每个线程会反复分配m块内存,然后释放这m块内存。)或者,给定n个线程,每个线程的堆大小为s,且每个线程首先反复分配m块内存,然后释放这些m块内存,全局池的大小需要多大?注意:要获得正确答案,你需要检查smpalloc .c源代码,并且很可能需要逐行执行。你已经被警告了!
6.4.3.7验证
验证这个简单的分配器会生成指定数量的线程,每个线程反复分配指定数量的内存块,然后释放它们。这种简单的方案足以锻炼每个线程的缓存和全局池,如图6.21所示。
对于要在生产环境中使用的内存分配器,需要进行更积极的验证。tcalloc[Ken20]和jemalloc[Eva11]的测试套件很有指导意义,Linux内核内存分配器的测试也是如此。
6.4.3.8 真实世界设计
玩具并行资源分配器非常简单,但现实世界的设计以无数种方式扩展了这种方法。
首先,实际的分配器需要处理广泛的分配大小,而不仅仅是这个玩具示例中显示的一个单一大小。一种流行的方法是提供一组固定的大小,这些大小的间隔是为了平衡外部和内部碎片化,例如20世纪80年代末的BSD内存分配器[MK88]。这样做意味着“globalmem”变量需要按每个大小复制一次,相关的锁也需要相应地复制,从而导致数据锁定而不是玩具程序代码的锁定。
其次,生产级系统必须能够重新利用内存,这意味着它们必须能够将块合并成更大的结构,如页面[MS93]。这种合并还需要通过锁来保护,而锁也可以按大小复制。
第三,合并后的内存必须返回到底层内存系统,同时还需要从底层内存系统分配内存页面。这一级别的锁定需求取决于底层内存系统的锁定需求,但很可能是代码锁定。在这一级别,代码锁定通常是可以接受的,因为在设计良好的系统中,这种情况很少发生[MSK01]。
并发用户空间分配器面临类似的挑战[Ken20,Eva11]。
尽管这种现实世界的设计更复杂,但其基本思想是相同的——如表6.1所示的并行快速路径的重复应用。
“并行快速路径”是第113页提出的不可分区应用程序问题的解决方案之一。
表6.1:Real-Worl d并行分配器示意图
| 等级 | 目的 | |
| 按线程池 | 数据所有权 | 高速分配 |
| 全局块池 | 数据锁定 | 在各个线程之间分配块 |
| 正在合并 | 数据锁定 | 将区块组合成页面 |
| 系统内存 | 密码锁定 | 从系统中读取/写入内存 |
如果你有足够的弹药,那么高目标是没问题的。
霍利·R·埃弗哈特
本章讨论了如何利用数据分区来设计简单的线性可扩展并行程序。第6.3.4节 暗示了数据复制的可能性,这将在第9.5节中得到很好的应用。
应用分区和复制的主要目标是实现线性加速比,换句话说,就是确保随着CPU或线程数量的增加,所需总工作量不会显著增加。通过分区和/或复制可以解决的问题之一是令人尴尬的并行问题,这会导致接近的加速比。但我们能否做得更好?
为了回答这个问题,让我们来探讨迷宫和迷阵的求解方法。当然,迷宫和迷阵作为研究对象已有数千年历史[维基12],因此使用计算机生成和解决它们也就不足为奇了,包括生物计算机[阿达11]、通用专用GPU[埃里08],甚至离散硬件[KFC11]。并行求解迷阵有时被用作大学课程项目[苏黎世11,尤尼10],以及展示并行编程框架优势的工具[Fos10]。
常见的建议是使用并行工作队列算法(PWQ)[ ETH11,Fos10]。本节通过将PWQ与顺序算法(SEQ)以及另一种并行算法进行比较来评估这一建议,所有情况下均解决随机生成的方形迷宫。第6.5.1节 讨论PWQ,第6.5.2节 讨论了另一种并行算法,第6.5.4节 分析其异常性能,第6.5.5节 从第6.5.6节的交替并行算法中推导出改进的顺序算法 进行进一步性能比较,最后见第6.5.7节 介绍了未来的发展方向和总结。
PWQ基于SEQ,如清单6.12所示 (maze_seq.c的伪代码)。迷宫由一个二维的细胞阵列和一个基于非线性阵列的工作队列命名->visited表示。
第7行访问初始单元,循环的每次迭代跨越第8行 – 21t raverses passages headed by one cell. The loop spanning lines 9 – 13 扫描scans-the->visited[]数组,寻找具有未访问邻居的已访问单元格,并在循环中跨越行14 – 19 穿过由该邻居领导的次级子网的一个分支。行20 初始化以供下次通过外循环。
maze_ try_ visit_ cell()的伪代码如第1行所示 – 12见清单6.13 (maze.c)第4行 检查c和t单元格是否相邻且相连,而第5行 检查是否还没有访问过单元t。celladdr()函数返回指定单元的地址。如果任一检查失败,行6 返回失败。第7行 表示下一个单元格,第8行 在-> visited[]数组的下一个槽中记录这个单元格,第9行 表示此插槽现已满,以及行10 将此单元格标记为已访问,并记录从该单元格的起始位置的距离。第11行 然后返回成功。
maze_ find_ any_ next_ cell()的伪代码显示在第14行 – 28 见清单6.13(maze.c)第17行 取当前单元格距离+1,而行19, 21 , 23 , 和25 检查每个方向上的电池,以及第20行, 22 , 24 , 和26 如果对应的单元格是候选下一个单元格,则返回true。prevcol()、nextcol()、prevrow()和nextrow()分别执行指定的数组-索引转换操作。如果没有任何单元格是候选单元格,则行27 返回false。
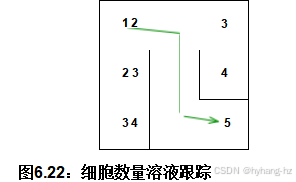
路径是通过从星点开始,计算出迷宫中单元格的数量来记录的,如图6.22所示 ,其中起始单元格位于左上角,结束单元格位于右下角。从结束单元格开始,按照连续递减的单元格编号遍历解。
| 1 int | maze_try_visit_cell(struct maze*mp,cell c,cell | t, |
| 2 | cell*n, int d) | |
| 3{ 4 | ||
| 5 | ||
| 6 | ||
| 7 | *n=t; | |
| 8 | ||
| 9 10 | mp-> vi++; | |
| 11 | ||
| 12} | ||
| 13 | ||
| 14 int | ||
| 15 | cell*n) | |
| 16{ | ||
| 17 18 | ||
| 19 | 如果(maze_try_visit_c ell(mp,c,prevcol(c),n, | |
| 20 | return1; | |
| 21 | 如果(maze_try_visit_cell(mp,c,nextcol(c),n, | |
| 22 | return1; | |
| 23 | 如果(maze_try_visit_ce ll(mp,c,prevrow(c),n, | |
| 24 | return1; | |
| 25 | 如果(maze_try_visit_cell(mp,c,nextrow(c),n, | |
| 26 | return1; | |
| 27 | return0; | |
| 28} | ||
并行工作队列求解器是清单6.12中所示算法的直接并行化 和6.13。 第10行 见清单6.12 必须使用fetch-and-add,局部变量vi必须在各个线程之间共享。第5行 和10 见清单6.13 必须组合成一个CAS环,CAS故障表示迷宫中存在环路。第8行 – 9 此列表中的所有元素都必须使用fetch-and-add来仲裁并发尝试在-> visited[]数组中记录单元格。
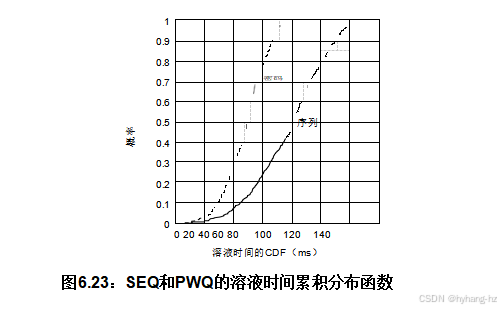
如图6.23所示,这种方法确实为运行在2.53 GHz的双CPU Lenovo W500提供了显著的加速。 显示了基于500个不同随机生成的500×500迷宫的解决方案,两种算法的累积分布函数(CDF)的累积分布函数(CDF)基于500个不同的500×500迷宫的解决方案。CDF在x轴上的投影的大量重叠将在第6.5.4节中讨论。
有趣的是,序列解路径追踪器对并行算法同样适用。然而,这揭示了并行算法的一个显著弱点:任何时候最多只有一个线程在沿解路径前进。这一弱点将在下一节中讨论。
年轻的迷宫求解者常被建议从两端开始,这一建议最近在自动迷宫求解的背景下再次被提及[Uni10]。这些建议实际上涉及分区,这种策略在并行编程中作为强大的并行化手段,不仅适用于操作系统内核[BK85,Inm85],也适用于应用程序[Pat10]。本节将采用这一策略,使用两个子线程分别从解决方案路径的两端开始,并简要探讨其性能和可扩展性的影响。
分区并行算法(PART),如清单6.14所示 (maze_part.c),与SEQ类似,但有几个重要的区别。首先,每个子线程都有自己的访问数组,由父线程通过第1行所示的passe d传递, 必须初始化为all[-1,-1]。第7行 将指向此数组的指针存储到线程变量myvisited中,以便辅助函数访问,并同样存储指向本地访问的指针
| 清单6.15:分区并行辅助程序伪代码 | |||
| 1 int | maze_try_visit_cell(s truct maze*mp, | int c, | int t, |
| 2 | int*n, int d) | ||
| 3{ | |||
| 4 | cell_tt; | ||
| 5 | cell_t*tp; | ||
| 6 | intvi; | ||
| 7 | |||
| 8 | 如果(!maze_cells_connected(mp,c, | ||
| 9 | return0; | ||
| 10 | |||
| 11 | 执行{ | ||
| 12 | |||
| 13 | 如果(t&访问过){ | ||
| 14 | 如果((t& TID)!= | ||
| 15 | mp->已完成 | ||
| 16 | return0; | ||
| 17 | } | ||
| 18 | }而(! CAS(tp,t,t| VISITED | | myid | |
| 19 | *n=t; | ||
| 20 | vi=(*myvi)++; | ||
| 21 | |||
| 22 | return1; | ||
| 23} | |||
索引。第二,父访问每个子的第一个单元格,子在第8行检索。 第三,当一个孩子找到另一个孩子已经访问过的单元格时,迷宫即被解决。当maze_try_visit_cell()检测到这一点时,它会在迷宫结构中设置一个->done字段。第四,因此每个孩子必须定期检查->done字段,如第13行所示, 18 , 和23。 TheREAD_ONCE()p rimitive必须禁用任何可能合并连续加载或重新加载值的编译器优化。C++1x可松弛的易失性加载就足够了[Smi19]。最后,maze_ find_ any_ next_ cell的()函数必须使用比较和交换来标记一个单元已访问,但除了线程创建和连接提供的顺序约束外,无需其他顺序限制。
maze_ find_ any_ next_ cell()的伪代码与清单6.13中所示的完全相同。 ,但是maze_try_visit_cell()的伪代码不同,如清单6.15所示。 第8行 – 9检查是否连接了这些单元,如果没有,则返回失败。循环跨越线路11 – 18 标记新访问的单元格的尝试。第13行 检查是否已经访问过,如果是,则行16 返回失败,但仅在第14行之后 检查我们是否遇到了另一个线程,如果是,则行15 表示已找到解决方案。行19 对新单元格的更新,第20行 和21 更新此线程的访问数组,并行22 返回成功。
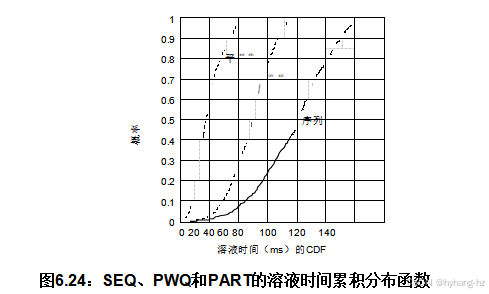
性能测试显示了一个令人惊讶的异常,如图6.24所示。 PART (17毫秒条件)的中位解算时间比SEQ (79毫秒)快4倍以上,尽管它只运行在两个线程上。
对于这种戏剧性的性能异常,首先反应是检查错误,这表明需要进行严格的验证。这是下一节的主题。
大部分验证工作包括一致性检查,可以通过在codeSamples/SMPdesign/maze/*.c中搜索ABORT()来找到这些检查。示例检查包括:
1.迷宫解决方案步骤最终位于迷宫之外。
2.突然出现的行数或列数为零或更少的迷宫。
3.新创建的迷宫,其中包含不可到达的单元格。
4.没有解决方案的迷宫。
5.不连续的母胶溶液。
6.尝试在迷宫外部启动迷宫求解程序。
7.迷宫,其解路径比迷宫中的单元格数量更长。
8.不同线程的子解决方案相互交叉。
9.内存分配失败。
10.系统调用失败。
Paul的妻子对解决谜题非常感兴趣,因此她还进行了额外的手动验证。
然而,如果这个迷宫软件要在生产中使用,无论这意味着什么,明智的做法是构建一个独立的迷宫破解程序。尽管如此,这些迷宫和解法都被证明是相当有效的。因此,下一节将更深入地分析第6.5.2节中提到的可扩展性异常。
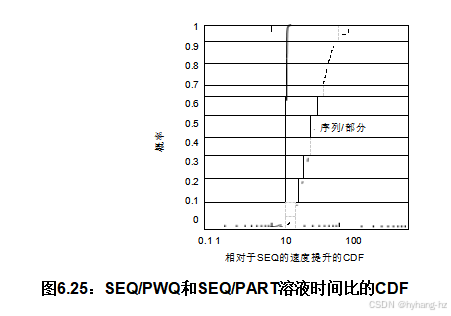
尽管算法实际上是在寻找有效迷宫的有效解,但图6.2中的CDF曲线图4 假设数据点是独立的。但事实并非如此:性能测试随机生成一个迷宫,然后在该迷宫上运行所有求解器。因此,绘制每个生成的迷宫的求解时间比值的累积分布函数是有意义的,如图6.25所示。 大大减少了CDFs的重叠。该图显示,对于某些迷宫,PART的速度比SEQ快四十多倍。相比之下,PWQ的速度从未超过SEQ的两倍。二十线程上的四十倍加速需要解释。毕竟,这不仅仅是令人尴尬的并行性,其中可划分性意味着增加线程不会提高整体计算成本。相反,这是屈辱性的并行性:增加线程显著降低了整体计算成本,从而实现了巨大的算法超线性加速。
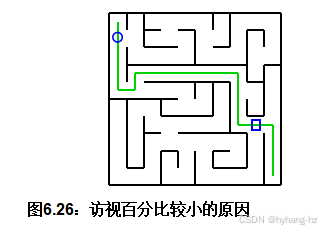
进一步的研究表明,PART有时访问迷宫的细胞少于2%,而SEQ和PWQ从未访问少于9%。这种差异的原因如图6.26所示。 如果从左上角穿过溶液的线到达圆圈,另一条线就无法到达迷宫的右上部分。同样地,如果另一条线到达正方形,第一条线就无法到达迷宫的左下部分。因此,PART很可能只访问一小部分非解路径细胞。简而言之,超线性加速是由于各条线相互干扰所致。这与几十年来并行编程的经验形成了鲜明对比,在这些经验中,程序员们一直在努力避免线之间的干扰。
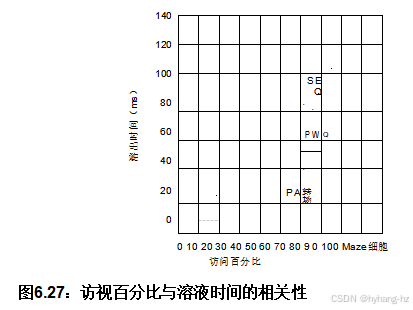
图6.27 确认了所有三种方法中访问的细胞与溶液时间之间存在强烈的相关性。PART的散点图斜率小于SEQ,表明PART的双线程访问给定比例的迷宫速度比canSEQ的单线程更快。PART的散点图还偏向于较小的访问百分比,证实了PART总的工作量较少,因此观察到了令人尴尬的并行性。这种令人尴尬的并行性还提供了超过两倍的速度提升,如第113页所述。
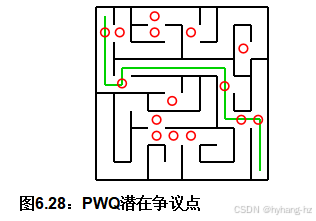
PWQ访问的细胞比例与SEQ相似,而且即使在相同的访问比例下,PWQ的解的时间也比PART长。原因如图6.28所示。 每个拥有超过两个邻居的单元格都有一个红色圆圈。由于每个这样的单元格可能导致PWQ中的竞争,因为一个线程可以进入但只有两个线程可以退出,这会损害性能,正如本章前面所提到的。相比之下,PART可以在找到解决方案时发生一次这样的竞争。当然,SEQ从不发生竞争。

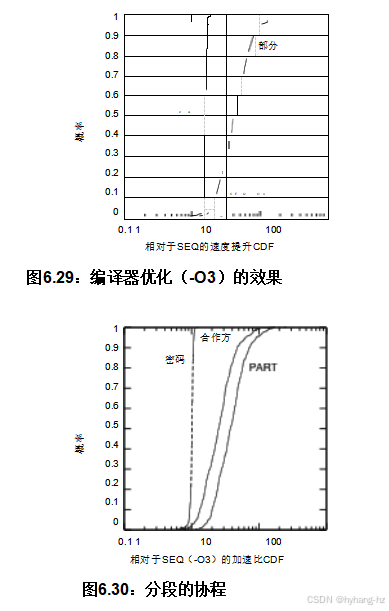
尽管PART的加速效果令人印象深刻,但我们不应忽视顺序优化。图6.29 表明,当使用-O3编译SEQ时,其速度大约是未优化PWQ的两倍,接近未优化PART的性能。用-O3编译所有三种算法的结果与图6.25所示的结果相似(尽管比图6.25所示的结果快)。 ,除了PWQ提供的加速几乎与SEQ相比没有区别,这符合Amdahl定律[Amd67]。然而,如果目标是将性能提高到未优化SEQ的两倍,而不是达到最优性,编译器优化就非常有吸引力。
缓存对齐和填充通常通过减少虚假共享来提高性能。然而,对于这些迷宫解决方案算法,对迷宫单元数组进行对齐和填充会导致性能下降,对于1000x1000的迷宫,性能可下降高达42 %。缓存局部性比避免虚假共享更重要,特别是对于大型迷宫。对于较小的20x20
或者50×50迷宫,对齐和填充可以为PART带来高达40%的性能改进,但对于这些小尺寸,SEQ无论如何都表现更好,因为PART没有足够的时间来弥补线程创建和销毁的开销。
简而言之,分区并行迷宫求解器是一种有趣的算法超线性加速的实例。如果“算法超线性加速”引起认知失调,请继续阅读下一节。
算法的超线性加速表明,可以采用并行处理方法,例如在清单6.14的main do-while循环中,通过手动在各个线程之间切换上下文。 这种上下文切换是直接的,因为上下文仅由变量c和vi组成:在实现该效果的众多方法中,这是上下文切换开销与访问百分比之间的一个很好的折衷。如图6.30所示 ,这个协程算法(COPART)非常有效,在一个线程上的性能大约是两个线程(maze_2seq.c)的PA RT的30 %。
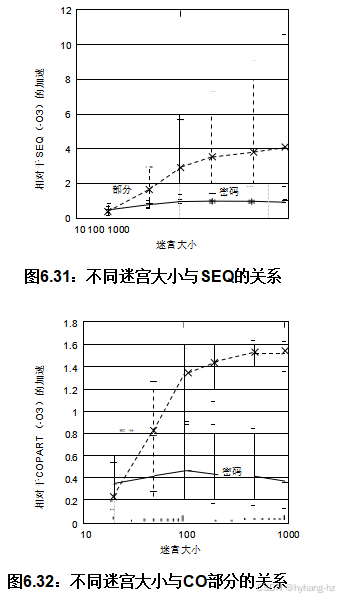
图6.31 和6.32 展示了不同迷宫大小的影响,比较了PWQ和PART在两个线程上分别与SEQ或COPART的性能,误差范围为90%置信区间。PART在100×100及更大迷宫中表现出优于线性的扩展性,而对COPART的扩展性则较为温和。PART在大约200×200迷宫规模时,能量效率超过了COPART,因为高频情况下功率消耗大致与频率的平方成正比[Mud01],因此在两个线程上1.4倍的扩展可以消耗与单个线程相同能量且解速度相等。相比之下,除非未优化,否则PWQ对SEQ和COPART的扩展性较差:图6.31 和6.32 使用-O3生成。
图6.33 展示了PWQ和PART相对于COPART的性能。对于PART运行超过两个线程的情况,额外的线程均匀分布在连接起始和结束单元格的对角线上。简化了链路状态路由[BG87]用于检测PART运行超过两个线程时的提前终止(当一个线程同时连接到起始和结束时,该解决方案会被标记)。PWQ表现较差,但PART在两个线程时达到盈亏平衡,在五个线程时再次达到盈亏平衡,并且超过五个线程后实现了适度的加速。理论上的能量效率盈亏平衡在七个和八个线程的情况下处于90%的置信区间内。
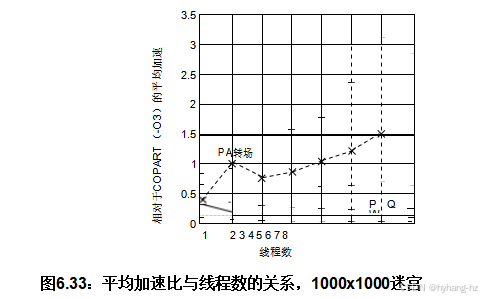
两线程峰值的原因是(1)两线程情况下终止检测的复杂度较低,以及(2)第三及后续线程向前推进的概率较低:只有前两条线程能保证从解线上开始。这与图6.32中的结果相比,表现较差。 这是由于运行在2.66 GHz的更大、更老的Xeon系统中可用的硬件集成度较低。

未来的工作还有很多。首先,本节仅应用了人类迷宫求解者使用的一种技术。其他方法包括跟随墙壁以排除迷宫的部分区域,以及根据先前路径的位置选择内部起点。其次,不同的起点和终点选择可能有利于不同的算法。第三,尽管PART算法的前两个线程放置较为简单,但剩余线程的放置方案却多种多样。最优放置可能取决于起点和终点。第四,研究无法解决的迷宫和循环迷宫可能会产生有趣的结果。第五,轻量级C++11原子操作可能会提高性能。第六,比较三维迷宫(或更高阶迷宫)的速度提升会很有趣。最后,对于迷宫而言,令人尴尬的并行性表明使用协程可以实现更高效的顺序执行。令人尴尬的并行算法是否总是导致更高效的顺序实现,还是存在本质上并行的算法,其中协程上下文切换开销超过了速度提升?
本文对迷宫解算法的并行化进行了演示和分析。传统的基于工作队列的算法只有在禁用编译器优化时才能得到很好的效果,这表明使用高级语言/开销语言获得的一些先前结果将被优化技术的进步所否定。
本节给出了一个清晰的例子,说明将并行性作为一级优化技术而非顺序算法的派生,为改进顺序算法铺平了道路。并行性的高级设计时应用很可能是研究的一个富有成果的领域。本节讨论了解决迷宫问题,从轻微可扩展到令人尴尬的并行化,再回到原点。希望这次经历能够激发人们将并行化作为一级设计时的整体应用优化技术来研究,而不是将其视为事后微优化,仅用于现有程序的修补。
知识没有价值,除非你把它付诸实践。
安东·契诃夫
最重要的是,尽管本章已经证明了在设计层面应用并行性可以取得优异的结果,但这一节表明这还不够。对于迷宫解决方案等搜索问题,本节显示搜索策略比并行设计更为重要。是的,对于这种特定类型的迷宫,智能地应用并行性确实找到了更优的搜索策略,但这类幸运并不能替代对搜索策略本身的明确关注。
正如在第2 .2节中所指出的,并行性只是众多优化方法中的一种。一个成功的系统设计需要关注最重要的优化。尽管我可能希望声称不然,但这种优化可能是并行性的,也可能不是。
但是,对于许多情况,如果并行处理是正确的优化方法,下一节将介绍同步工作马——锁定。


















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









